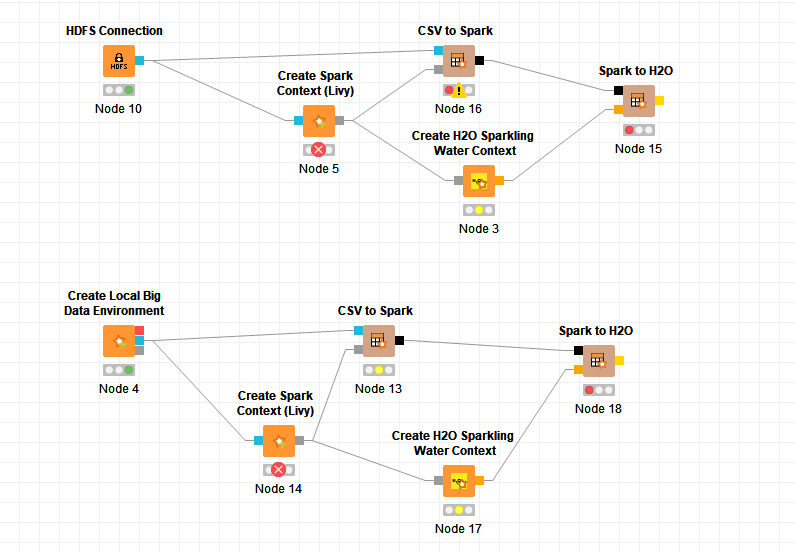
I’m trying to create a spark context in a cluster with Livy that I have running in a node of said cluster, but I’m having difficulties. I tried a couple things(you can see it in the image), to create a local big data context and feed it to the Livy node and to make a HDFS connection and feed that to the Livy node. Neither works. Even though both nodes for the big data environment required by Levy run properly, the Levy node fails with different errors for both cases. I’m using the same address in both Livy nodes.
For the HDFS connection it gives the error:
ERROR Create Spark Context (Livy) 0:5 Execute failed: Connection refused: no further information (ConnectException)
For the Local Big Data Environment:
ERROR Create Spark Context (Livy) 0:14 Execute failed: java.lang.IllegalArgumentException: Pathname
/C:/Users/TMDONG~1/AppData/Local/Temp/.knime-spark-staging-f3abd5de-70e0-4081-93be-0f2c0165d489/fcb4abf6-1de1-46e5-b217-6adce5b6ef26 from hdfs://bda01.vm.altran:8020/C:/Users/TMDONG~1/AppData/Local/Temp/.knime-spark-staging-f3abd5de-70e0-4081-93be-0f2c0165d489/fcb4abf6-1de1-46e5-b217-6adce5b6ef26 is not a valid DFS filename.
org.apache.hadoop.hdfs.DistributedFileSystem.getPathName(DistributedFileSystem.java:243)
org.apache.hadoop.hdfs.DistributedFileSystem$8.doCall(DistributedFileSystem.java:537)
org.apache.hadoop.hdfs.DistributedFileSystem$8.doCall(DistributedFileSystem.java:534)
org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
org.apache.hadoop.hdfs.DistributedFileSystem.create(DistributedFileSystem.java:548)
org.apache.hadoop.hdfs.DistributedFileSystem.create(DistributedFileSystem.java:475)
org.apache.hadoop.fs.FileSystem.create(FileSystem.java:1118)
org.apache.hadoop.fs.FileSystem.create(FileSystem.java:1098)
org.apache.hadoop.fs.FileSystem.create(FileSystem.java:987)
org.apache.hadoop.fs.FileSystem.create(FileSystem.java:975)
org.knime.bigdata.spark.core.livy.jobapi.StagingArea.createUploadStream(StagingArea.java:122)
org.knime.bigdata.spark.core.livy.jobapi.StagingAreaUtil.lambda$0(StagingAreaUtil.java:39)
org.knime.bigdata.spark.core.livy.jobapi.LivyJobSerializationUtils.serializeObjectsToStream(LivyJobSerializationUtils.java:147)
org.knime.bigdata.spark.core.livy.jobapi.StagingAreaUtil.toSerializedMap(StagingAreaUtil.java:37)
org.knime.bigdata.spark2_3.base.LivySparkJob.call(LivySparkJob.java:106)
org.knime.bigdata.spark2_3.base.LivySparkJob.call(LivySparkJob.java:1)
org.apache.livy.rsc.driver.BypassJob.call(BypassJob.java:40)
org.apache.livy.rsc.driver.BypassJob.call(BypassJob.java:27)
org.apache.livy.rsc.driver.JobWrapper.call(JobWrapper.java:57)
org.apache.livy.rsc.driver.BypassJobWrapper.call(BypassJobWrapper.java:42)
org.apache.livy.rsc.driver.BypassJobWrapper.call(BypassJobWrapper.java:27)
java.util.concurrent.FutureTask.run(FutureTask.java:266)
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
java.lang.Thread.run(Thread.java:745) (RuntimeException)
Using the HDFS connection it doesn’t seem to be able to connect to Livy at all, not sure why, using the Local Environment, it can, but for some reason it shuts down. It seems to be forcing a local path of mine to the Server… I’ll also send the Livy logs
Hi @TomasCardoso,
The Local Big Data Node is not supposed to be used with the Livy node. It creates a Pseudo HDFS on top of your local file system. Your Livy Cluster cannot use this.
