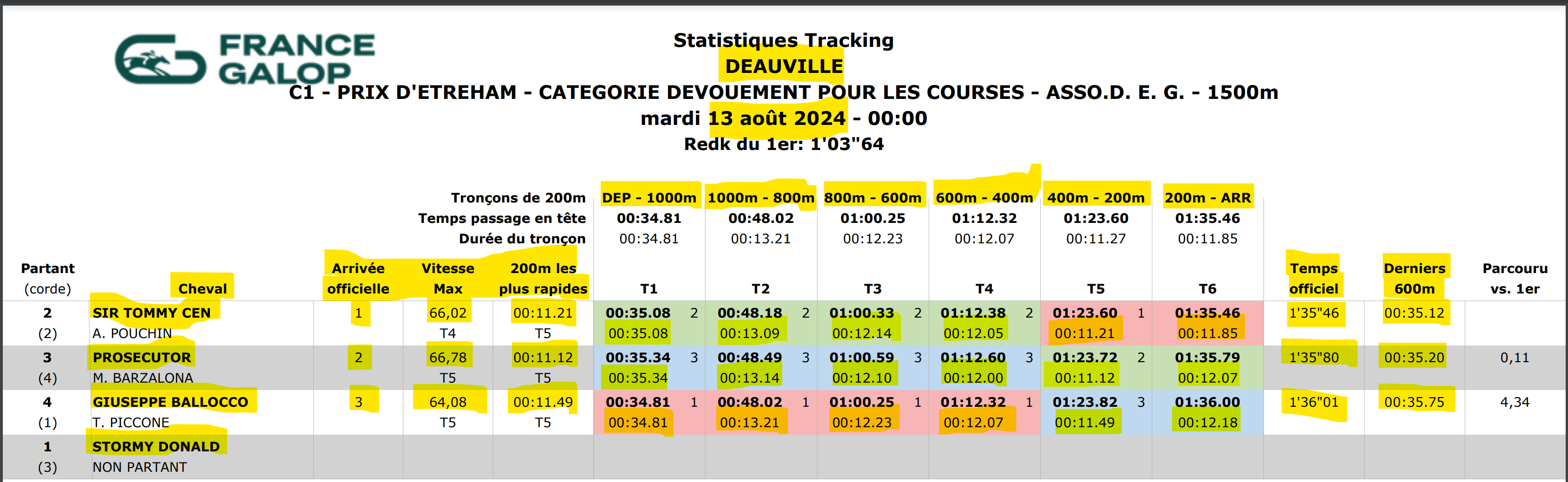
The idea is to end up with a table like this : TABLEAU FINAL.xlsx (8.5 KB)
My plan is, of course, to use TIKA PARSER or PDF PARSER, but the problem starts afterward. If anyone can help…
Thanks
Br
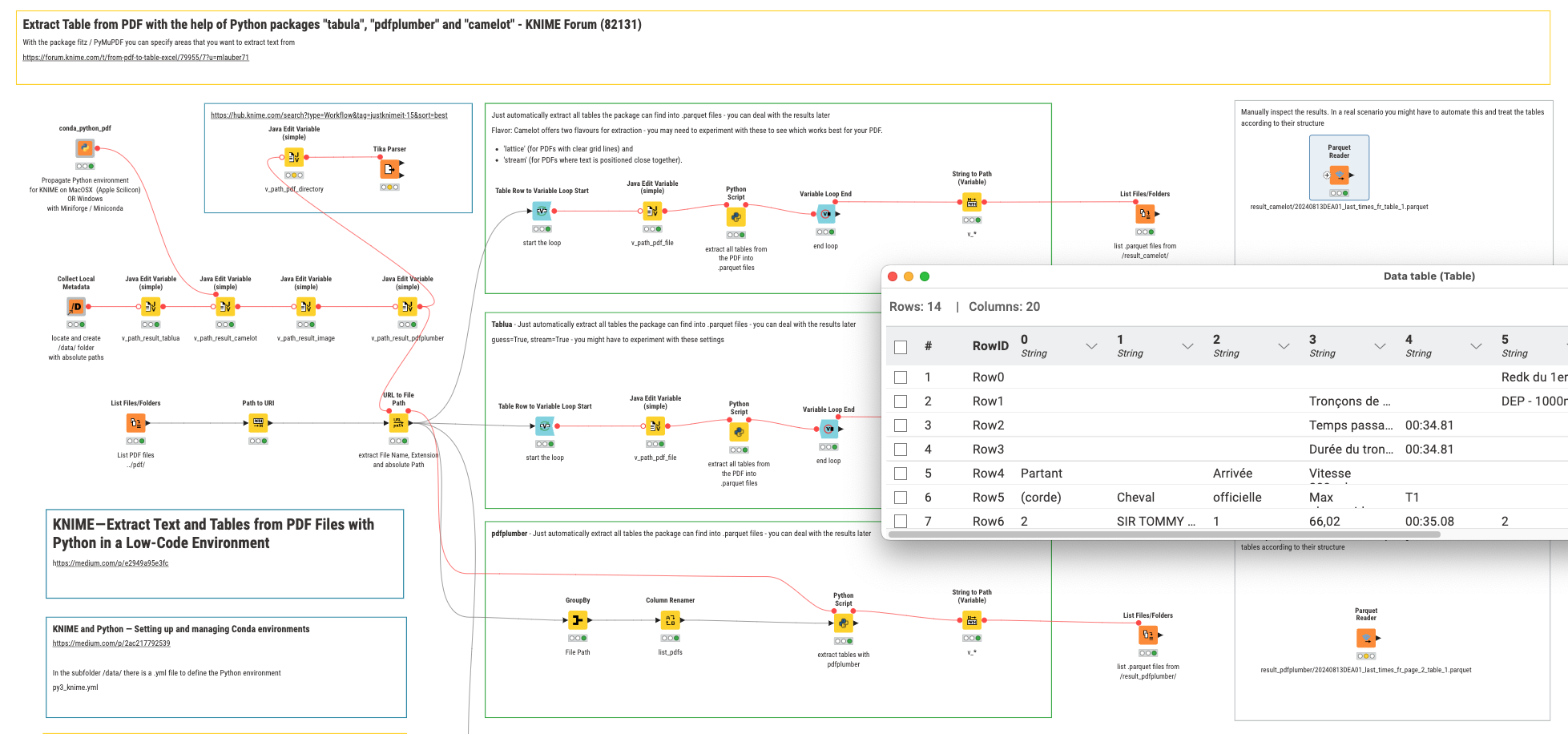
@Brain you can take a look at this example and try to manipulate