I am not sure, this is an academic question. It is in my context, for sure, but I just wanted to know.
I have several master data tables in a database. I need to load multiple files of the same structure into the database and enrich the data beforehand with master data. For now, I have a loop “over” a list folder node, where I can read in the different files in “one” go. I have a DB Table Selector and DB Reader placed within the loop, such that it get executed against the DB for each file. While in my context, this will not impose a performance problem, I might, if the query to read the data is complex and/or the tables are huge. Now, if the result set is small, it would be efficient to only select the master data once from the database and cache it such that each iteration can use the cached data instead of querying the database anew. Is that possible?
Another solution to this that just came to my mind is that it might be possible to stack the data read in the file loop and do the enrichment after the loop to the stacked data. Again, I would need to persist the loop data table stack to access it outside the loop. Is that possible?
If the files are all the same stucture, then reading the files within a loop, with the rows passed to the loop end node should result in the output of the loop being the union of all the rows read in (including any duplication).
What type of files are they? It may be that you don’t actually require a loop and can just read all the files in a folder, generating the concatenated output. It may depend on if there is other specific processing (or error handling on a per-file basis) that you need to perform as to whether this is a practical option.
But yes, you can read in your master data once before the loop, or once after the loop, if you don’t need to read anything differently from the database for each file being processed.
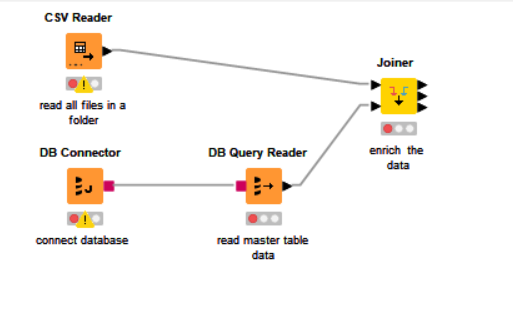
Your workflow could take this form, as a very trivial example. For expediency I have just used DB Query Reader, but this could be DB Table Selector, DB Query and DB Reader, or other combinations of db nodes…
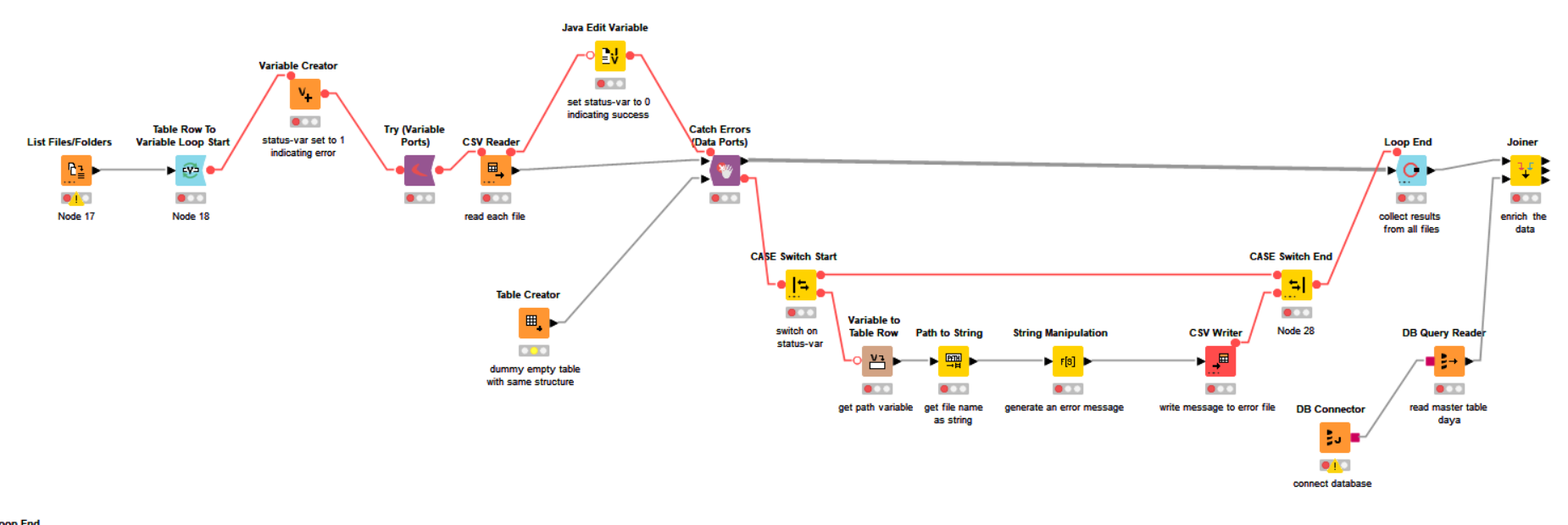
Or you could go with full error-handling of each file such as this:
(this is a quick mock up to give general idea, and there may be mistakes as it is not a real workflow!)
It is fixed length files where the records come in a number of flavours but only one is of interest. The record type is encoded in the first two character of the line.
I am under the impression, reading all the files as a batch as with CSV is, for what ever reason, not possible. Correct me if I am mistaken.
I was not aware of the data tables of each iteration being sent to the outside of the loop. Good thing. The overhead of filtering away the records of undesired types after the loop will not make a difference in my case - a couple of hundred records only and the majority of the is desired.