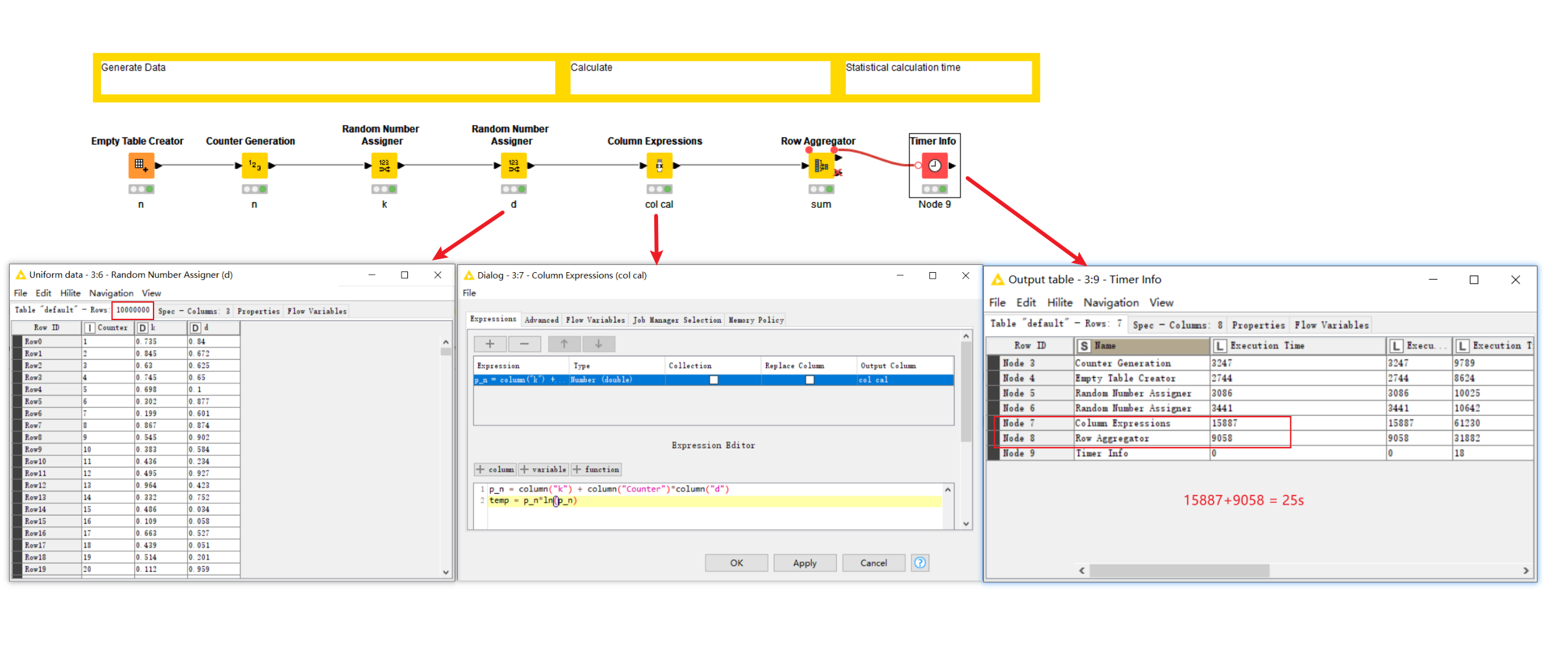
We need to calculate the the sum of p*ln(p) for about 10 million numbers. A nested loop inside a “Column Expression” node takes about a minute to calculate the result of 10 million numbers. Unfortunately we have about twenty thousand batches of 10 million numbers, which in total will take us about two weeks to calculate. We were wondering, is there a more efficient way to make this calculation?
Specifically, the calculation is:
Given constant doubles k and d, calculate
p_n := k + n*d (n=1…10M)
For each p_n, we calculate the product
p_n*ln(p_n)
Sum of all p_n*ln(p_n) for n=1…10M
Trying to speed this up we tried generating a table with 10 million numbers and making the calculation, but it takes even longer than the nested loop. We were wondering what is the fastest way to make this calculation. For example, using a Python node, a JavaScript node, a Groovy node, or else?
Can you provide calculation example data and workflow for the current calculation method? Note: Sample data may not necessarily be real data, but can be simulated. Because I am worried that I may not fully understand your calculation process.
