I needed a token-less API to play with and figure out pagination. Google Books API was a bit boring and wanted something a bit more interesting. Enter PokeAPI.
There weren’t too many posts here that fully discussed and resolved pagination, especially with breakers (when it is unknown when the last “next link” will be provided), so after resolving this, I thought to share a complete, working solution and demonstrative workflow to paginate an API and concatenate results.
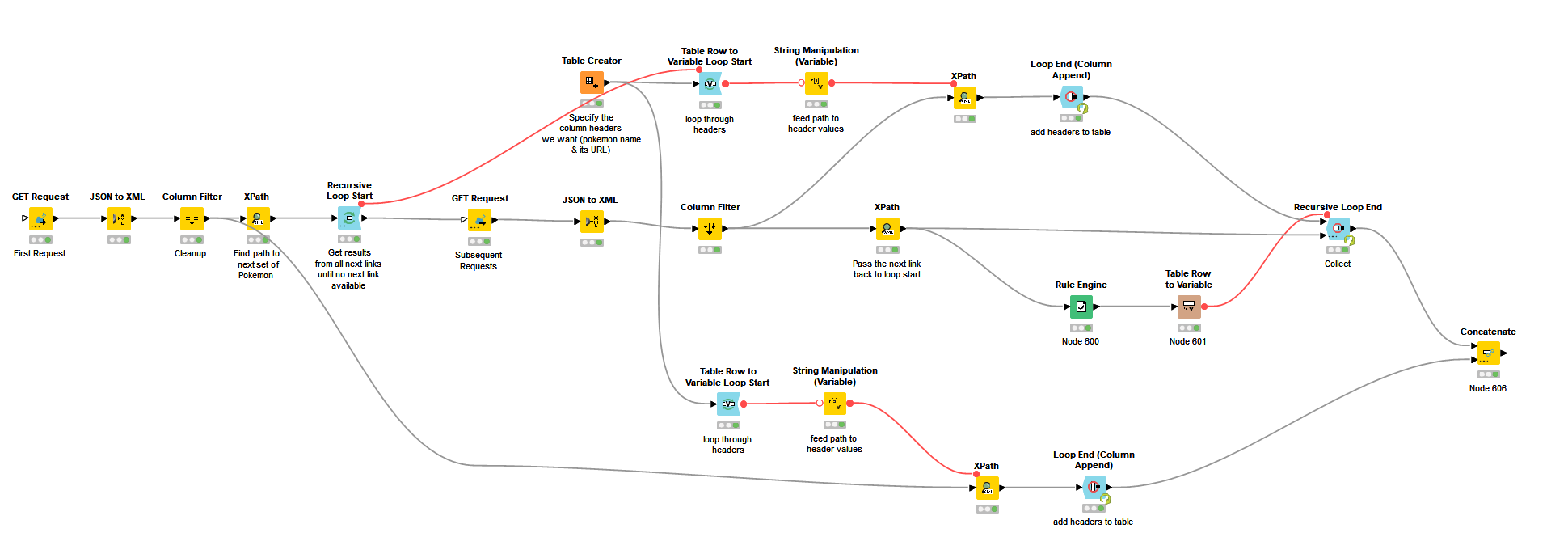
The workflow performs the following key sets of activities:
Gets lists of Pokemon and the link to the next list
Loops over the links and table headers, collecting results each time
Breaks the recursive loop once the next link is missing
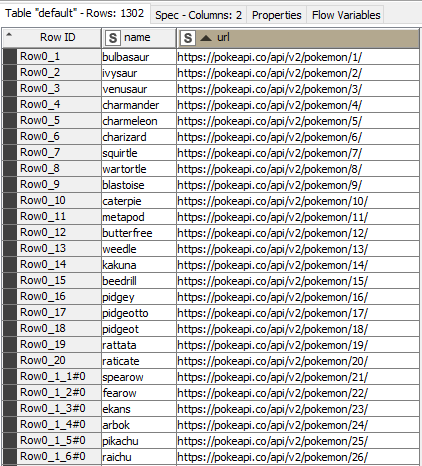
Final table with all 1302 Pokemon:
This result table could be taken a step further and call each Pokemon ID (with the captured links) to further query their stats, etc.
Key Learning:
The Loop Breaker is powered by the Rule Engine node, and that node specifically has to out put “true”: in lowercase, and captured in quotes.
