CSV writer node produces a file with about more than 2 G in size for (11129 rows, 3 columns) However the input only 90M excel (11129,2 column)
the nodes I uses :
1- CSV reader
2- Molecule typecast
3- RDKITfingerprint
4-fingerprint similarity between molecules themselves (list consist of 11129 elements but in one column)
5- column filter
6- column rename
7- CSV writer
is there anyway to reduce the size of the produced excel file ?
@elsamuel , thanks for your reply
I calculated the similarity between the molecules themselves so I chose Matrix in the finger print similarity between all 11129
If you generated and kept an 11,129 x 11,129 matrix of similarity scores, it’s not surprising that the resulting file size is much larger than the starting file.
the result consists of 2columns ( the column of similarity consist of list of collection of 11129 numbers of similarity) the matrix itself still ( 11129*2)
the result consists of 2columns ( the column of similarity consist of list of collection of 11129 numbers of similarity) the matrix itself still ( 11129*2)
I don’t really understand this explanation.
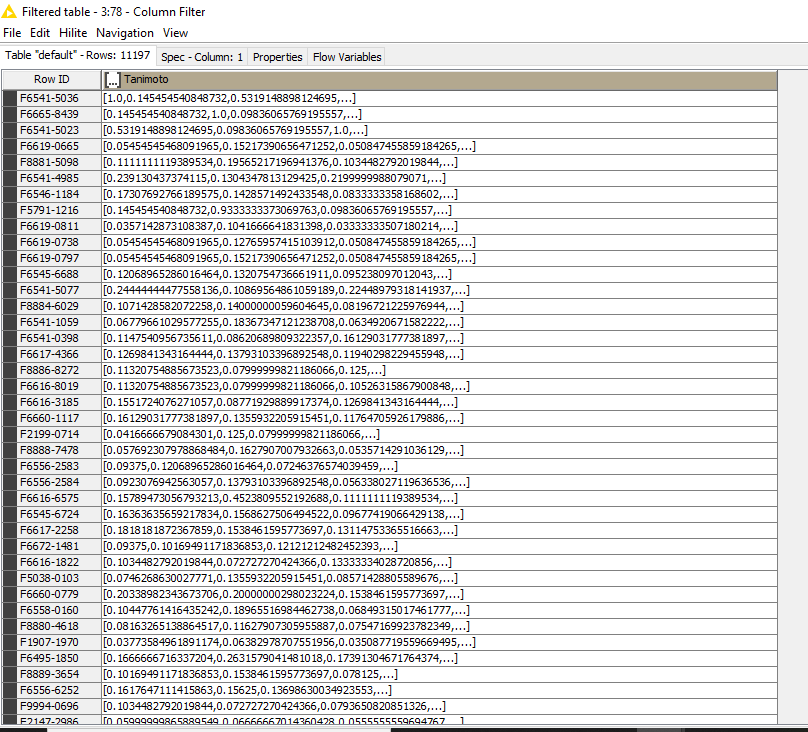
Can you share a screenshot of the output of the Fingerprint Similarity node and the Column Rename nodes?
As far as I can tell, you set up the Fingerprint Similarity node to calculate pair-wise similarities between each molecule and every other molecule, creating an 11,129 x 11,129 matrix of similarity scores.
At the end of this workflow, each cell in the similarity column contains 11,129 values.
When you export this to a csv file, it will be massive.
Excel files are compressed which can also explain why the input file is much smaller. Try writing it out with the Excel Writer. If the table contains many similar values, the written Excel file may also be much smaller than the csv file.
Hi @ah123, I’m in agreement with @elsamuel. I don’t know the nodes in question but if from your input set of 11200 rows you are generating a table where every element is linked to every other element, then you have a column consisting of 11,200 x 11,200 elements. If each of those values has a length of say 20 characters (which is about what it appears in the screenshot) , then you are asking the csv writer to produce an output which will be 11,200 x 11,200 x 20 bytes in size (plus the other associated data).
So after that it’s a simple equation…
11,200 x 11,200 x 20 = 2,508,800,000 = over 2GB
Given the file size you quoted, that doesn’t to me indicate any problem in the csv writer, as it appears to be doing exactly what is asked of it. The only way to make it write a smaller csv file is to reduce the data set that it is being asked to write…
Yes, writing to excel format instead might reduce the size a bit as an XLSX is actually ZIPped XML, but you’ll probably just be moving the problem as at some point Excel would have to deal with it and I don’t think it would be pretty…
So I think fundamentally you need to decide if what you are asking it to write is what you actually want it to write.