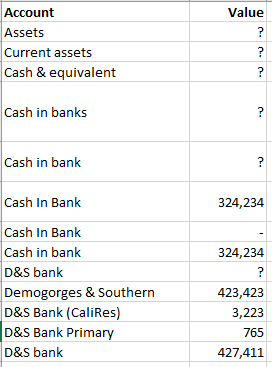
I need to transpose it such that accounts adjacent to the ? marks are “filled down” progressively to form mappings as such:
I’ve handled multiheader problems before, but the variable ? throws a wrench. This is an excerpted list, so sometimes there maybe three ?'s, or just 1, etc.
There is a pattern in that the appearance of a value does “reset” the counter in some way that I can’t eloquently describe just yet…
Quick update: So, got pretty close with the attached workflow. Quirk with the final output including two superfluous rows representing Account and Value…
Update 2: Not close at all when expanding to larger dataset. Mapping doesn’t seem to reset correctly.
Hi @qdmt, one of the problems was that you had " ?" in your data instead of missing values, so your row filter wouldn’t work. I fixed that with a Rule Engine although leaving the cells empty in the Table Creator was an option. I assume though that you actually had " ?" in your real data.
The remainder of the challenge was more tricky. Getting the “accounts” into the correct columns was dependant on working out what level each was at, and I had difficulty at first understanding the logic, especially as in the sample data the case of “Cash in bank” is inconsistent with your required output, but I assumed they were typos.
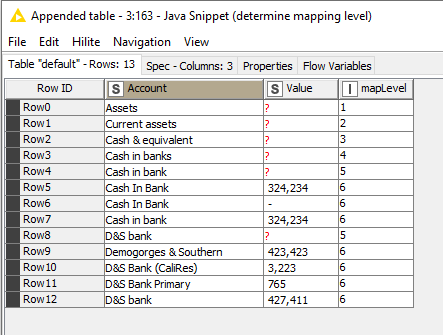
To determine this mapping, I resorted to a small java snippet, which cumulatively calculates the “map level” based on whether the value is “missing” or not:
Rule 1: If a missing value is found, then
Rule 1a: if the previous value found was also missing, increment the map level by 1;
Rule 1b: if the previous value found was non-missing then decrease the map level again by 1.
Rule 2: The map level increases by 1 when a non-missing value is found, provided that the previously found value was missing, otherwise it remains unchanged.
These rule gives the following map levels for your sample data:
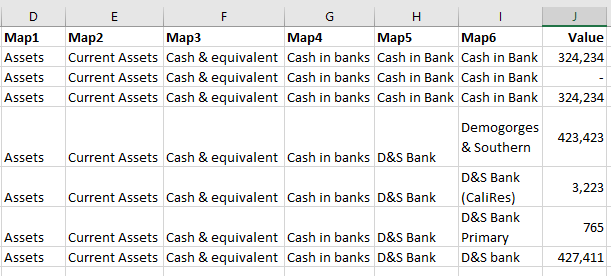
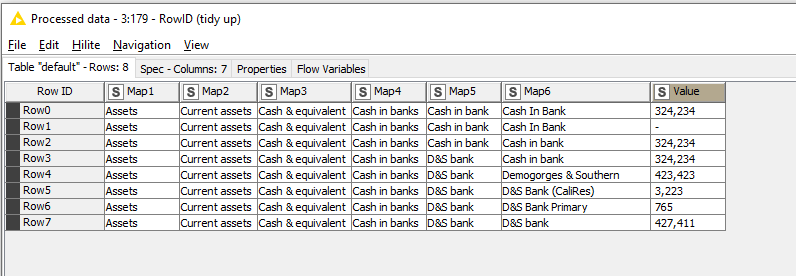
With this, the column names “Mapn” can be generated for each row, and it is then possible to pivot it to the required structure
Now you can do the fill-down and remove all rows with “missing” in “Map6” as they are the heading-only rows. Alternatively we could remove where missing Value. After a little tidying of columns and row-ids:
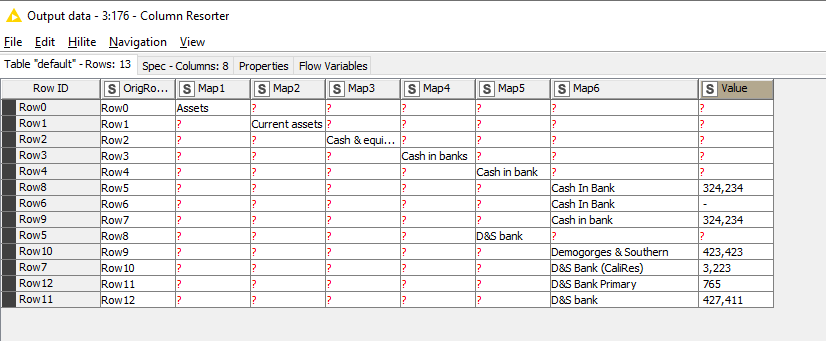
About ~40 mapping columns. This might be correct, but everything ended up carrying “Assets” as Map1. This was my fault - I found a new nuance to the logic:
I think the mapping “ends” when the same header is found further below with a value.
For example:
Eventually “Assets” ends as well, and then goes onto Liabilities and all their associated subaccounts.
I could be overdoing it, but was curious to see if it could be KNIMED. In a sense, Excel Pivot Tables has a similar functionality where you can “flatten” a table and “repeat headers”.
P.S. Not sure if there’s a typo with “Cash in Bank(s)”. There are multiple banks, so the “Cash in Banks” is a roll-up of the multiple banks that could be found in the balance sheet. Why one line says the singular “Cash in Bank” besides actually naming the bank, I’m not sure.
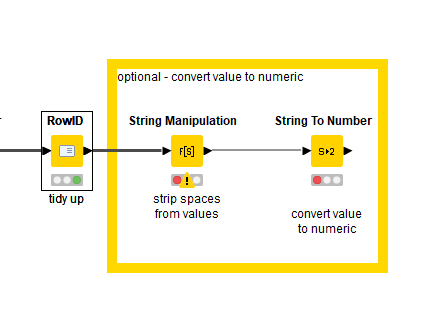
Hi @qdmt , those last two nodes were just me trying to convert the values to numerics “for completeness” , so made some assumptions which may not be valid. They don’t add anything to the mapping but I’m curious to know what the error is in that String Manipulation as I think it is just stripping spaces. (Not at my pc at the moment).
In terms of typos I was referring to the “expected result” on your original post where the input table has lower case “bank” “Cash in bank” for 324,234 but in the output it has capitalised “Bank” at Map6 column.
If you remove those last couple of nodes where it errors, is the result something you can work with? The Java could probably be adjusted for additional rules but would need more sample data so i could better understand/test the rule.