Subsequently, the Table Row to variable immediately following the Rule Engine node has to output “false” in the default case (i.e., next link still present). Otherwise, a blank string will fail (the use of variable to end recursive loop depends on explicitly seeing either “true” or “false”)
Care should be taken in the XPath node querying header values: this should output “Multiple Rows” and not Single Cell. This is an easy mistake to miss, as your final table will still look like a proper table with many rows - but in fact your total row count is not the rows of the data available, but the number of iterations that were run. The PokeAPI is helpful here as we all know how many Pokemon there are.
Applications:
Paginating APIs with unknown page numbers
Finding XPath headers when the path is known, but attributes are many
Hope this was helpful. Happy to get feedback as well on where this could get improved. I could see potential opportunities in either optimizing the way XPath attribute-headers are grabbed (which can be slow when there are hundreds of attributes and thousands of records per page), as well as consolidating the two GET Request nodes, which in turn would eliminate the need for downstream concatenation.
nice workflow & nice topic. I prefer JSON to XML handling and find it interesting that you seem to like XML better. Your workflow inspired me to create my own. The result is shared here: API Pagination – KNIME Community Hub
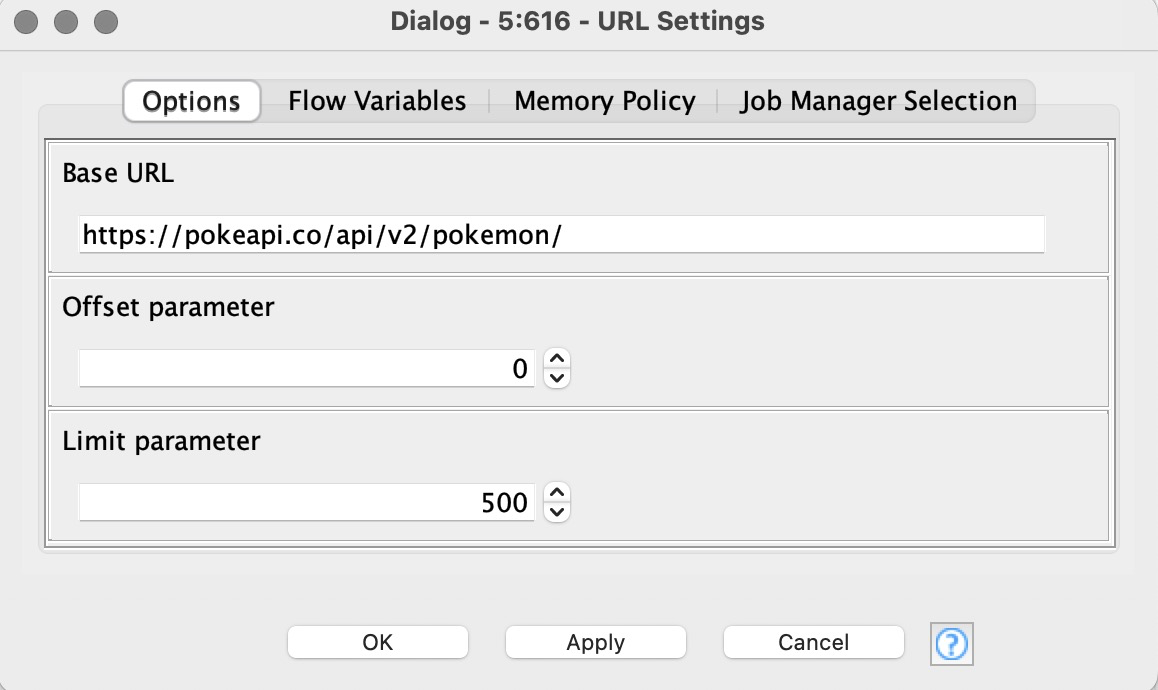
My workflow begins with a settings node. You can set the base url as well as the offset & limit parameters. Inside this node the user input is concatenated to a string variable called url. In real life / with real (undocumented) APIs you can play around with the parameters and find out the maximum allowed limit value, for example. I try to maximize the data amount per API call.
I use a generic loop in which the data is retrieved. The GET Request is parametrized so that the url is set by the flow variable. After data retrieval it will be checked, if the loop should end (no next url in the API response).
Here are the settings of the Loop End node. What I like about this node is that you have more flexibility with the exit condition. I use a flagging variable (0 = no, 1 = yes) instead of a pseudo boolean (string which says "true" or "false"). Note that the option Propagate modified loop variables is checked. This means that the url for the next API call gets passed back to the loop start.
