I have 2 datasets which are Training and Testing Dataset. Assuming I am to predict “Attribute Z”, my training set has “Attribute Z” but my testing set has no such column for “Attribute Z”, because we are supposed to predict it.
The overall process of my workflow is as follows (Assuming I already done the data cleaning):
Partitioned training set into 70% for training, and 30% for testing
Use the 70% from training set into a learner
Feed the output of the learner and testing set into a predictor
Issues:
Predictor gives an error about missing “Attribute Z” as input learner from testing set
Tried to append a new column named “Attribute Z” containing null value on testing set, then redo the process
Predictor now has no issues but gives 0% on accuracy
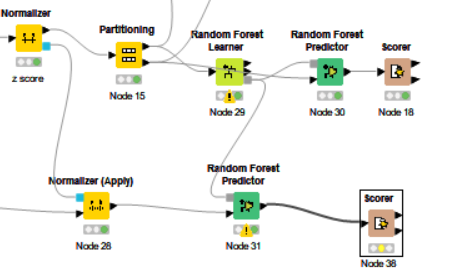
I think this is because of the null value on Attribute Z for testing set. May I know how to go about this? Below is my attached overall workflow. The first row is from training set and second row is from testing set
Without seeing the data and how the workflow is configured there’s not much we can say.
The first row is from training set and second row is from testing set
I think the terminology you’re using is confusing. From my perspective, the top row contains both training and test sets, and the second row is deployment.
Where is the error happening?
There’s a warning in the Learner node, what is it?
Can you upload the workflow and data here?
@zenzen you might have to check how you handle the normalisation. If you normalise the Target variable also you might have to do that separately since it might not be present when you deploy the workflow. Also you should check which variables have the highest impact on your model and if that is plausible or if you have a leak.
Is it possible that a not normalised version of your “Attribute Z” is also present and might take all of the explaining power?
It would be best if you could share more about your workflow or maybe the workflow itself or a log file.