The general optimization idea is to use vectorization or column calculation to avoid computation in loops.
You can try using Python script nodes to call third-party packages for calculation. I’m not sure about the latest progress. I got stuck while installing the cudf package.
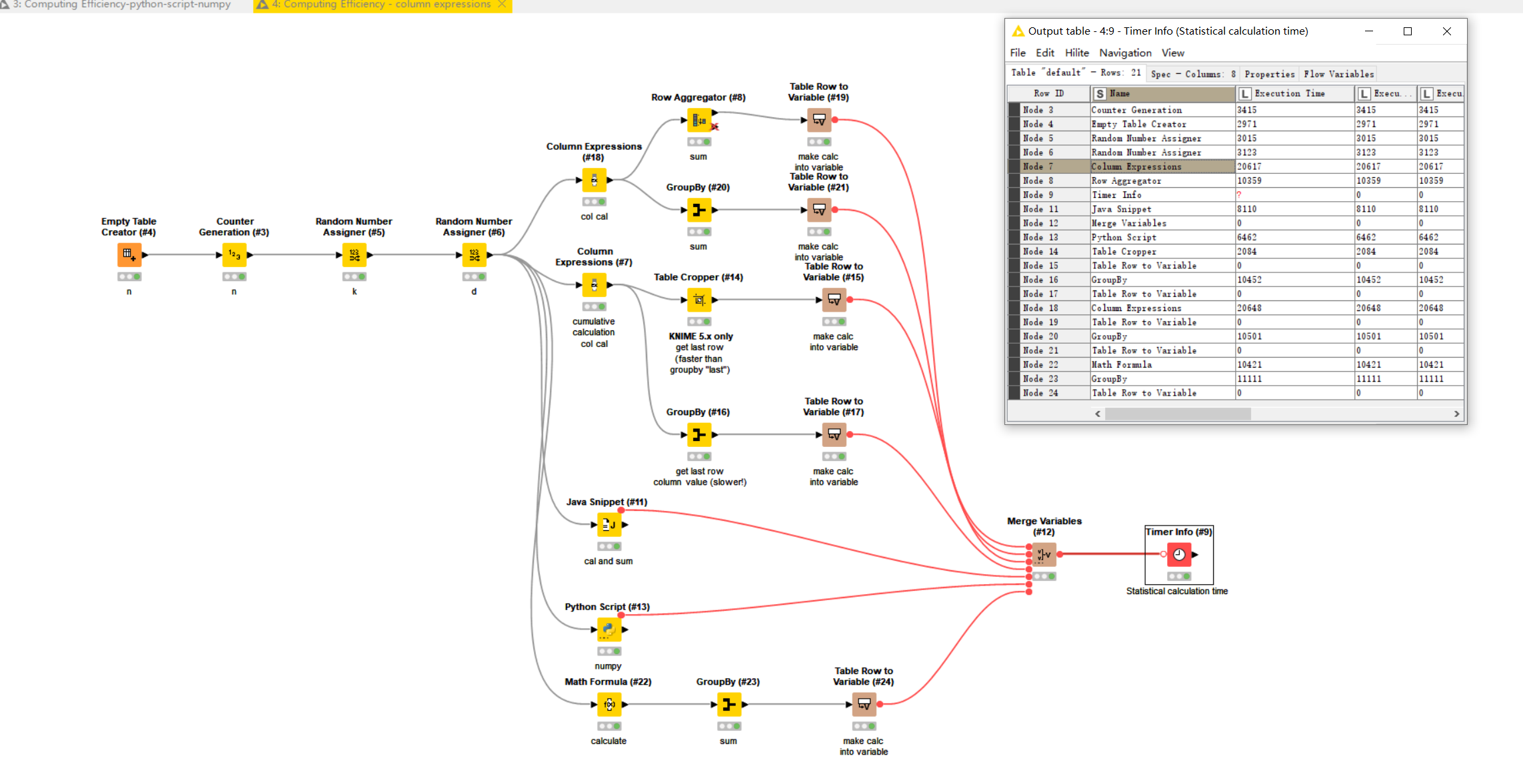
Edit: you’ll notice how much a different hardware setup can make a difference to the timings! In my example, the Column Expressions node took 86 seconds to do what @tomljh 's machine did in 15 seconds. So my different node timings are comparable within the same system, and clearly to get the best performance, you need to make sure you have a fast machine with good processor and available memory!