The Livy node expects a RemoteFileSystem connection, using one of the HDFS/HttpFS/WebHDFS/Amazon S3 nodes is the correct way.
However the HDFS Connection seems do be misconfigured. If you open the HDFS Connection and hit the “Test Connection” button, do you see the same error?
It seems the connection to your HDFS is refused. Could you check the settings? Did you enter the correct hostname that runs the HDFS Nameserver? Is the port correct?
(Looking at the Livy logs, it seems the service is running, but you should double-check that too)
Hey, sorry for the late reply.
Alright, the connection with HDFS really was failing. It is working now but the create spark context Livy does not work. It fails with:
(Livy) 0:5 Execute failed: org.apache.hadoop.security.AccessControlException: Permission denied: user=livy, access=EXECUTE, inode="/user/hdfs":hdfs:hdfs:drwx------
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:399)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:315)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:242)
at org.apache.ranger.authorization.hadoop.RangerHdfsAuthorizer$RangerAccessControlEnforcer.checkDefaultEnforcer(RangerHdfsAuthorizer.java:589)
at org.apache.ranger.authorization.hadoop.RangerHdfsAuthorizer$RangerAccessControlEnforcer.checkPermission(RangerHdfsAuthorizer.java:350)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:193)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1857)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1841)
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1800)
at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.resolvePathForStartFile(FSDirWriteFileOp.java:315)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2407)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFile(FSNamesystem.java:2351)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.create(NameNodeRpcServer.java:774)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.create(ClientNamenodeProtocolServerSideTranslatorPB.java:462)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:524)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1025)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:876)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:822)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2682)
Hey @TomasCardoso,
in order to use the Spark nodes in KNIME it is necessary that KNIME can write temporary files into the HDFS. The Error you are seeing here indicates the default directory that is used ("/user/hdfs") does not have the correct permissions (hdfs:hdfs:drwx------). Only the hdfs user is allowed to read and write there.
Please enter a staging directory that the user livy is allowed to write in. You can set it in the advanced tab of the “Create Spark Context (Livy)” node in the option “Set staging area for Spark jobs”.
Alright, I managed to get a Spark context going. I now wanted to use H2O in this spark context using the H2O Sparkling Water Context, but I get an error:
2019-08-14 12:05:47,200 : DEBUG : KNIME-Worker-13 : %J : Node : Create H2O Sparkling Water Context : 0:3 : Execute failed: org.eclipse.jetty.server.Server.setSendServerVersion(Z)V (NoSuchMethodError)
java.lang.NoSuchMethodError: org.eclipse.jetty.server.Server.setSendServerVersion(Z)V
at water.AbstractHTTPD.makeServer(AbstractHTTPD.java:203)
at water.AbstractHTTPD.startHttp(AbstractHTTPD.java:208)
at water.AbstractHTTPD.start(AbstractHTTPD.java:96)
at water.init.NetworkInit.initializeNetworkSockets(NetworkInit.java:87)
at water.H2O.startLocalNode(H2O.java:1523)
at water.H2O.main(H2O.java:1990)
at water.H2OStarter.start(H2OStarter.java:21)
at water.H2OStarter.start(H2OStarter.java:46)
at org.apache.spark.h2o.backends.internal.InternalH2OBackend.init(InternalH2OBackend.scala:121)
at org.apache.spark.h2o.H2OContext.init(H2OContext.scala:130)
at org.apache.spark.h2o.H2OContext$.getOrCreate(H2OContext.scala:401)
at org.apache.spark.h2o.H2OContext$.getOrCreate(H2OContext.scala:417)
at org.apache.spark.h2o.H2OContext.getOrCreate(H2OContext.scala)
at org.apache.spark.h2o.JavaH2OContext.getOrCreate(JavaH2OContext.java:238)
at org.knime.ext.h2o.spark.spark2_3.H2OSparkContextConnector2_3.createH2OContext(H2OSparkContextConnector2_3.java:117)
at org.knime.ext.h2o.spark.spark2_3.job.H2OSparkCreateContextJob.runJob(H2OSparkCreateContextJob.java:70)
at org.knime.ext.h2o.spark.spark2_3.job.H2OSparkCreateContextJob.runJob(H2OSparkCreateContextJob.java:1)
at org.knime.bigdata.spark2_3.base.LivySparkJob.call(LivySparkJob.java:91)
at org.knime.bigdata.spark2_3.base.LivySparkJob.call(LivySparkJob.java:1)
at org.apache.livy.rsc.driver.BypassJob.call(BypassJob.java:40)
at org.apache.livy.rsc.driver.BypassJob.call(BypassJob.java:27)
at org.apache.livy.rsc.driver.JobWrapper.call(JobWrapper.java:57)
at org.apache.livy.rsc.driver.BypassJobWrapper.call(BypassJobWrapper.java:42)
at org.apache.livy.rsc.driver.BypassJobWrapper.call(BypassJobWrapper.java:27)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Do you think some libraries are missing in the cluster or something?
Sorry for necroing this post. But I see that there is a parameter user=livy in the create Spark contect (Livy) node. Is there a way to change this user to someone else? If so, where in the configurations do I need to make this change?
I guess you mean the parameters from Spark Context Port or where to you find the parameter? Livy is the user running the Livy Server and the Spark session. Are you running Spark in YARN cluster mode? One option is to setup a secured cluster with Kerberos and Livy running the jobs using impersonation.