I like this better than using the Recursive Loop where you have to pass table columns back to the loop start and also have restrictions regarding the loop end flow variable.
After the loop end, the data is extracted. I do this in order to keep complexity out of the loop. Also, this might be faster.
Overall, I try to make my workflows as generic as possible. I like to put everything into components which solve a certain part of the total task. I think, with a few changes to the URL Settings component, the workflow can be applied to other APIs. For real APIs, error handling and authentication needs to be covered, of course.
Let me know what you think. Also, this workflow might help some users playing around with APIs. I’d love to hear about that
This is fantastic - I just timed the difference: 2.5s with your approach (vs. 9.9s). Quite incredible.
I actually do prefer JSON Path as well, but had trouble figuring out how to grab the “attribute names”. In this example, there’s just two: name and URL. However, in a case where there are 100+ column names, it is not so ideal to type these out in XPath. XPath is also slower to load the XML than JSONPath is to load JSON cell.
Your approach completely bypasses that issue: it shapes the JSON down to a format that is easily consumed by JSON to Table node, which then generates the column headers.
Interesting. I used the URL generated in my settings node (https://pokeapi.co/api/v2/pokemon/?offset=0&limit=500) with your workflow and didn’t find a difference. Also tested it with 100 per request. Both equally quick. How did you find the performance difference?