My hardware setup used in the above an older i5 laptop with just 6GB of memory allocated to KNIME 5.2.2.
KNIME wanted to use more memory than that, so this would have been a significant bottleneck in my performance test. For handling millions of rows with what is a relatively simple calculation, I’d suggest that memory availability will have a significant impact (possibly the biggest impact) if you are trying to get every bit of performance out of your system. Also note that my results were from a single execution of both nodes. A greater number of executions would be needed to reliably say that one node was faster than the other.
My computer is a desktop computer with 64GB of memory and i9 CPU.
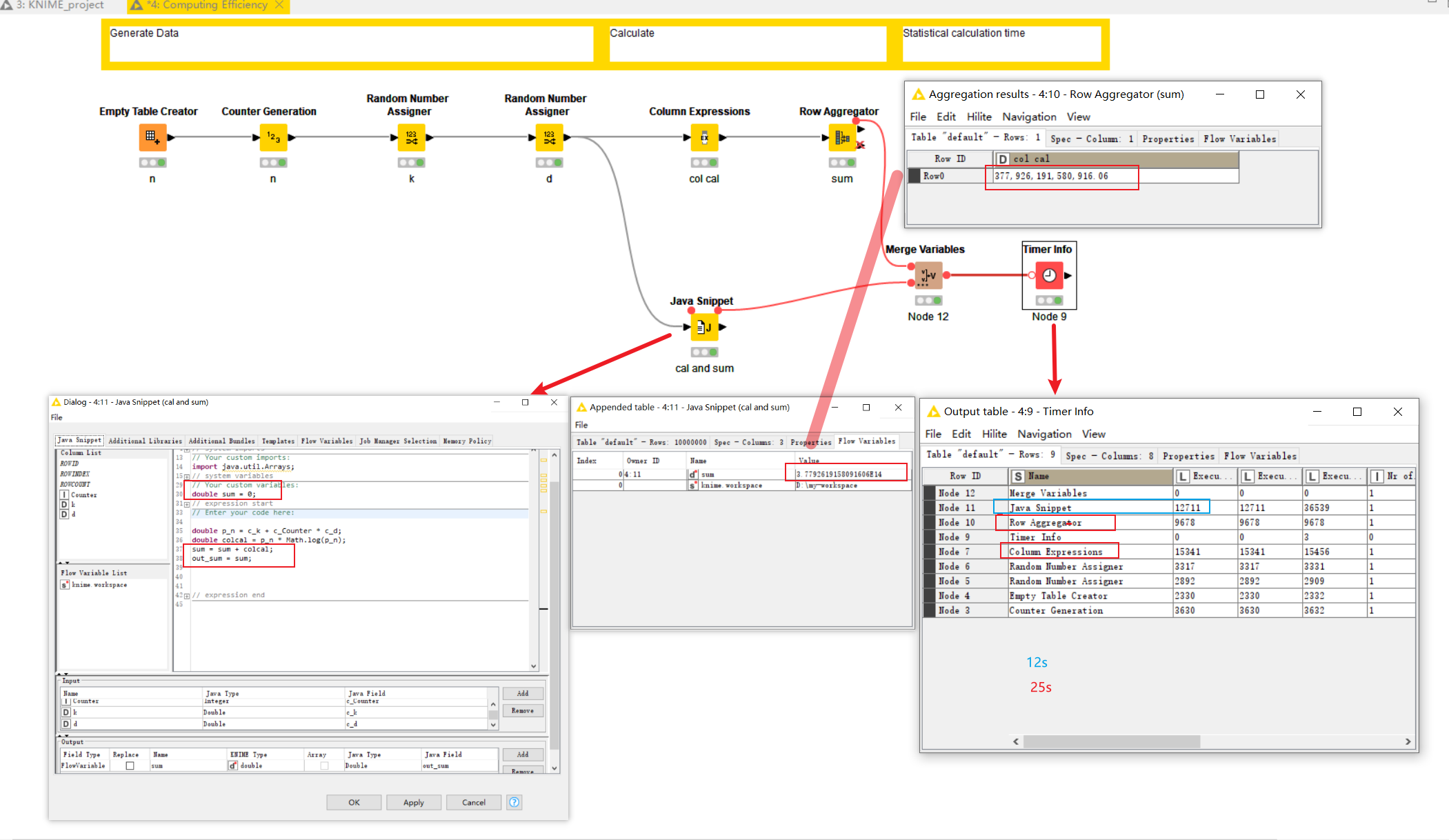
I merged column calculations and row summation based on @takbb , which can be completed in 12 seconds.
