Hello everybody ,
I have a problem to retrieve information from a web page with an XPath node.
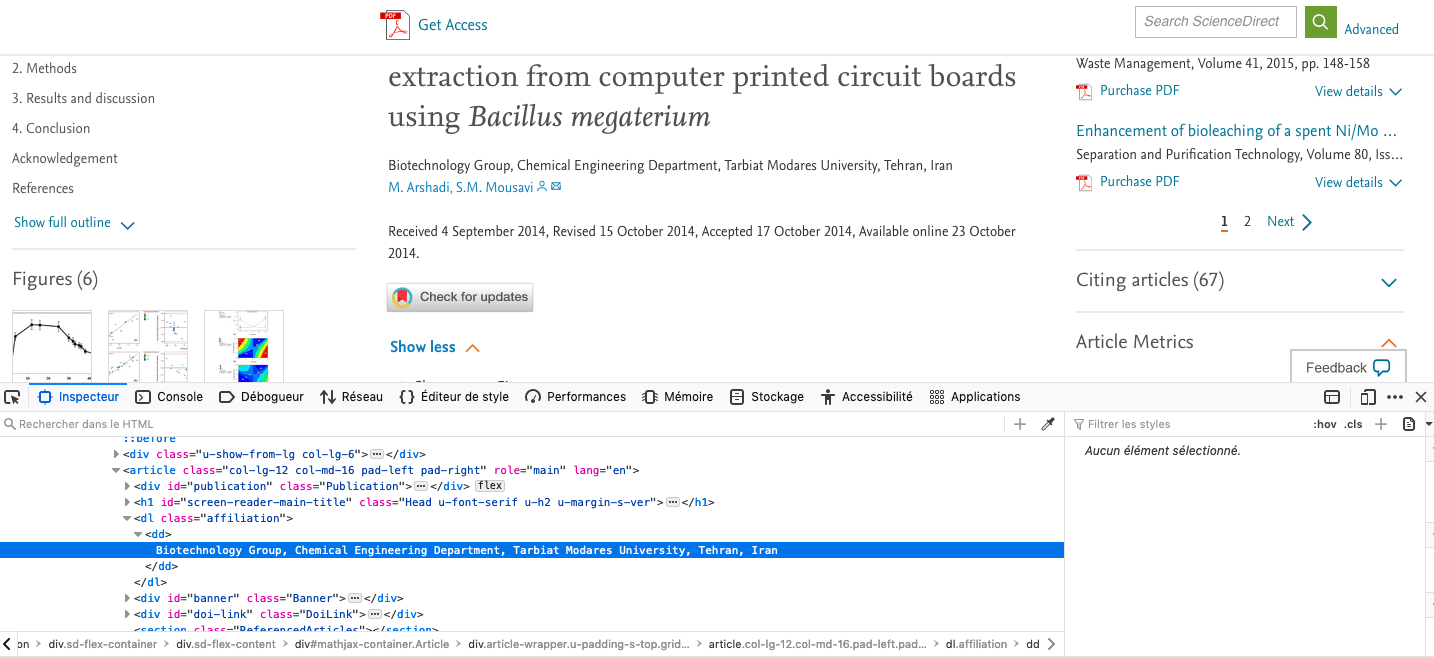
I am working on the following document: https://www.sciencedirect.com/science/article/abs/pii/S0960852414015053
I realized a classic workflow: table creator=>Http retriever=> Html parser=>Xpath
I can extract information such as title, year, abstract but I cannot retrieve the affiliation contained in the html code of the original page. It does not appear in the script of the XPath node because it is contained behind the “Show more” tag).
Does anyone please have a trick to get this data?
Thanks for your help
Best regards,
Chris