it. Three approaches with Tabula, Camelot and PDFPlumber extract tables from your PDF file
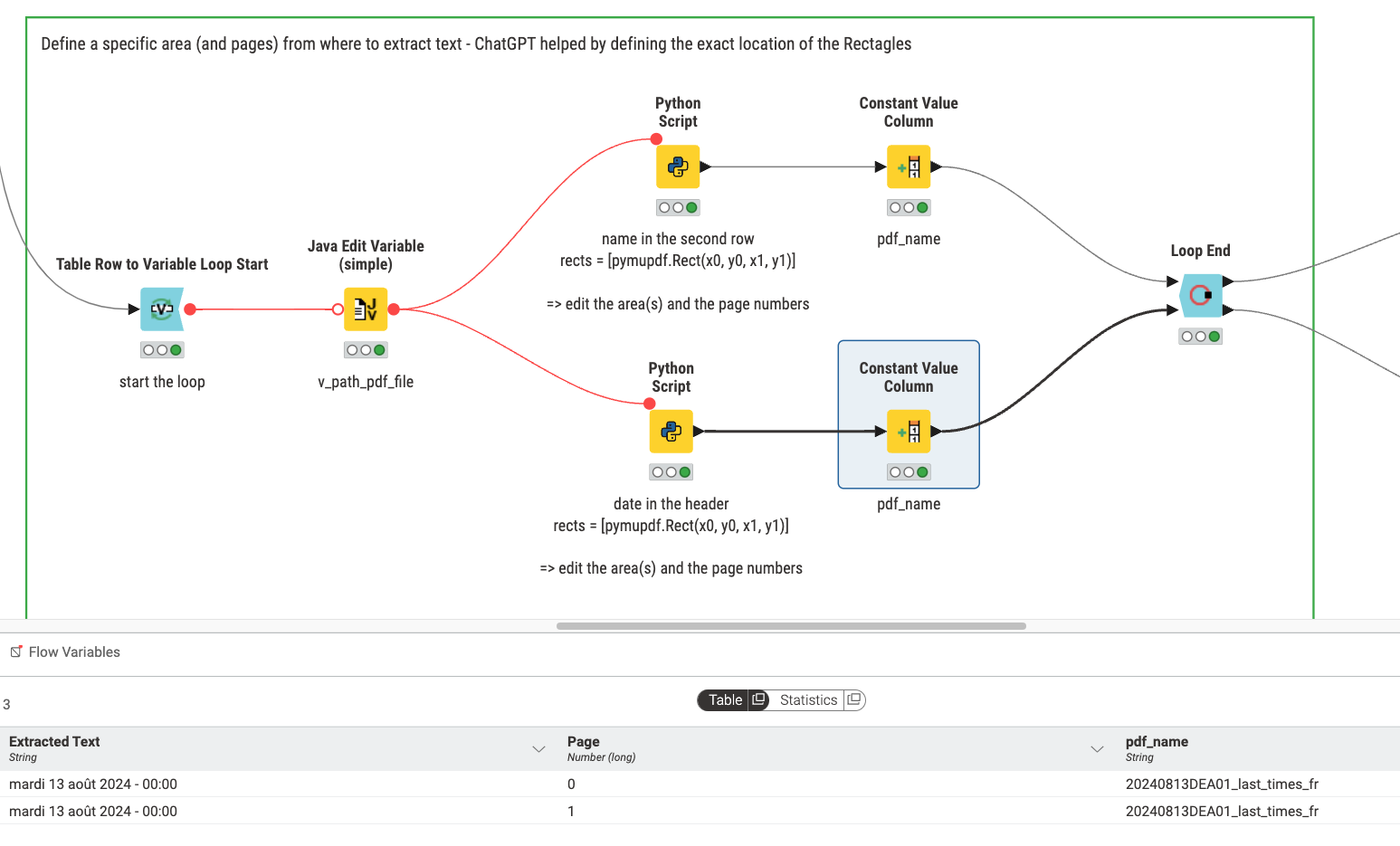
With the help of PyMuPDF you can extract individual areas of your pdf file so to get the headline and the date. You will have to define the areas so as to capture enough of the text but no unwanted context.