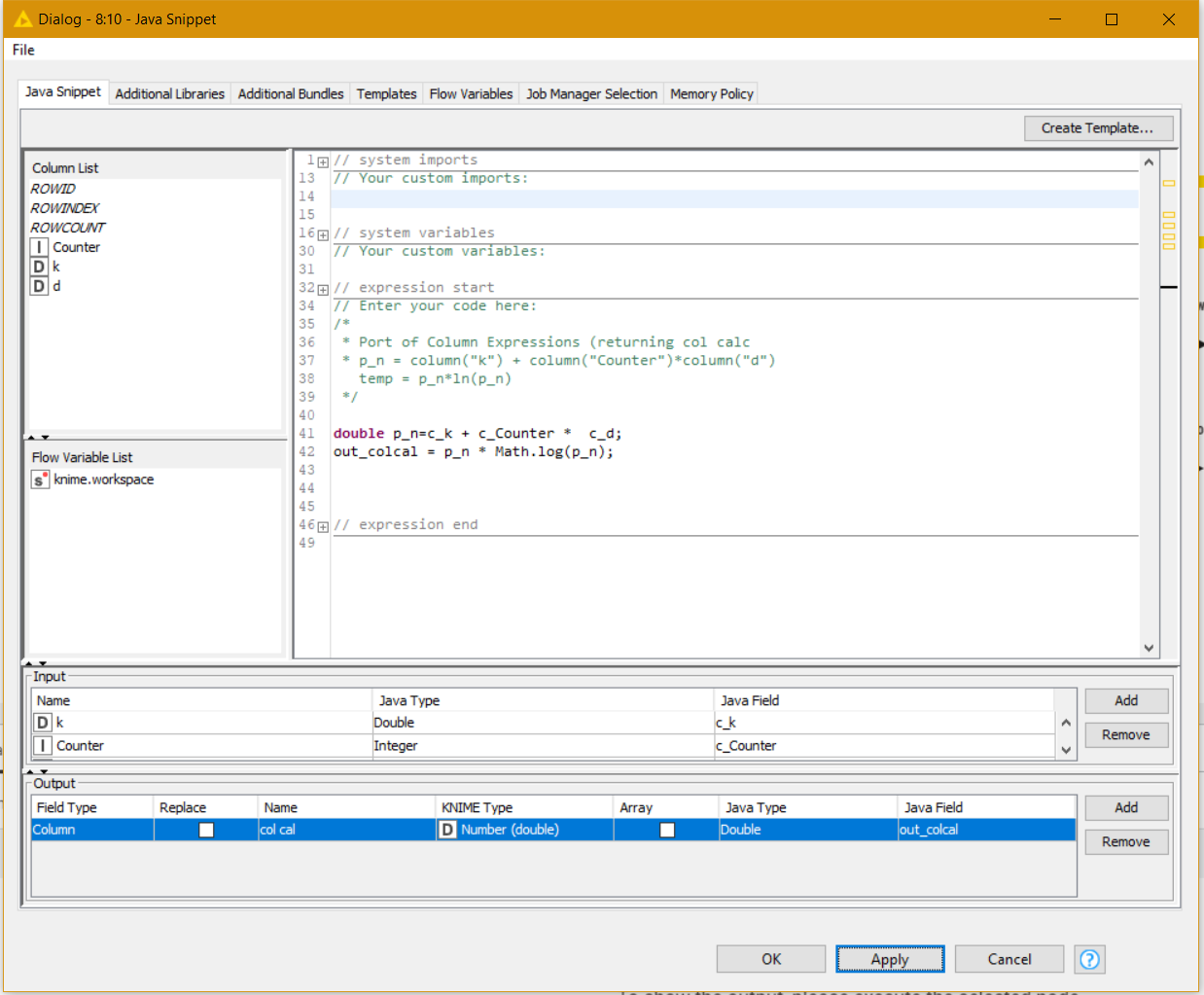
Hi @tomljh , good idea to include the aggregation in the java snippet!
