Hi,
are you sure that there’s a difference? I just checked with a simple example and it’s very similar (KNIME uses integer instead of double values):
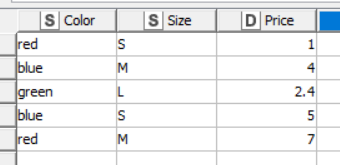
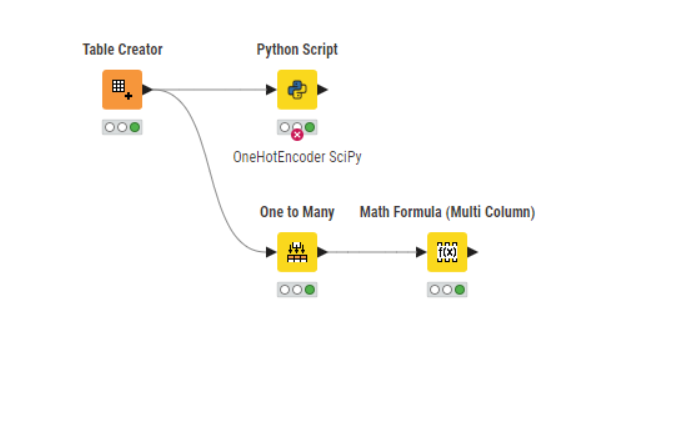
Table Creator:
import knime.scripting.io as knio
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
# Get data from KNIME
df = knio.input_tables[0].to_pandas()
df = df.reset_index(drop=True)
cols = df.columns
# EDIT HERE!
cols_to_convert = ['Color', 'Size']
other_cols = list(set(cols) - set(cols_to_convert))
# initialize OneHotEncoder
encoder = OneHotEncoder(sparse_output=False, drop='first') # drop='first' category
# transform Categoricals
encoded_data = encoder.fit_transform(df[cols_to_convert])
# Write result in dataframe
encoded_df = pd.DataFrame(encoded_data, columns=encoder.get_feature_names_out(cols_to_convert))
# add numerical cols
final_df = pd.concat([df, encoded_df], axis=1)
# output
knio.output_tables[0] = knio.Table.from_pandas(final_df)
I used the “Math Formula (Multi Column)” Node to convert the integer columns to double.
yeah you are right, thats a bit tricky for 60 cols.
Here is a solution that might help.
And in addition I found a strange behaviour of the “One To Many” node.
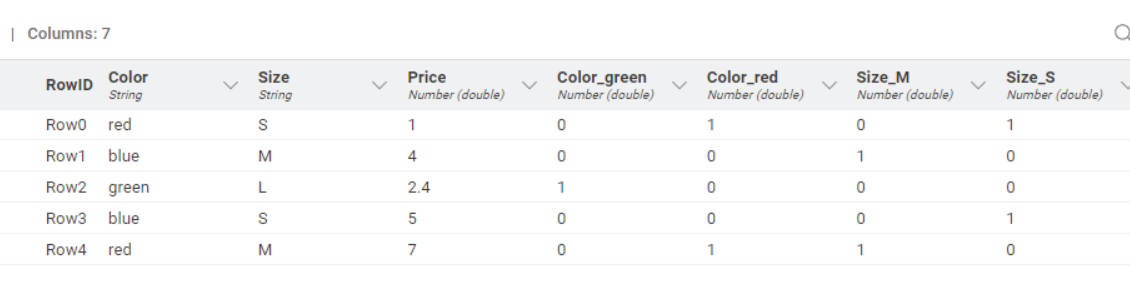
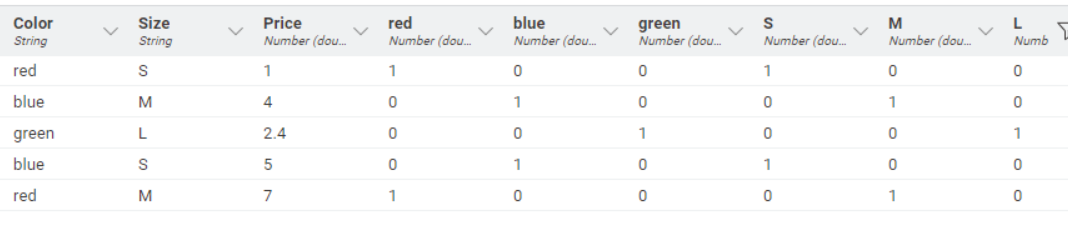
By default it does not add the column to new columns and just uses the entries. Like “red” instead of “color_red” or “red_color”.
