This may be a layman query, I am new to data analytics itself.
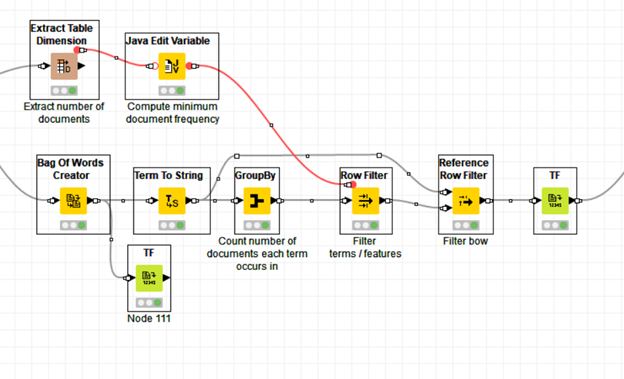
In the following snapshot, post creating the Bag of Words and Filtering the terms and applying the Reference Row Filter, while computing the TFs, how does KNIME compute the same? Does the underlying document’s term structure also get filtered and TF is now computed on the altered document? I am unable to see any such setting in the Configuration settings which ask you whether to append/ replace pre processed document while going through BOW to Reference Row Filter (as available in the pre processing nodes).
Thank you so very much for the reply. My query actually is, to compute TF, it is only the concerned document detail that needs to be configured in the node (if I am not wrong). If the underlying document is not getting modified, shouldn’t the TF node return the same results when executed both after the ‘Bag of Words Creator’ action and the ‘Reference Row Filter’ action in this part of the workflow (irrespective of whether I have done some filtering in the Terms column)?
I am not sure whether my query is valid or not. Please help. Thank you.
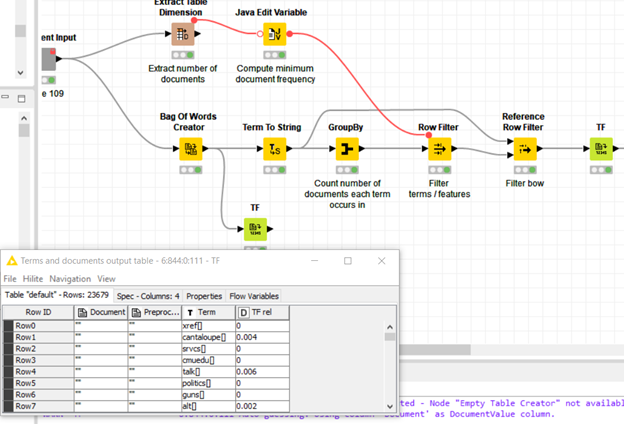
The original TF node is using the “Preprocessed Document” column but the one you have added (Node 111 in the screenshots) is using the “Document” column.
Thank you again. I had tried to check with both documents (which is when the screenshot was taken), but its still showing disparity between the 2. (Another strange issue is that both “Document” and “Preprocessed Document” give the same results). Could you try checking please? Thank you for all the time you are giving this issue.
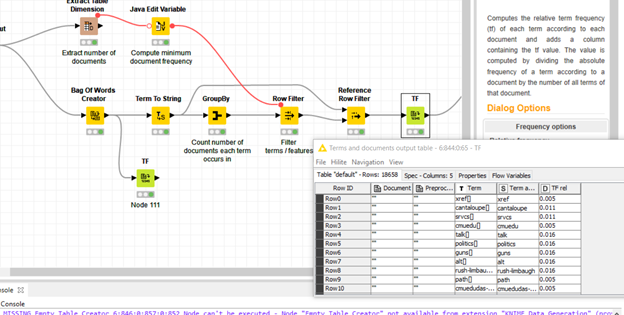
I just checked the workflow. Using the same document column after Reference Row Filter or right after the Bag Of Words returns exactly the same results for the same terms of the same document.
The only difference, obviously, is the filtered terms. So the second TF output has less number rows since some were filtered by the Reference Row Filter node.