As an aside, if you only need the aggregation and not the intermediate row results, the Column Expressions node could also be coded to perform this aggregation via a similar technique.
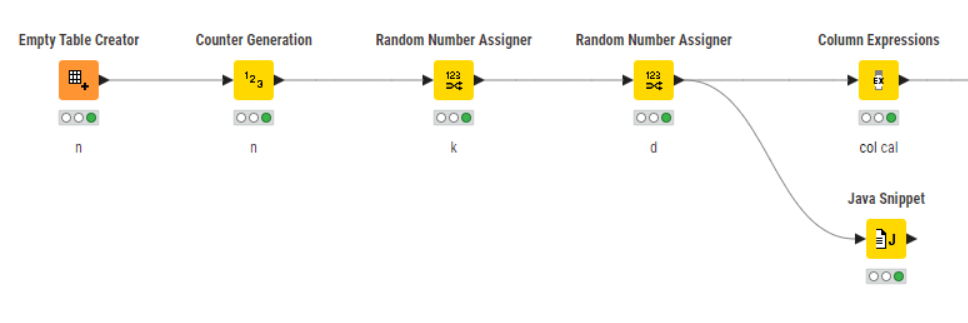
I studied that the ColumnExpressions node seems to only support one type of output - columns, while the JavaSnippet node supports two types of outputs - columns and variables.
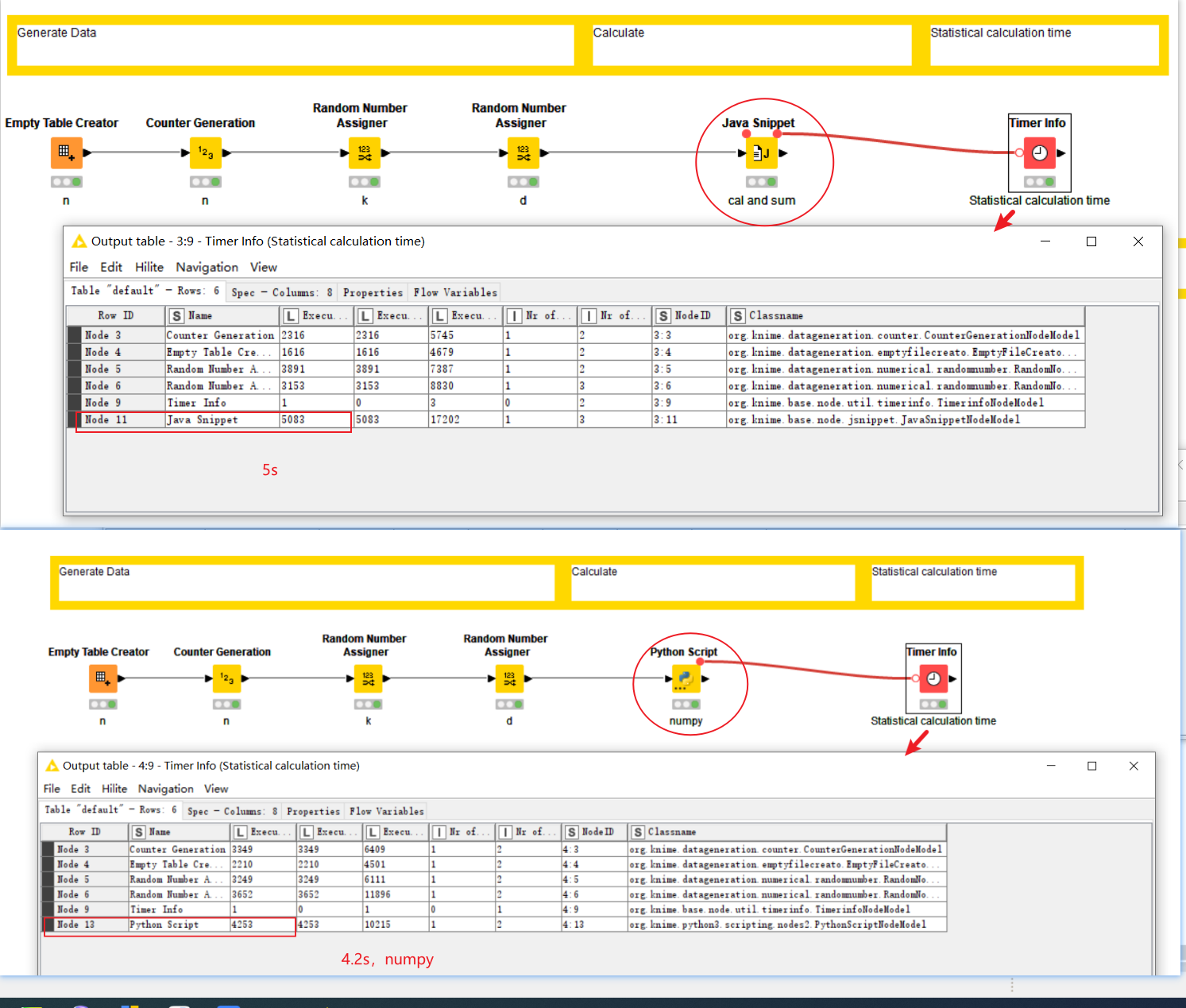
If there is only a CPU without a GPU, you can try using Python nodes for large-scale operations. Using numpy can achieve a computation time of less than 5 seconds. (Note: Under my calculation conditions)
Java snippet can also achieve a computation time of only 5 seconds. I just cleaned up the code.
