Hi all,
The case is, that we would like to predict whether a customer that buys tickets to a koncert might also buy tickets to a theater. We have tried using a decision tree, but it does not work for us.
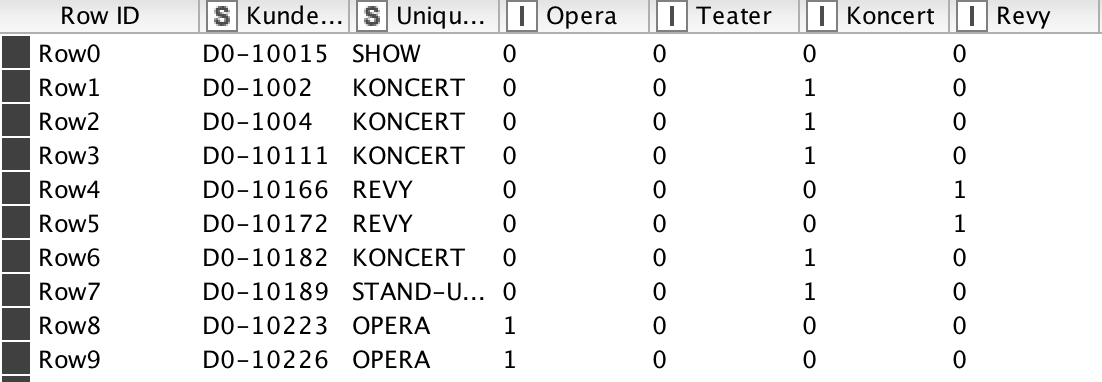
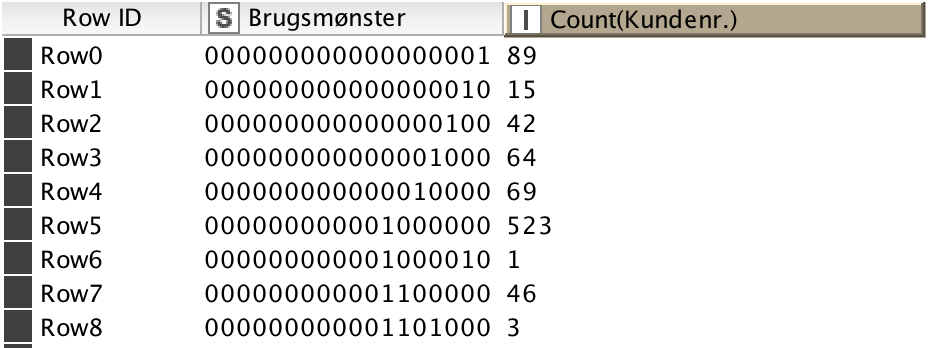
As seen in the picture below each row in our dataset consists of a specific customer and what they have bought tickets to in different genres. The ‘0’ means that they haven’t bought a ticket, and ‘1’ means that they bought a ticket. We have combined these values into one string, so we have the possibility to see all the combinations and how many customers have bought this combination. A kind of usage pattern. We have different options with our data, but we do not know how to use it to make prediction.
Maybe decision trees are not the answer and we need to do something else?
Hopefully someone can help us, because we really dont know what to do.
sound to me like an association rule problem. Did you consider trying out the Borgelt nodes?
If this doesn’t help you, there are many other solutions that you can consider, depending on the size of your dataset and required accuracy (for example some Autoencoder model) - but the standard approach would be the association rule mining.
Hi @Alec,
Thank you for answering! I haven’t had succes with the association rule node before, but I dont know if my data (see picture from before) can be used in the Borgelt node?
It says that it wants a ‘transaction list’ as the input port, but how do I create this? I have a table containing of the customerIDs and the genres they bought a ticket too - but this does not work either.
