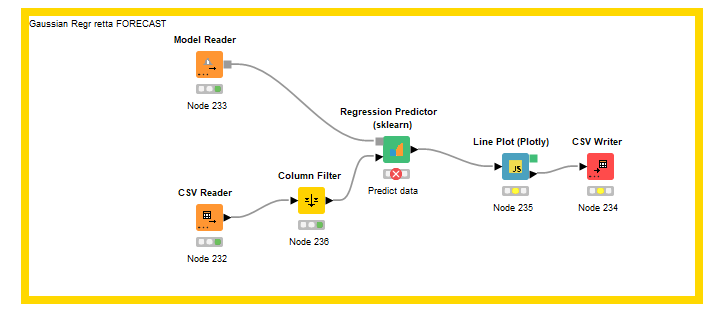
I’m trying to test some AI algorithms in Knime using scikit learn nodes.
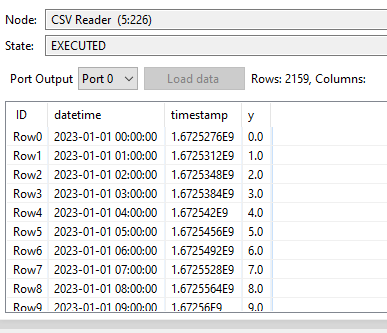
I’m trying to give as input a simple dataset where data are over a line (the equation is y=0.5*x+5 or more simple y=x).
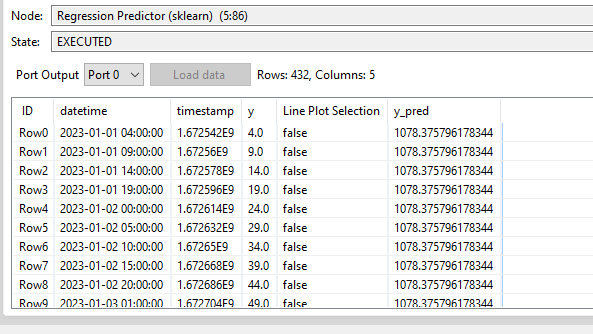
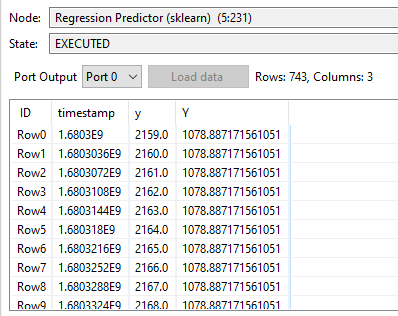
It is very strange the predicted values of target variable y are costants.
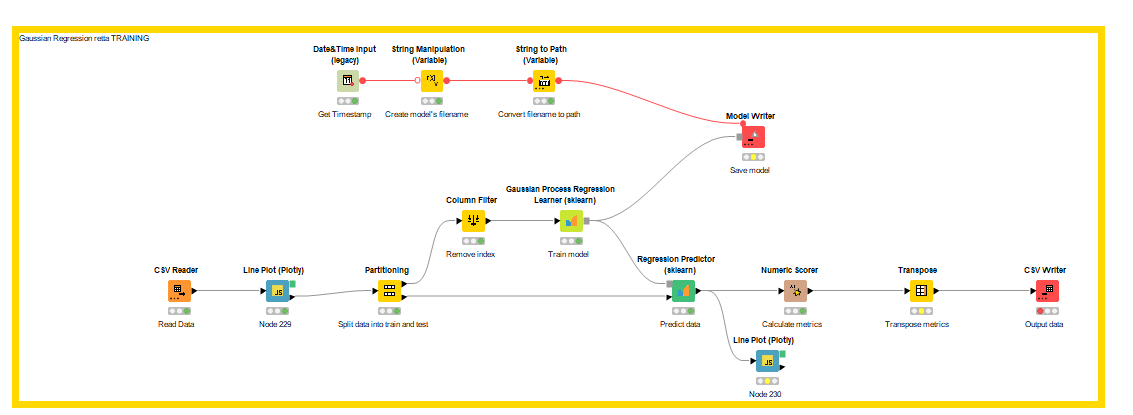
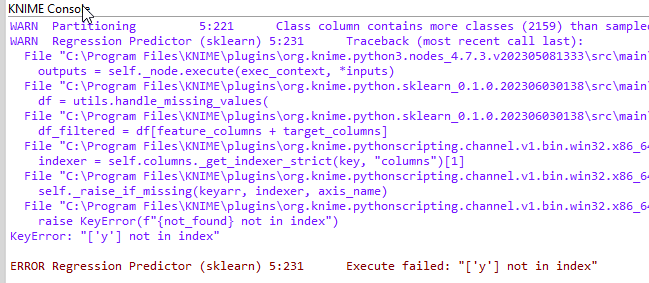
I’m saving the trained model in a binary file (Model writer node) and use it in another workflow to make inference: I have in my data only timestamps and the y values (and it is stange because without it I have an error).
In this case I want to predict y variable…but it predicts constant values.
If in the input file I give timestamps and y variable it works (and it predicts constant values), if the input file trere are only timestamps the node fail.
In this case the predictor give an error: it does not find the target variable y:
Someone can help me to understand what is the problem? There is some error in my data?
Attached there is my workflow with different input data. retta_gaussian.knwf (113.6 KB)
@mlauber71 I read the material suggested…but any of this solve my problem.
In this moment I’m using a dummy variable using the node category to number and it seems it works…but I think this is not a good solution.
You see attached my actual solution. gaussian_forecast.knwf (399.0 KB)
If you have another idea…they are welcome.
Thanks.
Hi @giuseppeR
I took a look at your workflow, I think the issue here is related to your kernel choice.
A little background: the gaussian process regression is a non parametric model, and behaves a lot differently than most Machine Learning models we talk about. Instead of fitting an equation with parameters over the input features to generate the output features a probability distribution is generated and used for prediction. This probability distribution is fit by magic that I won’t elaborate on here and the assumption that similar input data should have similar output data.
The kernel function choice is used to define what “similar” means. In your workflow the learner node is configured to use the White kernel, this kernel defines two data points as either completely the same if they’re identically or completely different if they’re different.It’s binary.
Because all of your data points are unique they’re all marked as being equally similar to each other and this forces the model to generate a predictive distribution that is just the mean value of the training set.
I’d recommend swapping your kernel to either the default (I think that is a modified RBF) or the RBF which is a good all purpose kernel when working with smooth functions.
In summary: Swap your kernel to either default or RBF and it should work fine.
Oh - and also you’ll probably want to normalize your timestamp column, being such huge numbers close together seems to be throwing something off as well. Probably in the same way as the white kernel.
You can use the normalizer on the train set and the normalizer apply on the test set.