That’s really good information @tomljh , and very interesting to see the results.
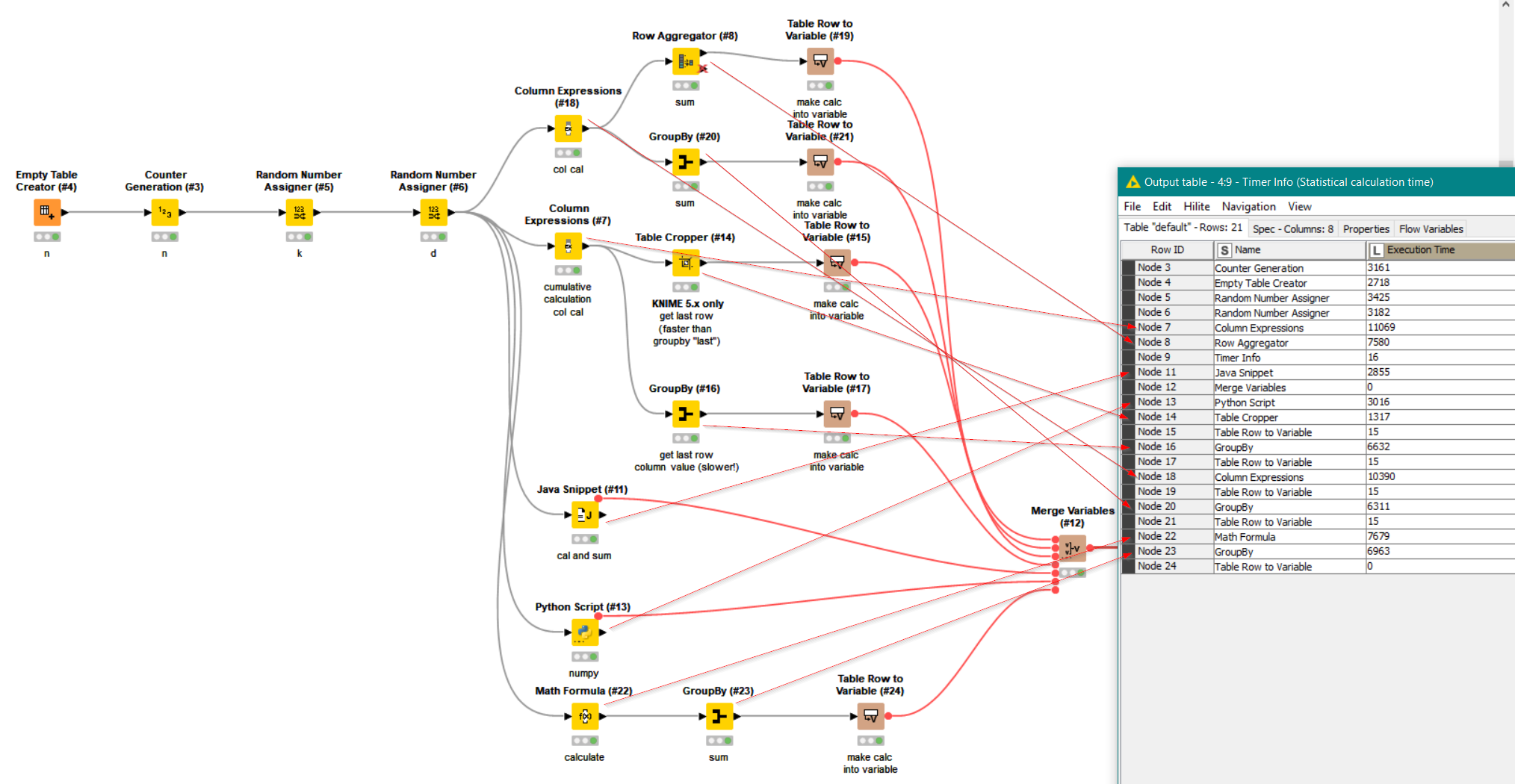
Going back (briefly) to Column Expressions, you are correct re the flow variables, but it could generate a cumulative calculation from which the final row value would be taken. There is no way that this is going to match the performance of your java and python results though
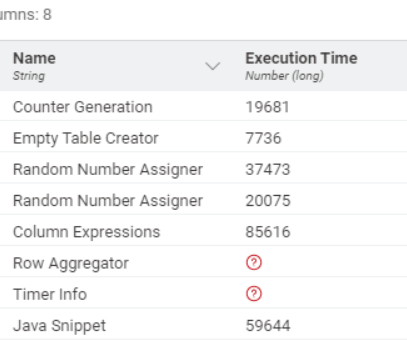
Just as a comparison, I’ve attached examples (and also I looked at how Math Formula performs) onto your previous workflow,but it doesn’t provide any new ideas for better performance over what you have already done! I’d be interested to know on your system how these different methods perform.
With multiple uses of the same node type, in classic UI, if you turn on “Show Node IDs”, on the “Node” menu, it would make it easier to match the node number to the Timer Info results.
I’ve just opened this on my home computer (funny how my personal computers are generally a much better spec than anything my places of work provide!). Not quite as beefy-sounding as your kit @tomljh , but it’s a core i5-12400 with 32GB (20GB available to KNIME 5.2.2), and a bit more “with the times” than my work laptop!
The timings listed were for each of the nodes running alone rather than multiple nodes running in parallel. (I manually executed them one-by-one rather than add flow variable connectors to enforce serial-running)
Edit: On a few re-executions of the Python and Java snippet nodes, it gave the following results:
I ran your workflow as a whole. Each computing branch may compete for computing time on the CPU.
Accumulate calculations in the list expression nodes without increasing costs. For example, nodes 18 and 7, as node 7 is an accumulation calculation, subsequent nodes can be optimized.
