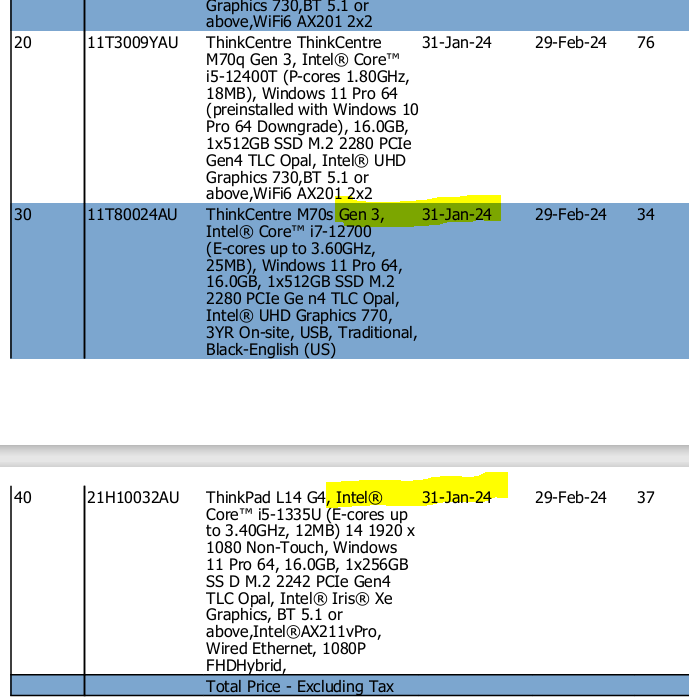
Hi, I have a sample PDF file from which I need to extract tables into an Excel spreadsheet. I’ve started by extracting the first table using the sample workflows I’ve seen here in the forum, but I’m experiencing some problems. I don’t know how to separate the “Date” values from “Gen, G4 and 3, Intel” into separate columns. They should be in separate columns and not combined.
I would appreciate any help or guidance on how to correctly extract the table.
Hi, Can you maybe make a “What you expect” vs “What you get” ?
In your KNIME table all the dates are in single cells so I don’t understand what you want differently.
