Hi Knime Community, I have this type of PDF table where the value from one cell has 2 or more rows (it’s like a value that is in a merged cell). I did try the workflows that I found here (Thank you to the members who are kind enough to share their initial workflows) like the use of tika parser node to read the pdf file then use the cell splitter to split the contents and divide by columns, etc… Here’s my scenario:
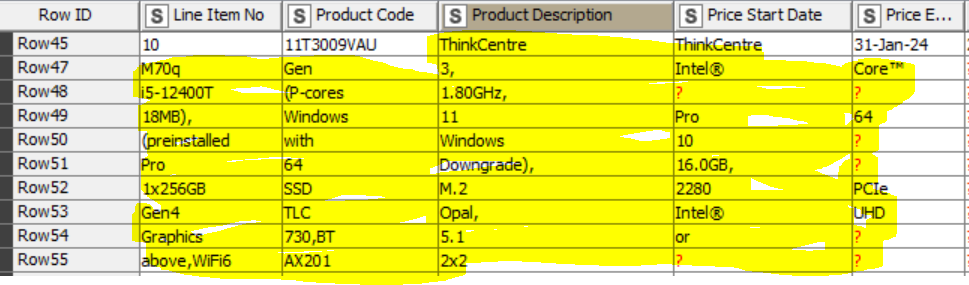
Sample Data header and cell value that uses 2 or more rows but combine as one (merge):
Scenario 1 that I try:
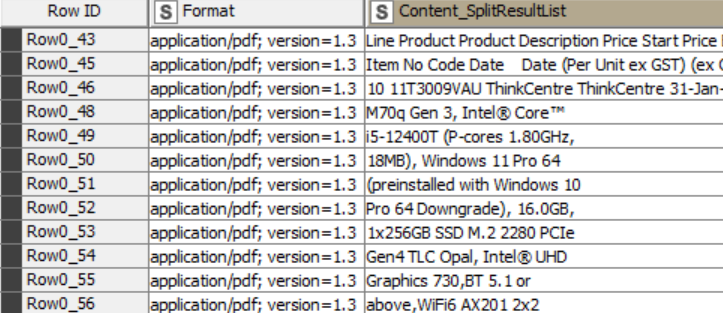
After using tika parser, cell splitter and transpose node; the value in the Product description wherein it uses many rows (merge) picks up by knime by row. I’m thinking of combining the column for Product Description + Price Start Date into one column, but how can I move the description that is in left columns?
Scenario 2 that I try:
Tika parser - cell splitter content - ungroup then group by; it reads all the line in one row, How can I split the specific values per column (I suppose will use splitter and some type of pattern/numbering matching but I don’t know how will it pick up the other’s, it was my guess )
Im thinking of combining the columns with a specific row iteration because the pattern is for every 1-9 rows or for every missing column ( like group them) Im just not sure how to execute this one.
converting PDF to well structured tables is always a gamble. Despite PDFs being some sort of XML, the data written can be vastly different. Do you mind sharing some sample data so the community / I can have try providing you a solution or at least a starting point please?
Hi @mwiegand thank you for replying, this is my current workflow after 2 days of working on it , what I did is to get the table first and try to fix it to convert into a excel table. What I currently did is seperate the 1st row of Line item number and Product code then transpose to columns then merge the columns and I added loop variable so that it can read the row transformation from top do bottom. I’m still unsure on what to do next, and I’m trying to figure it out.
@Heldyyyyy without having had a chance to look at your workflow one option could be to split the text with Regex by comma when this comma is not enclosed in brackets.
Then if not all cells do have the same order of (future) columns you could try and have a hierarchy of key words to identify columns like Item, BT, Wifi and so on.
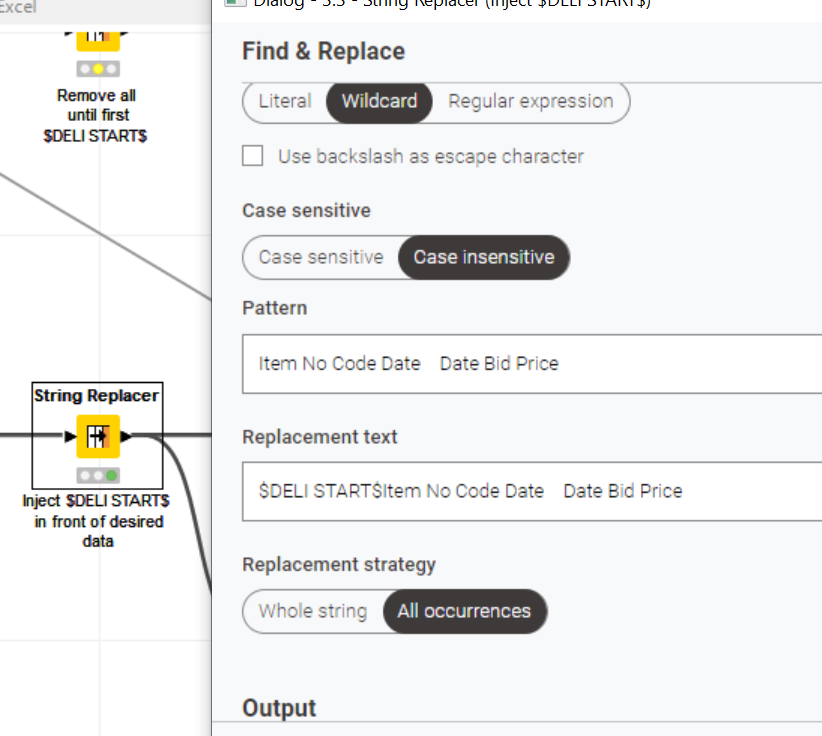
PS: I could have used loops but to illustrate the process I felt the less abstraction there is, the easier it is to understand, play with and learn from it.
Thank you for this, I somehow get the idea in order to break it down it should have like a marker, I’m just a little confuse with what does “Deli starts” do. I mean I check the node but I did not see the function of the deli start?