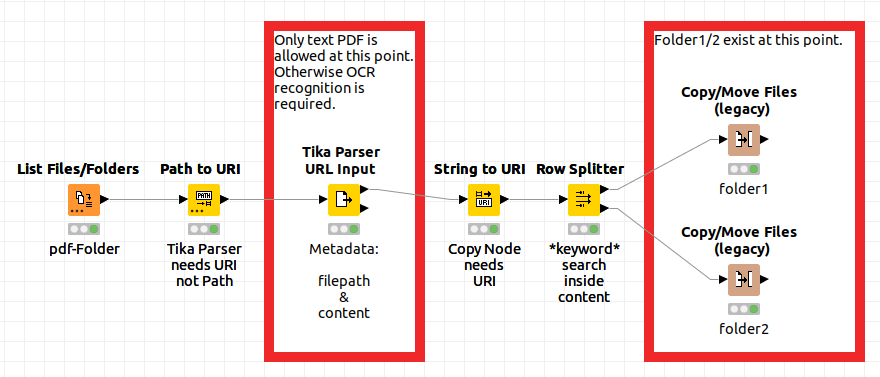
I have 100 pdf file in that I need to search for a specify word. If the word is found in the pdf then I need to transfer that pdf to folder1, if that word is not found in pdf then it must be transferred to folder 2.
How can this be done in knime. Can someone share the sample workflow .
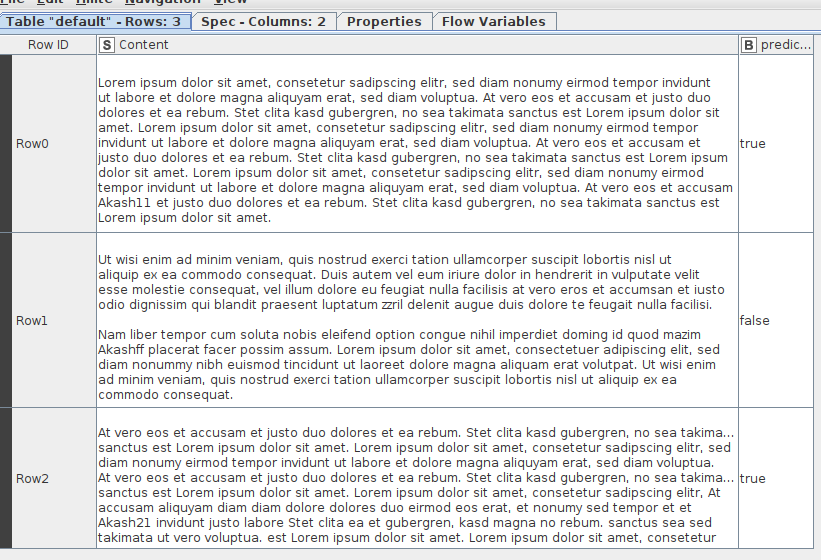
For my workflow, I used 3 sample pdf files, and I am searching for the word “text”. Only 1 file has the word “text”, so this file will go in my folder 1, and the other 2 files will go in my folder 2.
Tika Parser URL Input:
This is more of a comment about the Tika Parser URL Input. Is there any reason why it removes all the columns coming from the input?
Though it does return a FilePath as string, I want to keep my original path in my case, since I am pointing to a relative path, and what if I don’t necessarily want to publish the full path (absolute path) in the workflow?
I did a workaround by joining back the input and output of the Tika Parser URL Input node, but I should not have to do this. And what if I had other columns such as a flag, or an ID, or a relation column that determined which file belongs to which client data for example? Knime should not remove these columns. We can remove which ever columns on our own via the Column Filter.
Copy/Move Files vs Transfer Files:
My understanding is that the Copy/Move Files node has become legacy, and we’re supposed to move (no pun intended) towards the Transfer Files node instead.
One thing that I found useful with Copy/Move Files is that it can read the source and destination columns from a table, and therefore we don’t need to loop to move several files.
With the Transfer Files node, we can’t really do that. We have to use loops to move several files.
I’m using the Transfer Files over the Copy/Move Files to avoid using legacy nodes, but I’m stuck with having to use a loop.
Thank you for the above workflow.I have 2 more problem.
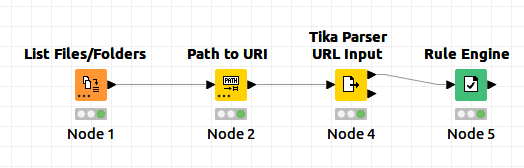
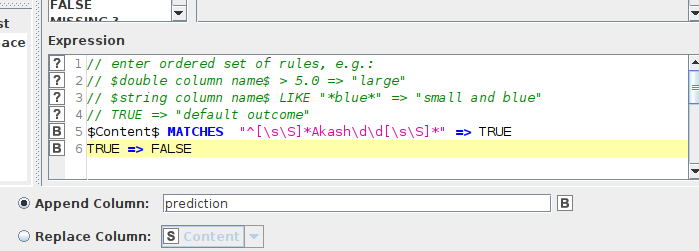
1.i want to find the word in PDF “AKASH123” i dont want to find “AKASH”.Only the PDF which has “AKASH123” has to be moved to folder 1.How do we configure in rule engine.in a PDF both AKASH and AKASH123 is there.
