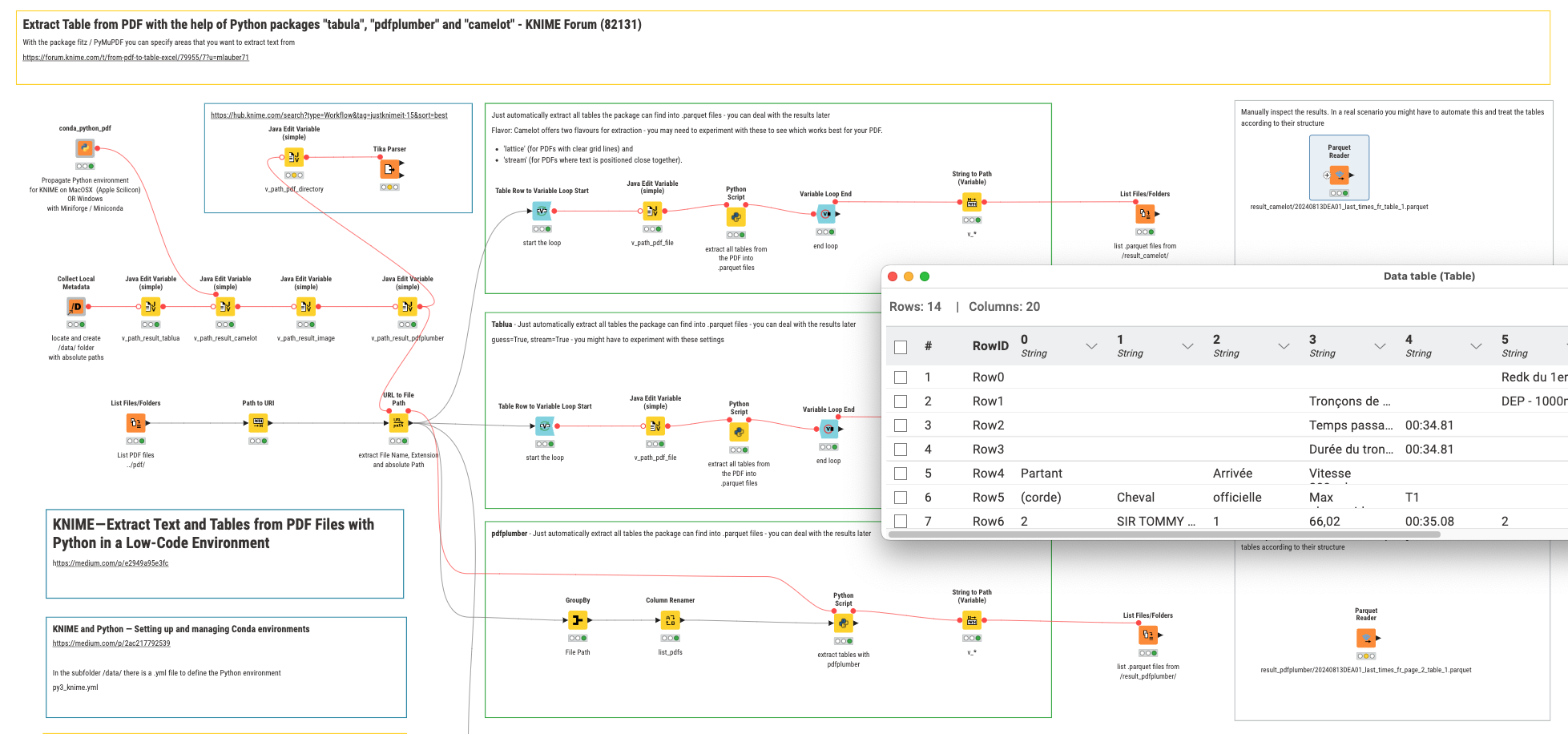
@Brain you can take a look at this example and try to manipulate it. Three approaches with Tabula, Camelot and PDFPlumber extract tables from your PDF file
With the help of PyMuPDF you can extract individual areas of your pdf file so to get the headline and the date. You will have to define the areas so as to capture enough of the text but no unwanted context.
