Hi @Startide
I’m not sure if this is a “better” solution… but here goes…
(Edit - i previously inadvertently referred to column renaming instead of filtering so I have corrected my earlier wording. This applies equally to filtering and renaming of columns)
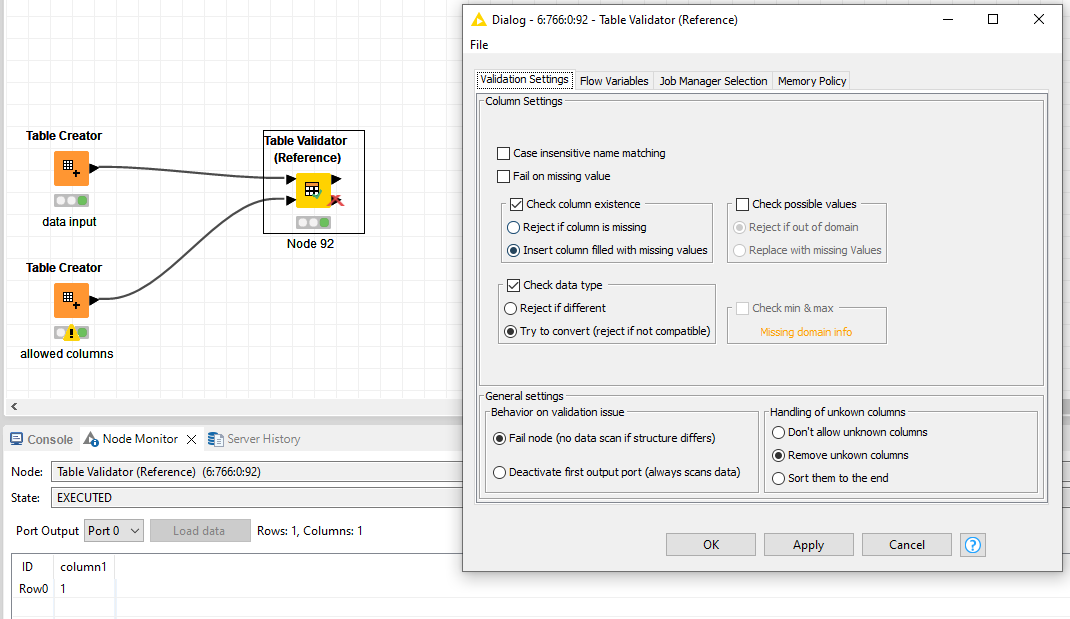
So as you have said the Column Filter node cannot work on more than one table, and Table Validator Reference needs to be placed for every node being filtered, even though if it is using a reference table, at least it doesn’t have to be configured each time, but I take your point that you do have to drop in a Table Validator (Reference) node for each filter that is required.
So what other options are there?
Well, there is a node that can rename the columns on multiple tables at once as well as removing columns: the Table Manipulator node. The downside is that it only has one output port, and what it does is concatenate every table.
You can however tell it to include a table sequence number in the row ID, but you still face the issue of how then to split out the data into the original outputs. You could manipulate the new Row IDs in a new column
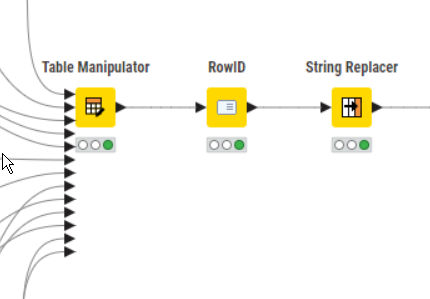
and then perform a Group Loop, and place your Excel Writer inside the loop, but that is likely to incur a performance penalty and may not be desirable. Unfortunately there isn’t a node that can easily split out your data into the original (arbitrary number of) tables.
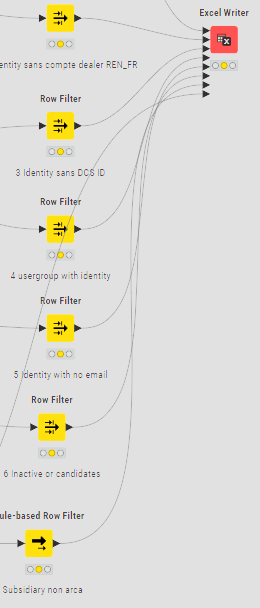
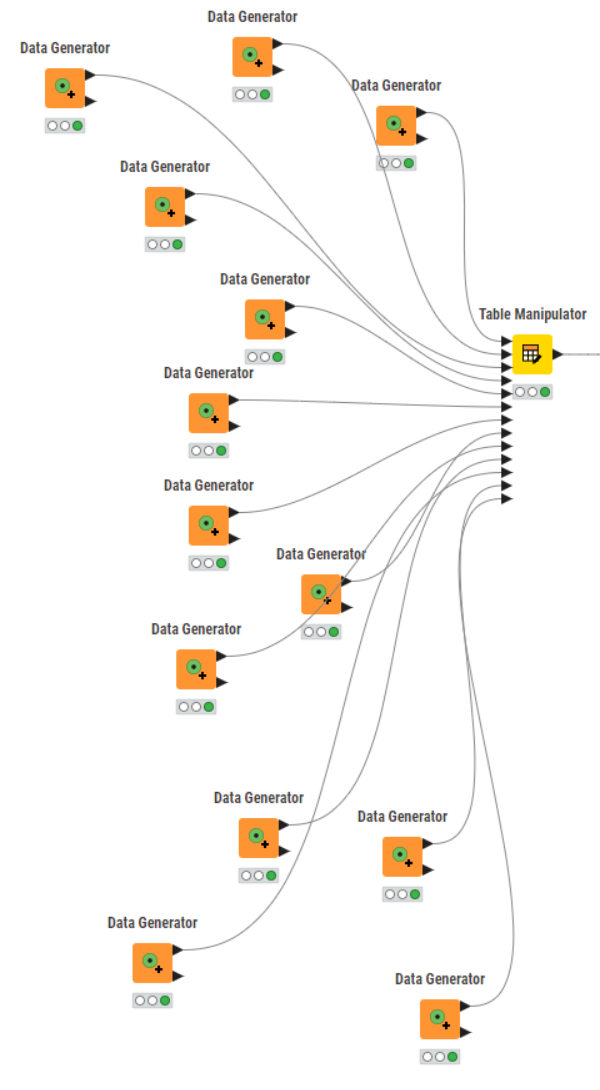
But… I do have a component which can assist here. It can deal with 10 outputs, but for more outputs you can chain them…it isn’t pretty, and for 70 different outputs this means you need 7 of them chained together.
It would look like this - albeit I didn’t use 70 inputs!! (This has to be the most “fun looking” workflow I’ve ever written  )
)
You can find the origin of the Regex Multi Row Splitter here
I have uploaded the pictured workflow up onto the hub.
I’m not sure if I would recommend this as a solution or not (maybe it would depend on the size of the data as it could end up being a huge concatenation), but it was an interesting experiment!