Hello everyone. With the swift help I got from this platform, I now have a working flow with a loop.
BUT
My problem is, the “loop end” node stores all data in it so when my query results get bigger the “memory problem” continues to be an issue.
I wonder if I can make this loop end store only the queried data, write it to db then clear its cache for getting data of second query and so on…
Example;
select 1 from dual → result is 1 – > write 1 to db table → clear cache
select 2 from dual → result is 2 – > write 2 to db table → clear cache
select 3 from dual → result is 3 – > write 3 to db table → clear cache
For now it writes 1,2,3 to db but also stores that data in “loop end node” ans uses memory
(PS: My main query that I want to handle has 500m+ rows in total and for now I am getting “java heap space” error at last loop) (yes I can ask for a memory increase but that will be only a band aid)
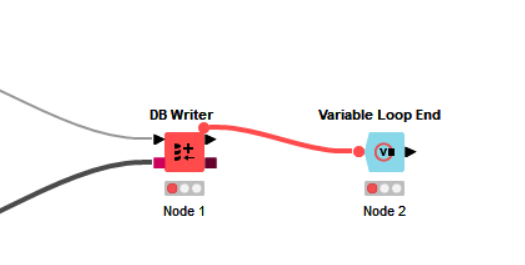
Hi @efegurtunca , if you don’t need the data from the loop, you can instead terminate the loop with a variable loop end node in place of the loop end node. Then just connect the flow-variable output port from Db Writer to the variable loop end.
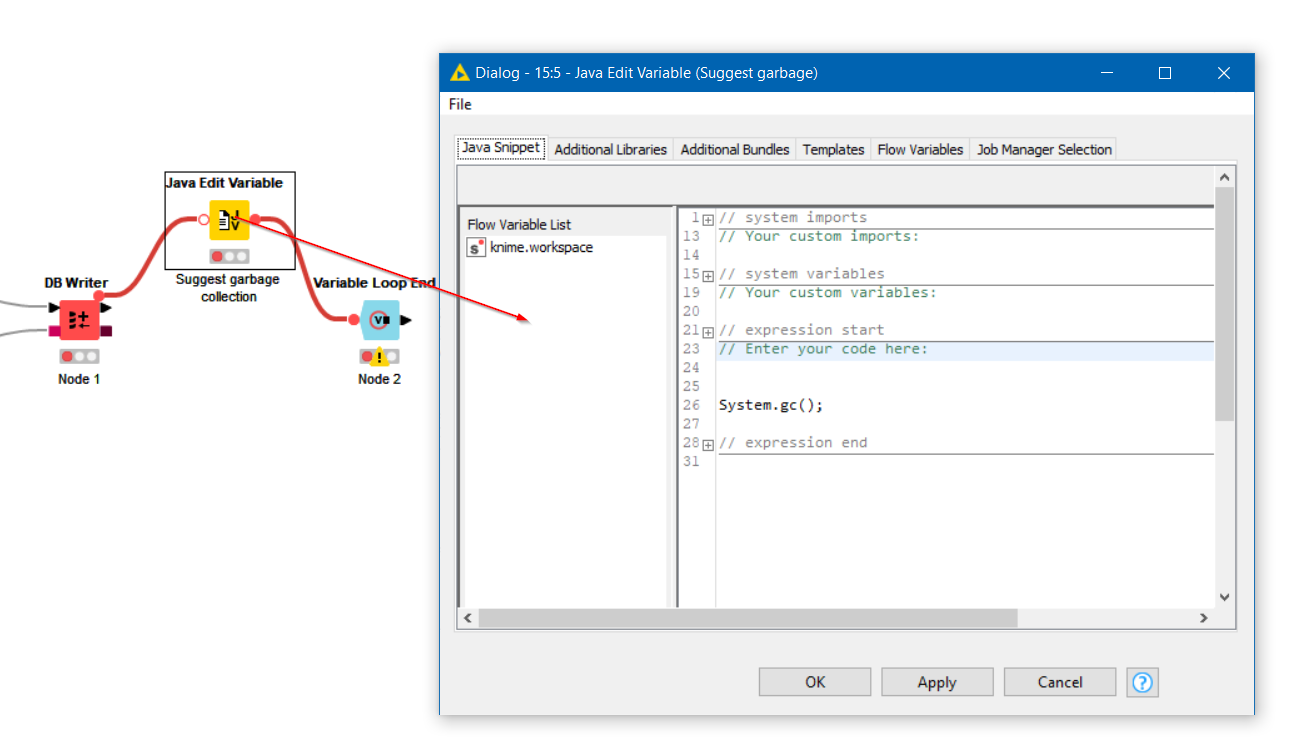
For good measure, you could also include a java edit variable node, calling System.gc(); to suggest garbage collection occurs…
As @takbb , if you don’t need the data locally, then you can use the Variable Loop End node instead.
However, why do you need to do what you are trying to do via a loop? Should a join (on the db side) not be able to do the whole operation in one shot? With the loop, you need to read and write multiple times.
Alternatively, since this is reading from one system and writing to another system, you can try to execute this in streaming mode, which will transfer the data directly between the systems without having to bring the data locally. You can check how it’s done here:
You’ll use only the database, nothing at knime at all…
You connect at database, select 2 tables, make a joiner (i hope that it is your wish), bring the information as a solid table and then put it to writ te again to the database… Of course that you can select fields too and bring only what you need to validate the information, nothing else… you can put it before or after the db joiner node…
In my earlier response I have been making the assumption that the reason for two separate DB Connections, labelled DB1 and DB2 is because this is the movement of data from one database to another rather than something that can be performed “in-database”.
The various suggestions made in this thread are certainly valid potential optimisations , but it depends on the use case (e.g. single database, or different source and destination databases) as to which options are appropriate.
Even if it is moving data to a new database, there are potentially other optimisations that can take place (e.g. can you reduce the number of calls to the DB Writer) but again without more knowledge of what is required, or whether perhaps it is being done a little less efficiently in order to reduce memory-footprint, it is difficult to say further.
the query has an output over 500m rows so running it in 1 go just destroys the memory. Thats why I am willing to wait longer to overcome memory problem
And our version doesn’t have streaming mode
Some suggested nodes does not even exist in my version (4.5.2)