Hi your output looks like they are in separate columns after the cell splitter.
Based on the text I would probably rather think regex would be helpful to get info in the same columns
br
Hi @Daniel_Weikert sorry if its not clear , yes they are in the separate columns but the Date values and text values should not be in the same column because the text is part of the product description, should be like this:
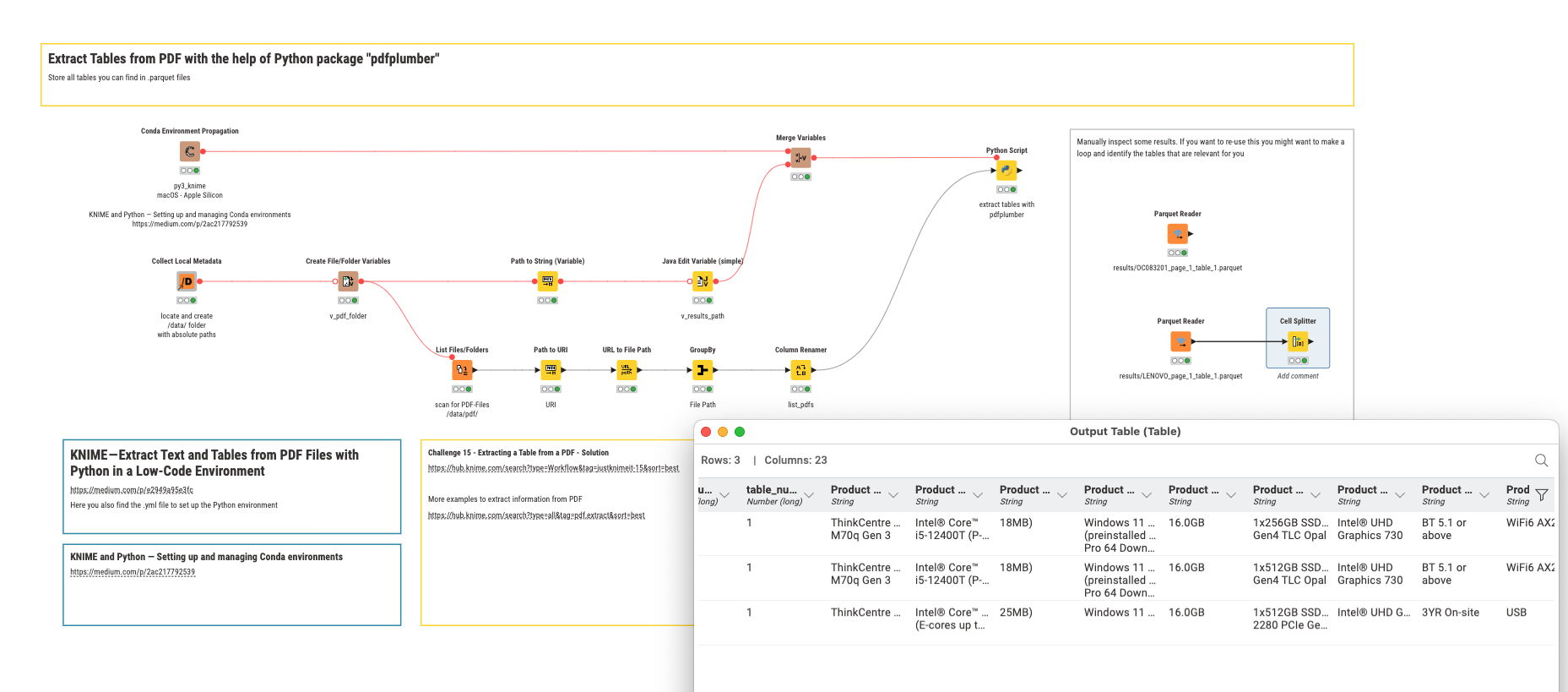
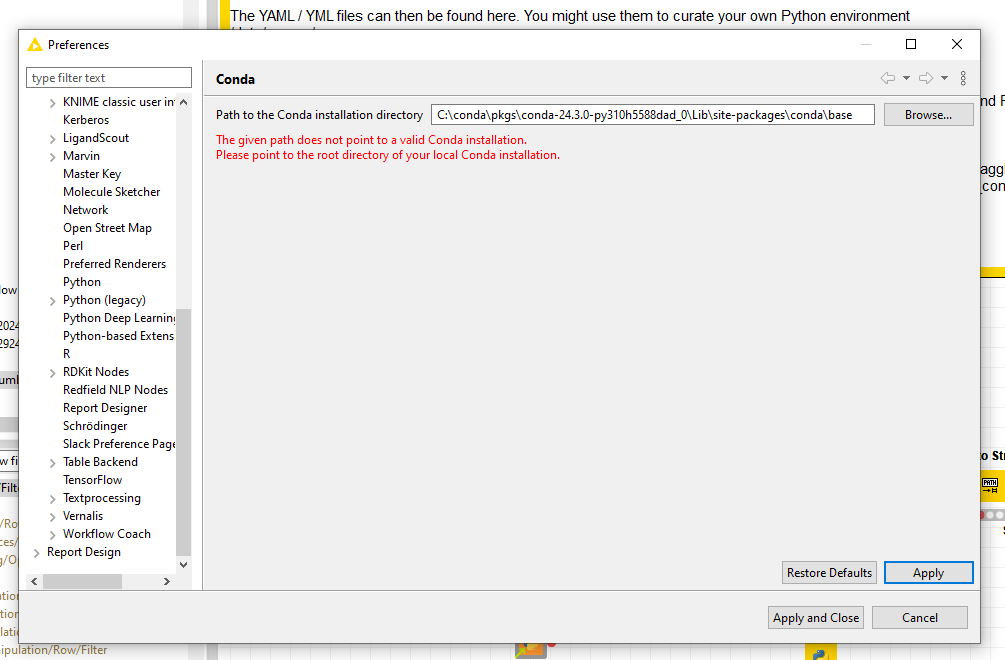
Hi @mlauber71 thank you for this, im actually trying your workflow but I can’t seem to intall the path conda directory in the knime. I already have the conda installed. I’m using windows 11.
sorry for this question, I don’t code and have limited knowledge in this type of approach will look it more in the future if I can advance my workflow knowledge
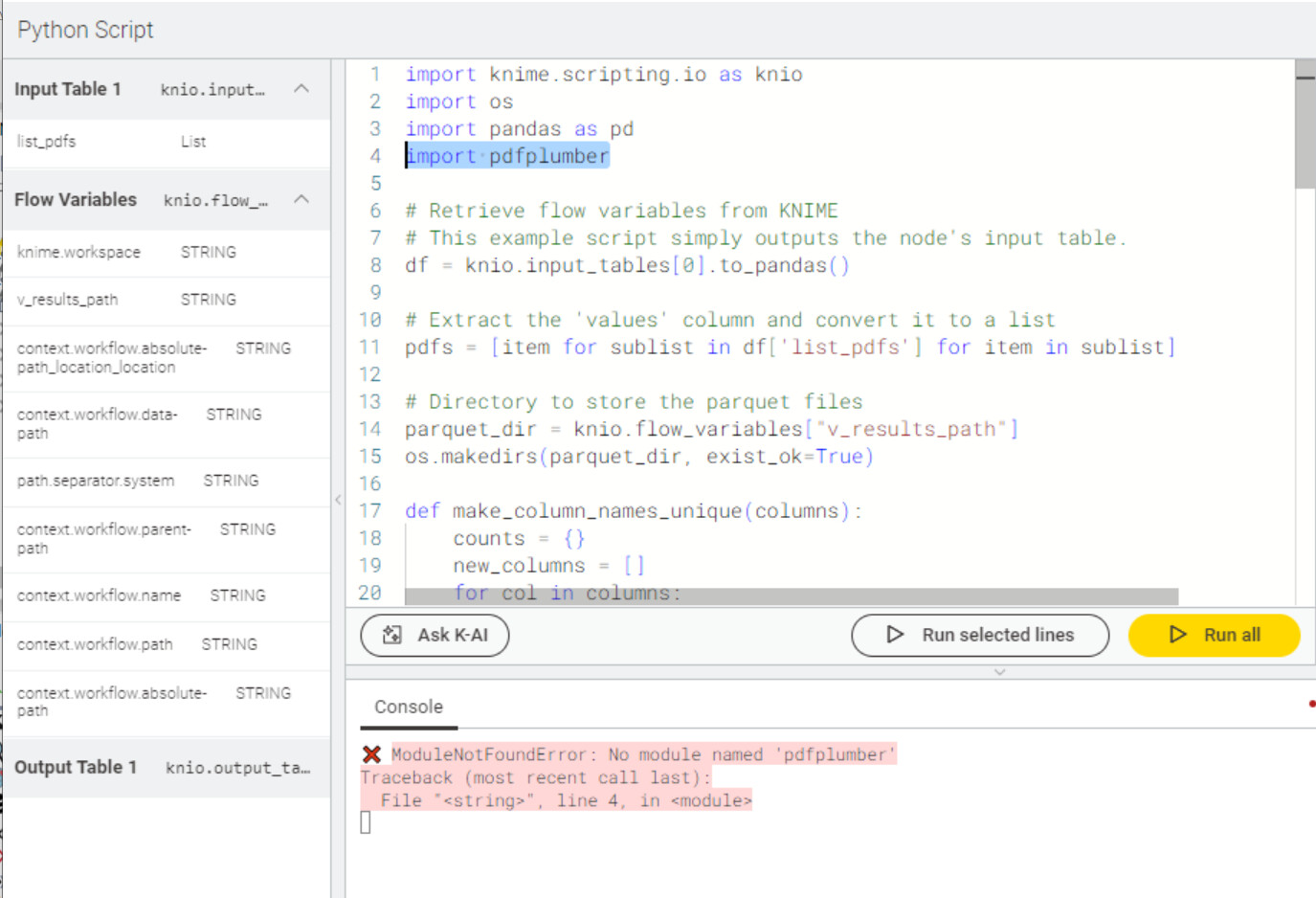
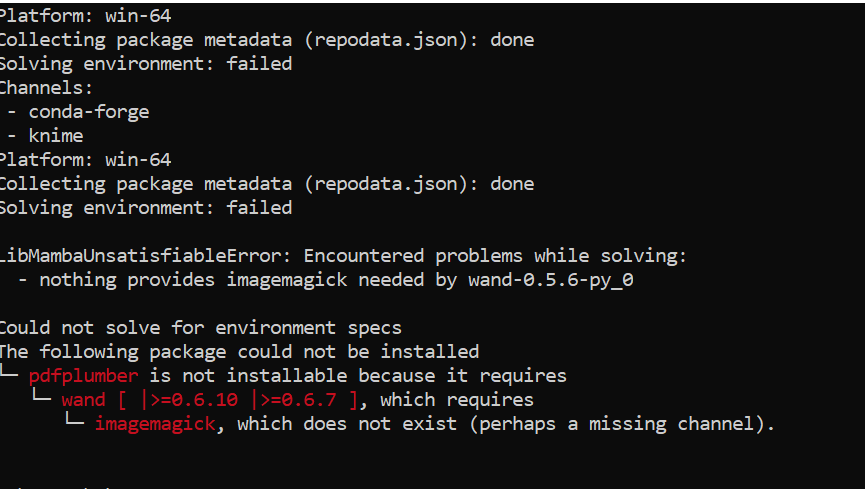
should I edit my py39_yaml file and paste this so that I can get the pdf plumber in the python library? or just input this in the prompt one by one (will start with the 3rd line)? because I just followed the activation of py39 and did not include this.
Update: It already works, I already used the workflow. I just get the imagemagick here: https://anaconda.org/conda-forge/imagemagick/files install and create and environment base on your blog. Thank you again for your help!