If two columns have similar entries it does add the column name automatically to avoid doublettes in columns names. For example:
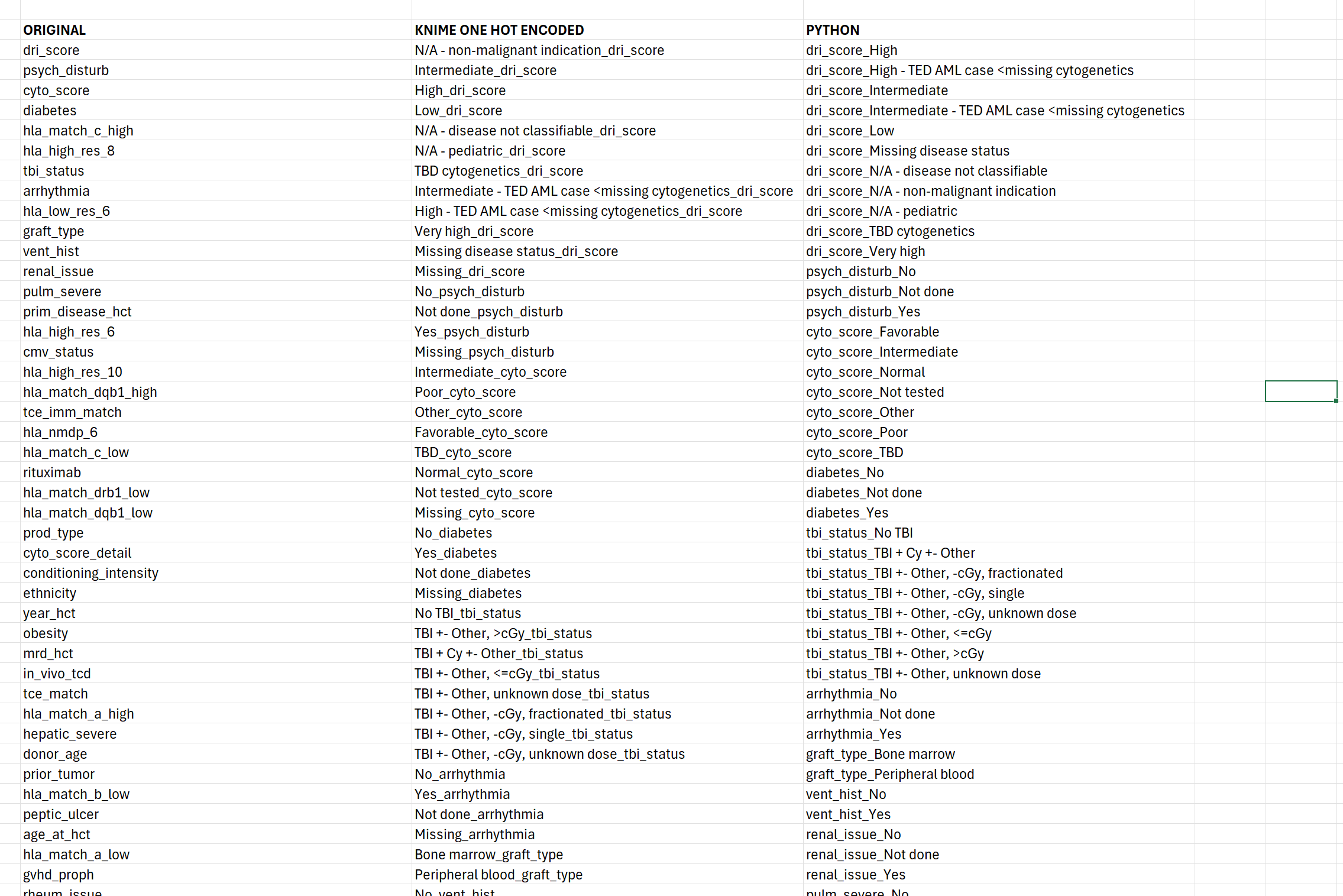
To be more precise here’s a screenshot of the issue.
The left column is the original. The middle column is what I’m getting with the one hot knime node. The right column is what python outputs.
Looking at it with fresh eyes, it seems that Knime appends the column names to the end instead of the beginning and as ActionAndi found only if there are similar names? Not sure of the exact behavior of Knime.
Yeah.
Look at the workflow I’ve shared. I’ve tweaked the naming so it matches with the python names.
If you need other naming conventions just change the “string manipulation” node within the loop
Hello @Durkweed and welcome to the KNIME community
You can take a look to the following post, because this component in the Community-HUB’s workflow, will take the encoding job for the columns; And it would be helpful for your use case.
Be aware -as explained in the post-, that the workflow drops a column for each set, aiming to avoid ‘dummy trap variable’