I’m going thorough a large amount of data files spanning over 10 years. One of the issues I’m having is that some of these excel files are corrupted. So the node dies and I have to manually remove the file, run again until I hit the next one.
Is there any workaround to skip or ignore this issue and keep the loop going?
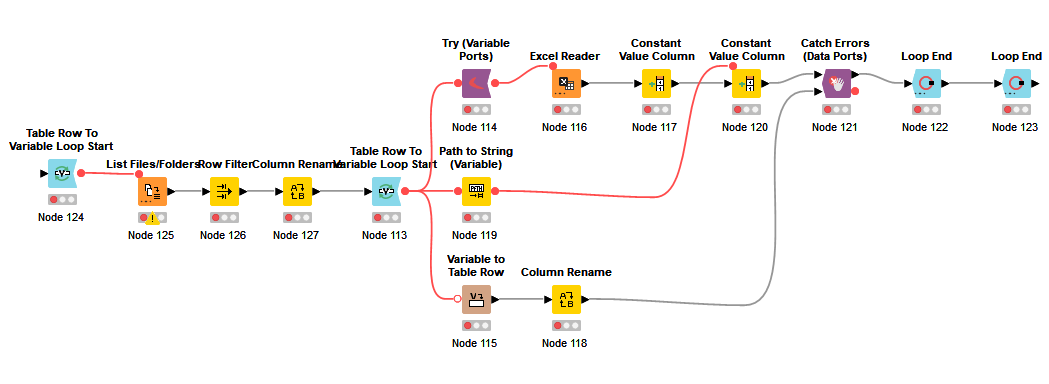
The following workflow, although not using the same source of data, shows how to use a -Catch & Try- pair of nodes to prevent a loop from stopping when the reading of data at a given iteration is faulty:
A snapshot of the workflow where this is implemented:
This concept indeed did work. I pass the file location into the try variable. I also pass the source path to attach to the data in the constant value along with the year (from source folder). I also use this source path as an input to pass in case there is an error. That way I get all the data from the files that worked as well as a list of failed files.