Whenever I install KNIME (admittedly using the zip archive on Windows rather than an installer) KNIME allocates only 2GB by default, and I always have to increase it (when I remember!). I recall thinking that KNIME 5.x was a lot slower than my 4.7, until I remembered I hadn’t given it any memory, lol.
My calculation time is 4-5 seconds, while on your machine it is 3 seconds, which can be explained. Mine is a set from three years ago, with a 10th generation CPU and relatively low memory frequency.
From a data perspective, the amount of memory allocated to KNIME must reach a certain limit in order to fully utilize its performance.
Yes I think you’re right if yours is 10gen. The processor generation is likely a big difference… I know I decided on an i5 12-gen over a similarly priced i7 10-gen on that basis.
This is actually the first time I’ve had reasonable evidence that it was a good decision!
Compare with the relatively woeful performance (I posted earlier) of my laptop… Also an i5, but this time a 10th gen i5-10310U
OMG @takbb, how log it took you to write this?! I may be slow but this is absolutely amazingly detailed and helpful. Fantastic job, I’m truly impressed.
I guess that there is a fundamental question of performance here, one which is of interest to a large community. Many people will benefit from the comprehensive comparison you have very kindly provided.
In all, the experience left me with the highest regard to this community and their dedication. You guys rock, thank you again!
Hi @harrytuttles , that’s very kind of you to say, but I think this was very much a joint effort with @tomljh who came up with the great ideas, and we just bounced off each other.
Kudos though to @tomljh who produced the python and introduced the idea of having it and the equivalent java snippet calculate the total aggregation to reduce the overall processing time. So… if between us we’ve provided information to help you find a solution, could I suggest you mark one of his posts as the solution, e.g. perhaps this one