Just a basic stopwatch comparison between the two…got the same ~3s vs 10s. Perhaps your CPU architecture handles KNIME workflows better
I updated the workflow to incorporate your JSON Path approach (and overall approach to first collect all JSON and get the requests out of the way, then crunch into a table). Got the time down to ~6s.
I’ve wrestled with incorporating components, but filter parameters can differ from API to API (e.g., the same “offset” parameter can sometimes be referred to as “skip” or “top”).
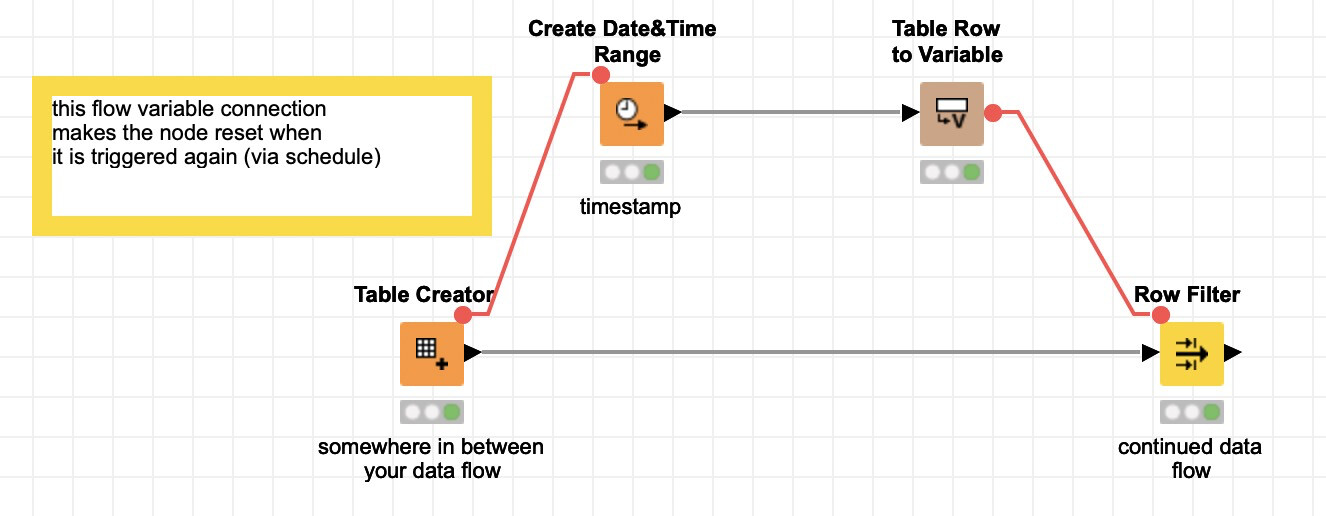
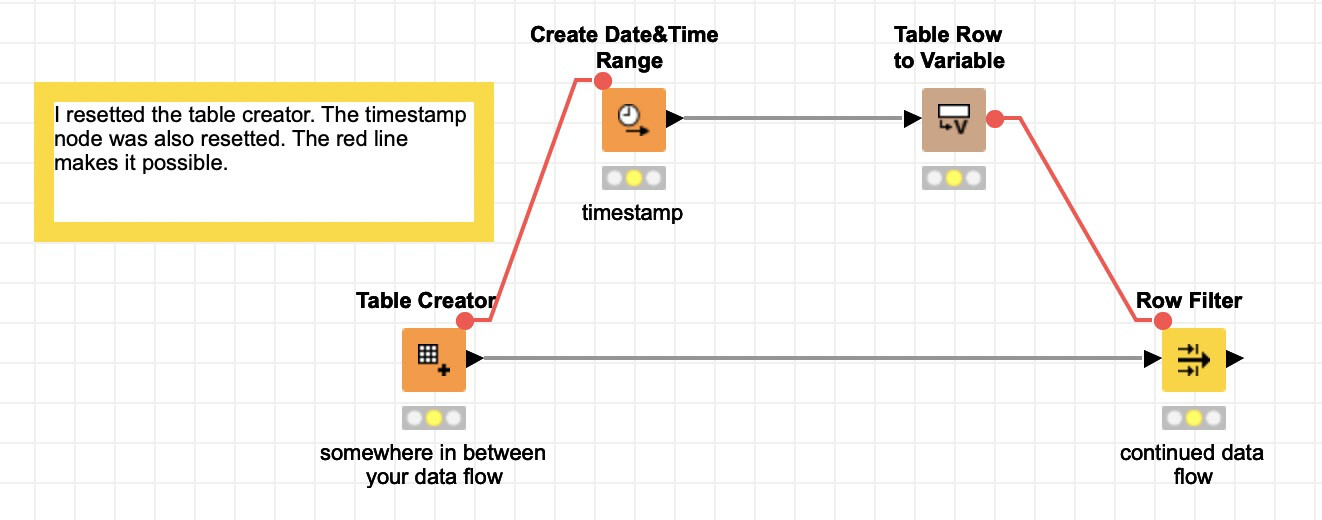
Maybe you have already solved the issue. If not, this might be a nice new pattern to use. When you do a flow variable connection on the invisible edges every node has, this impacts the execution.
Hey @JLD - thanks for following up on this. It has been sometime, but I think what I was running into was the notion that when workflows are executed by a batch process without GUI (e.g., with Windows Task Scheduler), flow variables aren’t reset. In fact, there was a time I caught this when I noticed that the date was still stuck to the date I last opened the GUI, despite the rest of the data being ‘fresher’.
I don’t recall if I tried the flow variable line as a trigger - it is a technique I regularly use now, but not sure if I used it back then. I may have also just been trying to rationalize some nodes.
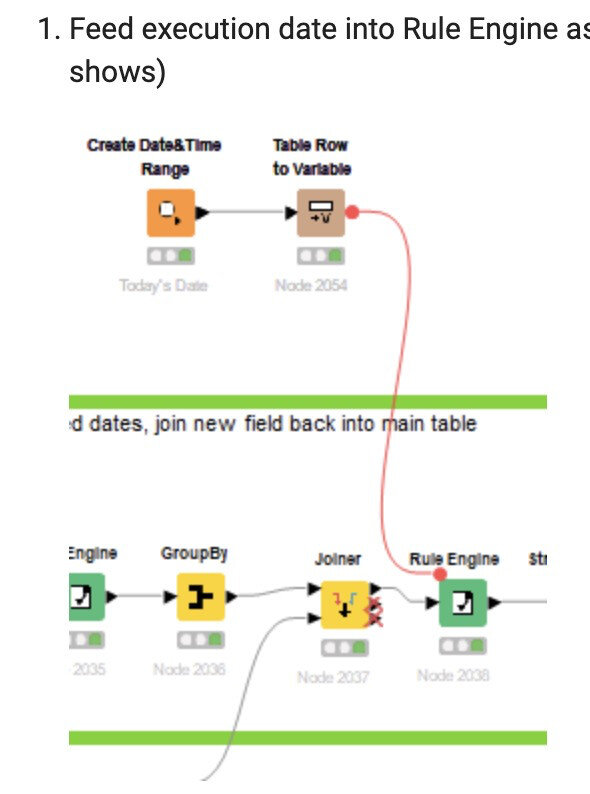
For that specific problem (getting system timestamp into the workflow) I now use the Java Edit Variable (thanks to @qqilihqhelp here) and as you suggested the flow variable line to pull it in. Seems to work in batch mode as well.