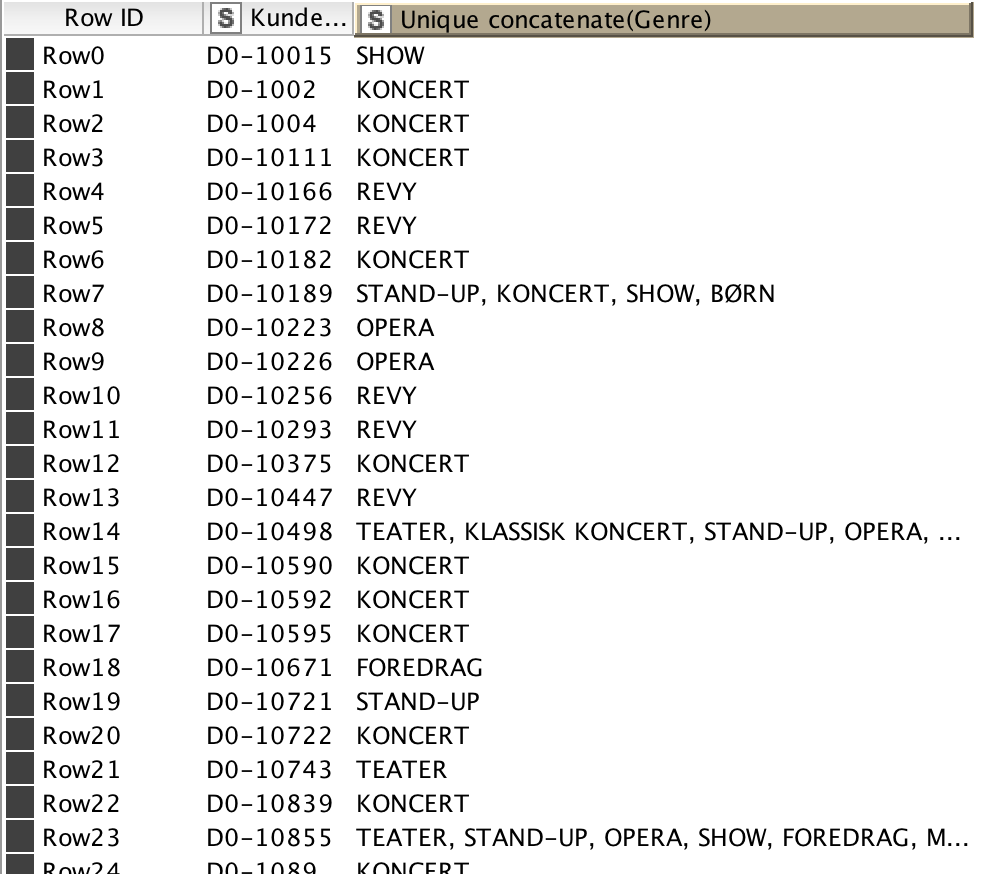
Actually, for the association rule learner, you need data formatted as “Set”. I Imagine that your “Genre” is concatenated by a GroupBy node. You can change the “Unique concatenate” there to “Set” and the Association Rule nodes should work fine.
It worked!! Now I just dont understand why I have some missing values, because I already removed them with a Row Filter in a node before GroupBy.
In addition to this I dont see all of the genres listed, is that just because they aren’t significant? And do we need to do something after the Borgelt node, because we do not know what the outcome means? :'D @Alec
About the missings: I don’t know ad hoc, as I currently have no association rule project opened…
If you don’t know what the outcome means: maybe do a 80/20 split and check how much accuracy (Scorer node) you get if you apply the rules to the test set - this tells you how good your model is. Then play around with the settings (Support, algorithm,…) to get a better fit. These are just some suggestions, what to do next depends fully on your goals.
That some genres are dropped may be because they did not meet the threshold level you set in the configuration of the node…
@Alec Now when we have the rules, we dont know how to proceed. Our goal is to make a prediction about which genres are connected to each other, or if a customer that buys A also buys B.
Do you know if it is possible to make a decision tree after the Association Rule Learner (Borgelt) node? I have tried but we can’t see if it is correct.
As you can see we are having a lot of troubles with our prediction phase, as we dont know how to use the scorer node or proceed from the Borgelt node…
let me point you to the examples server, in 50_Applications you’ll find 16_MarketBasketAnalysis and 04_LastFMRecommendations - I suggest you take these as starting point to see where to go from the Borgelt nodes.
Theoretically you can add a decision tree after the Association Rule Learner, it just depends on what you expect to get from there - I personally do not see any use case, but this might just be my inattentional blindness
To inspect the association rules, I am a big fan of combining them with network mining: each association rule is nothing else than a network graph, and by combining the two techniques, you can nicely graphically inspect the rules.