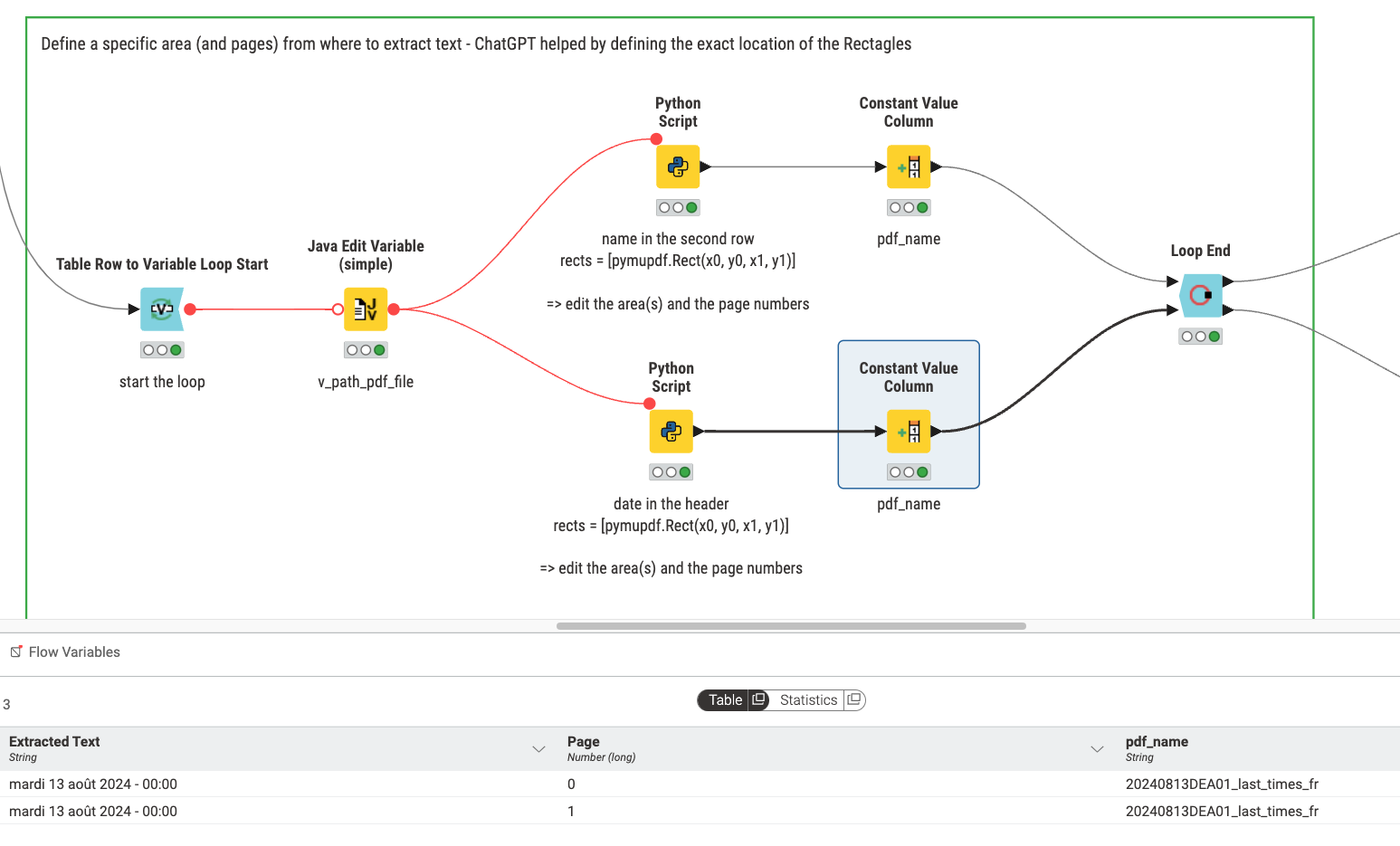
You will have to do some cleaning up and combining and also you could try and use several results to see if they agree on the outcome and only use them or something similar.
The Tika Parser is used to demonstrate how to extract a ll the images that are contained in the PDF - just to see if it works …
More on the logic behind the packages in this article: