Hi,
I want to extract the table from multiple pdf files and write it to excel. The first page of the pdf contains some text and from 2nd page onwards the table, while in some pdfs the table starts from page one itself. The issue is that from all the records present in the table some records are not extracted i.e. from 6000 rows only 4000 rows are extracted rest are omitted. What can be done to get all the present records? Can anyone guide me with this. For different pdfs the column orders can be different and also extra column can also be there. I can’t seem to find standard solution for this.
What approach have you taken? Can you post your workflow and/or the pdfs? What’s your desired outcome?
I’ve had great success extracting tables with thousands of rows from multi-page pdfs, containing preamble text on the first page and other information like footnotes, using the Tika Parser node in combination with manipulation nodes like the Row Filter, Transpose, Cell Splitter, Regex Extractor, and String Manipulation nodes.
I have used Tika Parser node to read all the pdf files present in a folder, followed by cell splitter for splitting cell by \n-new line as delimiter, filtering nodes to filter out blank columns and rows. And than regex split for splitting rows into column. First column contains Serial number-numerical format, Second column contains alphanumeric values where the value starts with U followed by number and than mixed characters with the specific length of 24 characters. And last column should contain words i.e. names only characters no numbers.
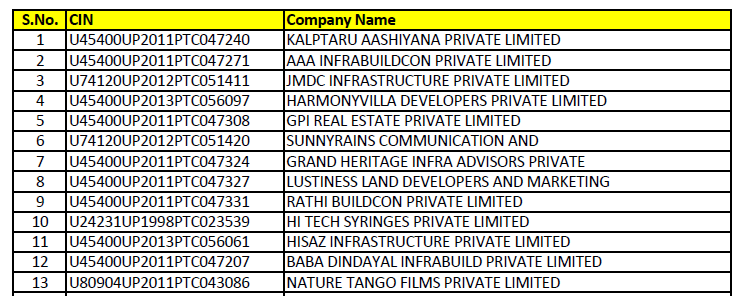
I want the S/N, CIN, & Company name from these.
Sample pdf screen shots attached here with different table format and number of column are attached herewith:



@shivani_soni you could try and use the R package tabulizer. Maybe you could provide us with an example.
How to install R: KNIME guide and collection.
Can we solve this without using any external libraries or packages i.e. R tabulizer package or tabula library of java? Plus there are some errors in recognizing the characters in the data parsed by the tikka parser for example for some of the entries in the column CIN number letters such as M is recognized as 1V1, J as 1 or /, H as 1-1 etc. What can be done for such cases?
@shivani_soni there was an example and a discussion doing this with just KNIME nodes. But I think I was not able to use that whith the example I have cited. Maybe you could give it a try or provide us with an example:
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.