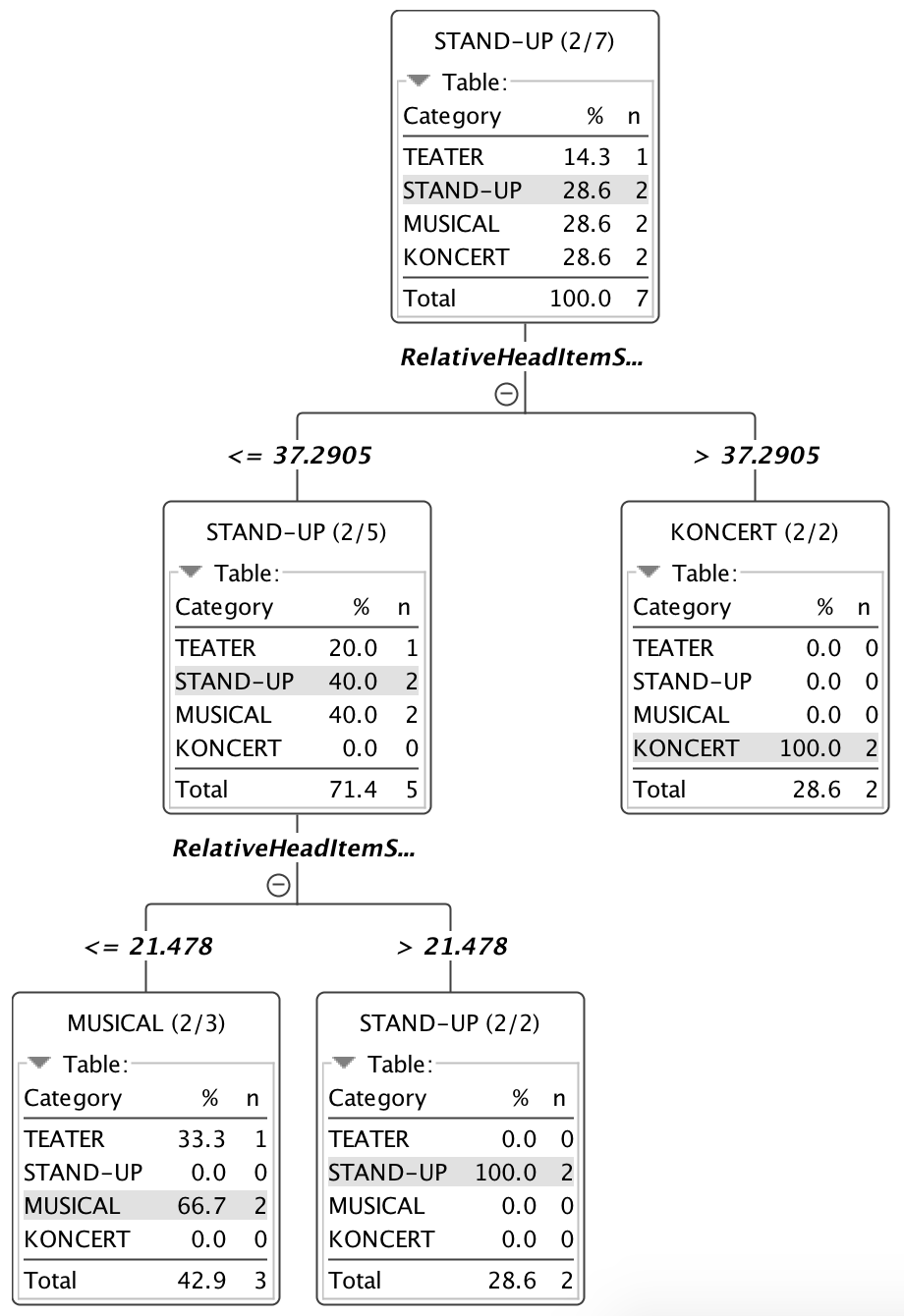
Now to your decision tree:
It’s splitting your dataset by one dimension, which is RelativeHeadItemS… It it’s above the threshold value of 37.29, you are 100% sure that the dimension is a concert, if it’s below 21.41, there is a 66% chance that it’s a musical and in between you are 100% sure to have a stand-up.