You will have to do some cleaning up and combining and also you could try and use several results to see if they agree on the outcome and only use them or something similar.
The Tika Parser is used to demonstrate how to extract a ll the images that are contained in the PDF - just to see if it works …
More on the logic behind the packages in this article:
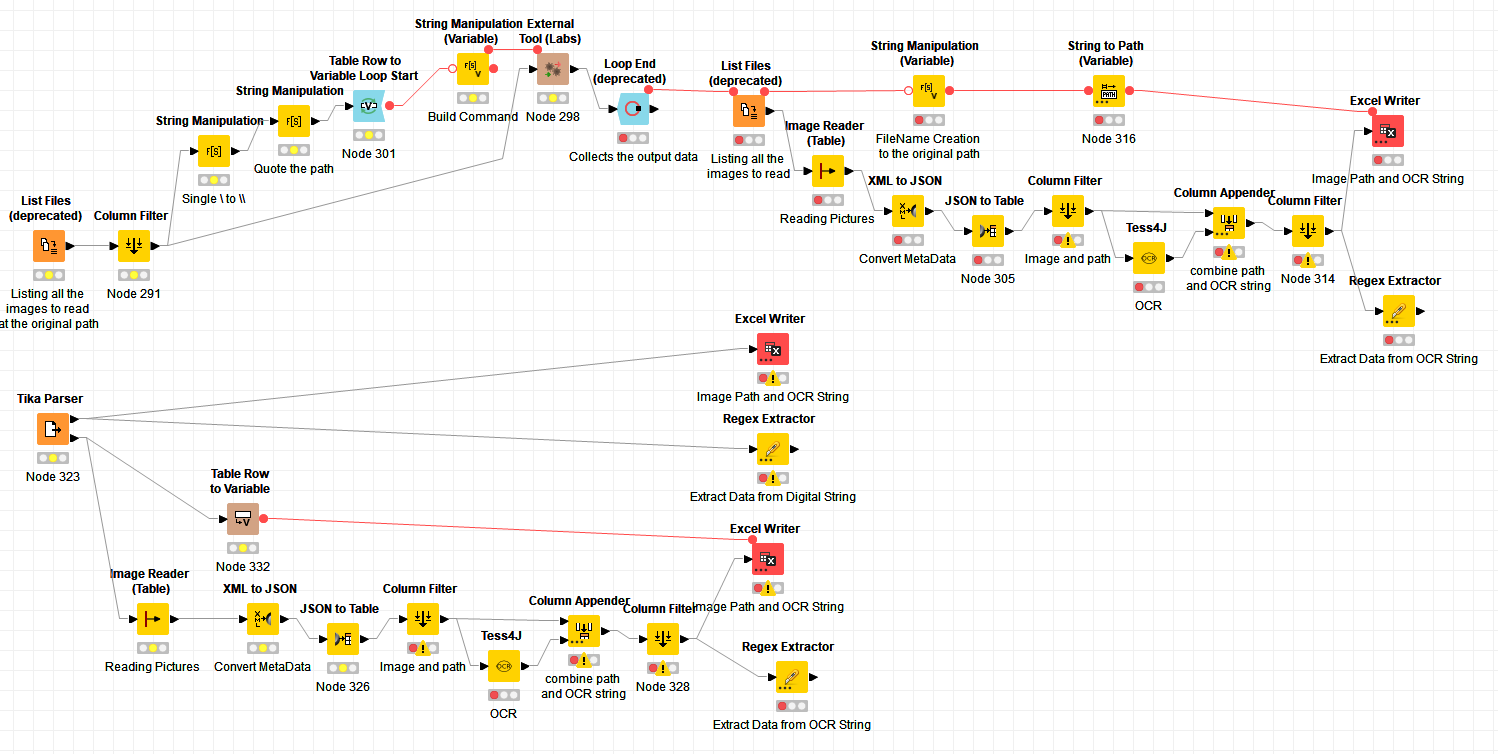
If the PDF files are not digital you can use “Tikka node” to extract embedded pictures into a folder (if these pictures are known by Tikka othewise you can use poppler to split PDF files into pictures with the “external Tools node” to poppler) and use “Tess4J node” to do OCR in each pocture and get digital content.
I downloaded the workflow as well as MINIFORGE. On the PYTHON Script node, I keep getting the error NO MODULE NAMED ect
Do I need to download packages like Camelot, Tabula, etc., somewhere?
Thanks for your help
Br
@Brain you will have to install the necessary packages following the yaml file in the /data/ subfolder and the instructions in the article. I was not yet able to adapt the conda node to windows also as I would normally do. Might take a few days.