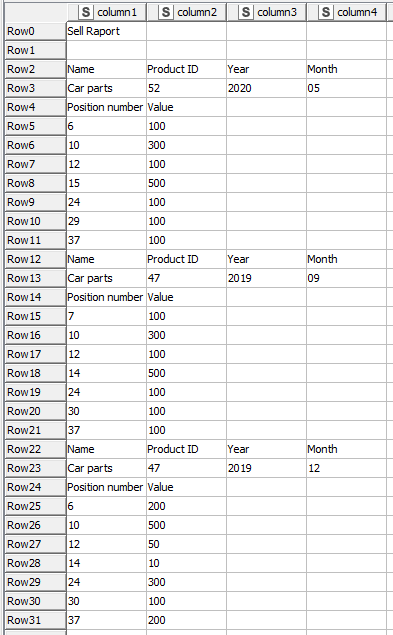
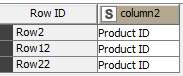
The source data is random, every raport have different lenght, different “Product ID”, so i need to read everything from this file, i can’t create dictionary. I have manage to pull rows ID where new product starts:
From here i don’t know what to do. Becouse now i need to read everything from Row2 to Row12 , next from Row12 to Row22 e.t.c. I tried to use “Chunk Loop Start” and “Rows per chunk” set to 2, but that way i have rows 1-2, 3-4, 5-6, and i need 1-2, 2-3, 3-4.
Someone have any idea how to do this ?
i would suppose to identify for each section start row and end row. But i personally wouldn’t use rowid as identifier. I would prefer rowindex (using math formula) to get numbers, which you can then use in a filter node.
If you could upload an example file (.xls) it would be easier to come up with a suggestion.
I found solution. I used “Windows Loop Start” node, i set “window size” to 2 and “step size” to 1. Connected output data to “Rule-based Row filter” and from here was easy
So topic can be closed.