2.I need to take the most recent pdf files in the folder.
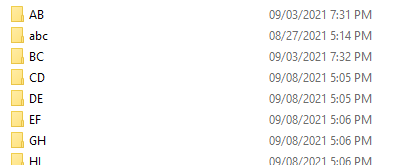
Eg. Folder 001>AB,BC,CD,DE,12,13,14
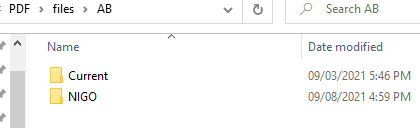
Folder AB> Current> most recent file
I want to pull the file from AB,BC and CD folder inside that current folder ,in current folder i need only most recent pdf files only.how do we do that
Thank you for the above workflow.I have 2 more problem.
1.i want to find the word in PDF “AKASH123” i dont want to find “AKASH”.Only the PDF which has “AKASH123” has to be moved to folder 1.How do we configure in rule engine.in a PDF both AKASH and AKASH123 is there.
2.I need to take the most recent pdf files in the folder.
Eg. Folder 001>AB,BC,CD,DE,12,13,14
Folder AB> Current> most recent file
I want to pull the file from AB,BC and CD folder inside that current folder ,in current folder i need only most recent pdf files only.how do we do that
For your 1st problem:
You should provide what you currently have in your Rule Engine to understand your current logic and how to add the new rule with your current logic, or at least to keep everything clean. Without seeing this information, you always add AND NOT ($YourColumn$ LIKE "*/AKASH.pdf") which would exclude file with name “AKASH.pdf”.
For your 2nd problem:
Please check out the node Files/Folders Meta Info
Point it to your Path column, and it will give you all the meta info of the files, including their creation and last modified timestamp, which you can use to determine the most recent file.
I have to find the word “AKASH12” from the file.But the pdf file also contains “AKASHMC”. Currently in the rule engine i have provide
$Content$ LIKE “* AKASH *” this is giving me both “AKASH12” and “AKASHMC”.
i want to search for the word AKASH with 2 digits number with it eg AKASH12, AKASH23, AKASH34 etc.
i dont need AKASHPH,AKASHVG,AKASHHJ etc
PDF workflow.xml (3.0 MB)
As i mentioned above i want to find the specific words in PDF as such(TEXT12,TEXT13,TEXT14,TEXT15,TEXT16).but the PDf also has words like (TEXTAB,TEXTBC,TEXTSD,TEXTMN).
i tried using LIKE TEXT this is find both the word TEXT12 and TEXTAB.i want a rule so that i find only TEXT12(The word text and numerical 2 values with it).How could this be done.Any quick suggestion. please refer attached workflow.
What you just mentioned are 1 rule + an exception.
The problem with going that route is that we can provide you a solution for this, but without know what the other rules/exceptions are, it can interfere with the other rules/exceptions.
Just like when you came with this:
Some solution was suggested, and then you come back with more rules/exceptions.
As I said, in order to provide the proper solution, we need to know what are your other rules/exceptions, or we will end up giving you something that will work for this, but not for that, and we’ll go in a series of back-and-forth.
Now I need to pick the most recent pdf files from the folder.
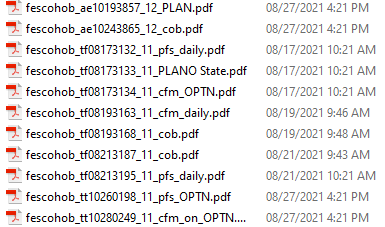
FOLDER 001 > AB,BC,CD,DE,EF(Inside all these folder there is “current” folder. In Current folder we have more than 70,000 pdf. I need only the file which is created one or two days back. How this can be done.
*We cannot get all the pdf into KNIME and sort by date modified as few folders have more than 90,000 files.
1.How can we pick up only the recent files(one/two days prior).It must be done everyday so dates keep changing.
2.Can we Automate this like-Whenever there is a new pdf in any of the current folder workflow must verify the PDF?
Folder AB> Current
Current > more than 70,000 pdf files(I need review only most recent pdf files one /two days back)This has to be done everyday.
Hi @Akash_M_C , just use the List Files/Folders node which will return the path of the files in a table. Then use the Files/Folders Meta Info node which will give you the created date and the last modified date of each of the files.
You can then sort descending on the last modified date, and filter in the first row via Row Filter.
Hi @Andrew_Steel ,
I tried the below work flow. Unable to find out how to get the file which are most recent (one or two days prior) Can you please provide me a workflow for that. Filtering most recent files.json (7.8 KB)
that’s nice, a KNIME-workflow in JSON Format. But I can’t Import this workflow format. Could you publish your exported workflow (knwf-Format) with embedded data?