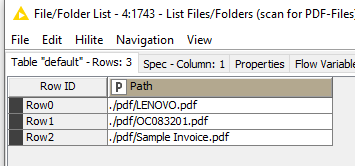
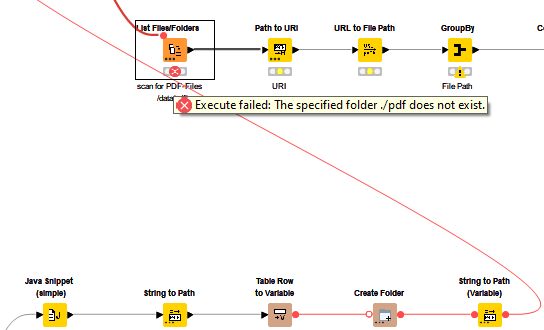
I’m trying to explore the workflow and change the files but its not working, it just work with The list files/folders reads 3 files from the samples you imported.
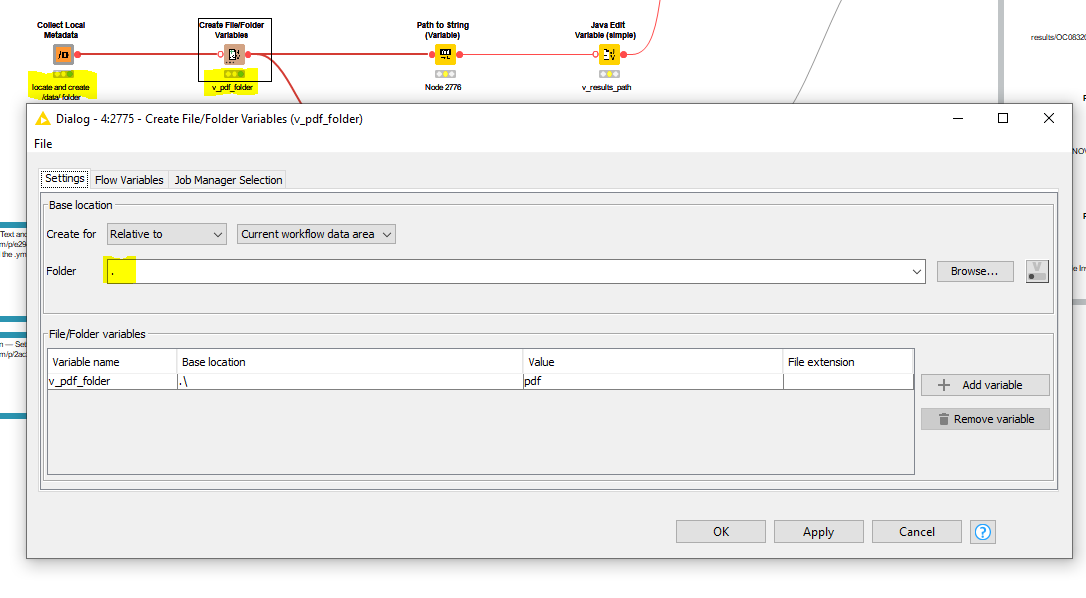
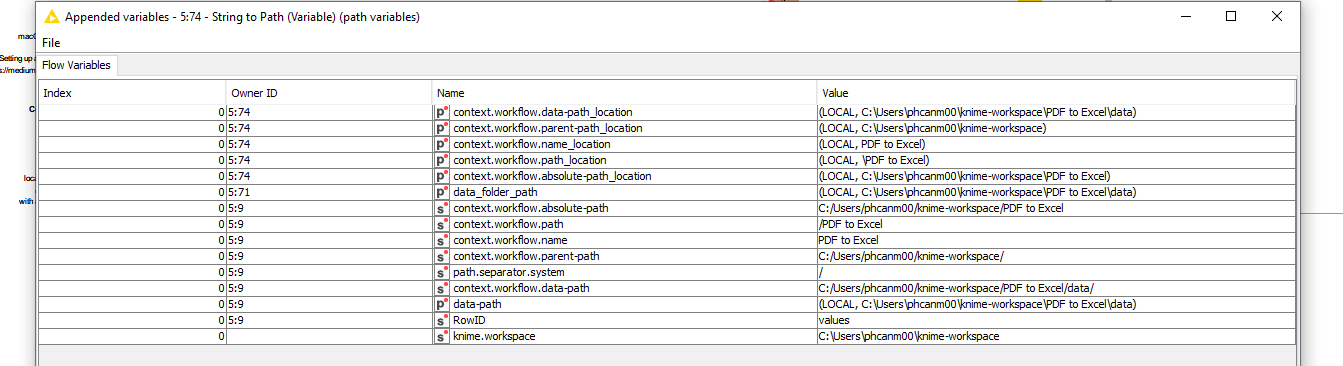
I want to change this v_pdf_folder path so that in the list file/folder it will read it, im just confused how to configurate the collect local metadata so that it will connect correctly to the create file/folder node, this is my output for collect local metadata:
@Heldyyyyy in short paths can be created like this. You could remove unwanted files from the folder. Also the list files node has the option to filter by name or you could remove unwanted rows later
If you want the full story of knime path there is the lengthy but very useful: