Hello everyone,
I’m trying to read a 1.4 GB xml file with the XML Reader. Unfortunately it doesn’t work. I get the error message “Execute failed: Java heap space”
My laptop only has 16 GB RAM, but it doesn’t work for a colleague with 32 GB RAM either.
But if I try to read the file with the File Reader (Complex Format) node it works, but I can’t use an XPath node afterwards.
Is there a bug in the XML Reader? Does anyone have a solution for me?
Have you tried it at your colleagues 32 GB laptop with more RAM allocated (e.g. 28 GB in the ini)?
And if it works with the “File reader (complex format)”: Do you get a XML- or a string result? If it is string, you can try the “String to XML” or “Column to XML” node afterwards and use the XPath afterwards.
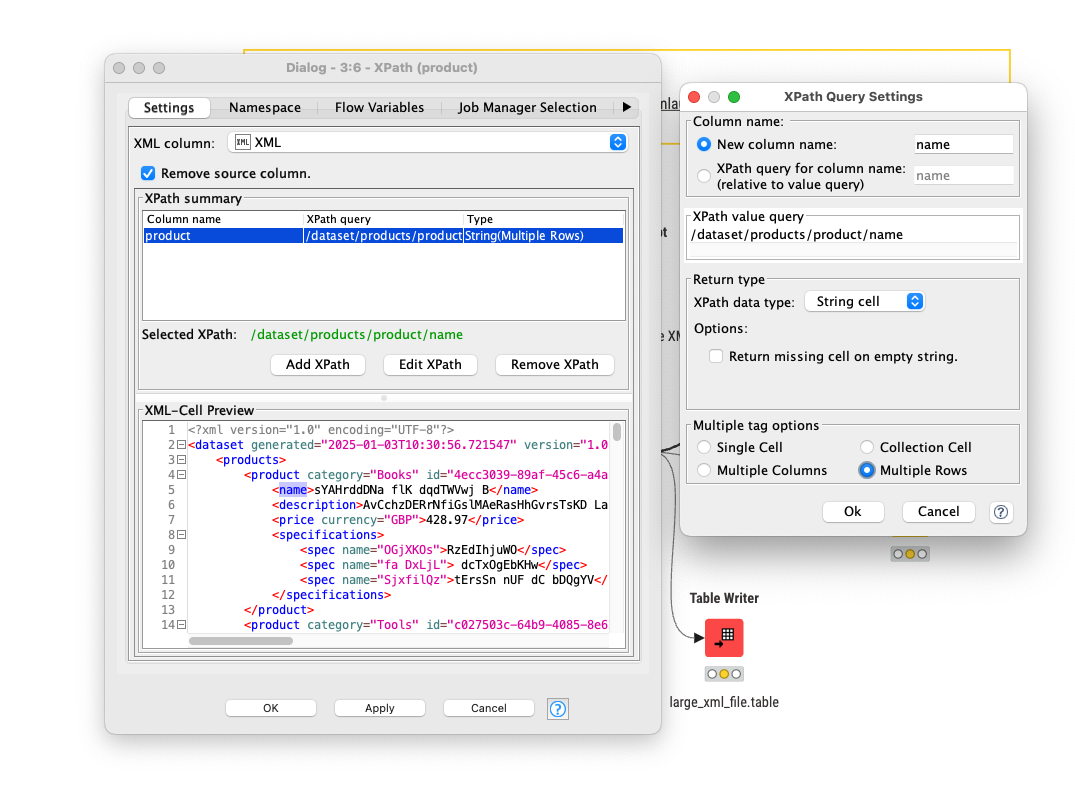
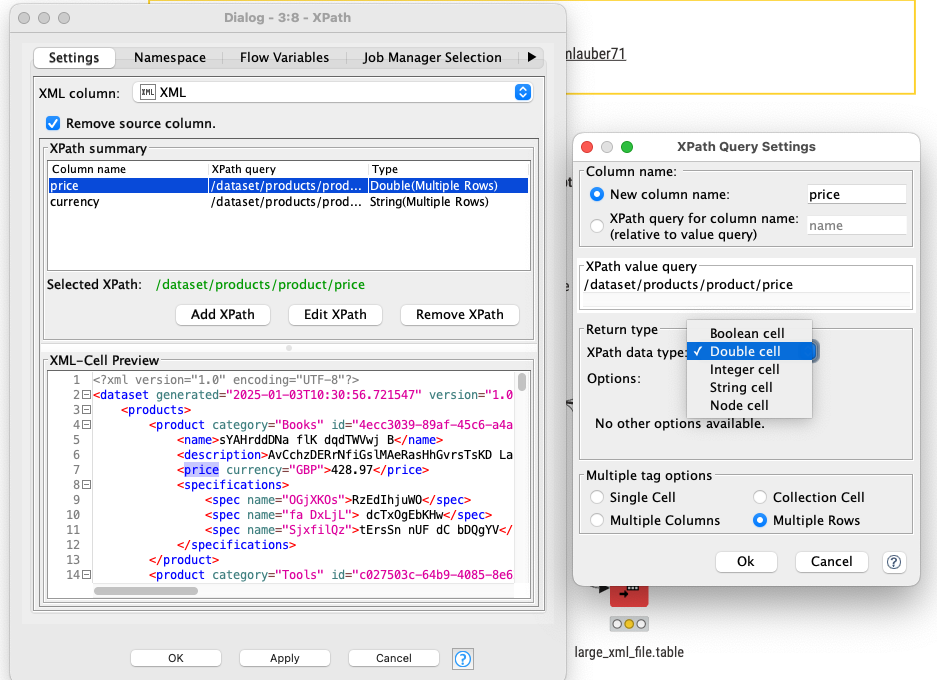
If possible, use the integrated “XPath query” option in the XML Reader node to split your document into smaller chunks - you can then process them row-wise with subsequent nodes. This is different from reading one huge document into a single data cell and then chunking it with a following XPath node, as each document cell’s DOM must fit into memory.
Hello Philipp,
I wanted to try that, unfortunately I don’t know exactly how to use the XPath query here. Unfortunately I don’t have the knowledge about this.
Can you perhaps explain this to me with an example?
Hello,
I discovered an error in my XML file. After removing the faulty line, I was able to use the XPath filter in the XML Reader Node. This means I can now read the large file and process it further.
Thanks again to everyone for their support.