Hi,
I’m trying to extract information from a price search engine for medicines, so the name of the pharmacies, the respective price etc. I think Knime has found the names of the pharmacies now, but unfortunately I can’t manage to export the found information into a table.
The Extract-Attribute-Node doesn’t work correctly, because I probably chose the wrong settings. It would be great if someone could help me with this.
Then use further Find Elements nodes and extract the individual fragments (e.g. the title “eurapon.de”). For the title you can use the CSS selector .name which will give you the <a> tag. Then extract the text content using Extract Outer/Inner HTML.
If you want to extract further information (e.g. price, rating, delivery conditions), use a further Find Elements and Extract Outer/Inner HTML combination.
thank you very much for your super fast answer. Your explanations are very helpful, especially in understanding how scraping a web page works.
I tried your workflow, but to my shame I have to confess that I am facing the same problem again: How do I get the data in table form? Could you help me there again?
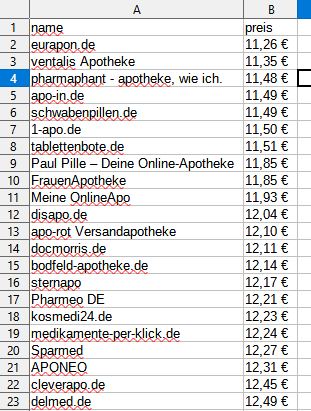
I have attached a screenshot of how I imagine it in the end (in this case only with name and price). So I think I can handle the table manipulation, it’s just a matter of getting the data into a table in the first place
thanks again for the quick answer and the great help!
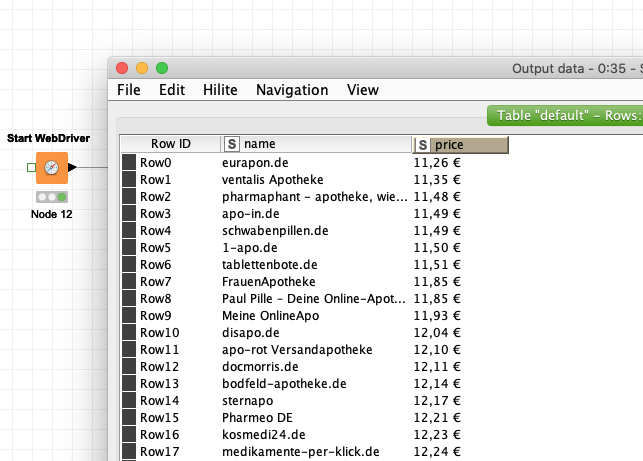
Now it works or rather I had overlooked in your previous solution that the temporary table has more columns on the right - embarrassing, embarrassing .
One more question of understanding: Could it be that it is always quite a fiddle to identify and correctly address the individual elements on the respective web pages?
You are working with CSS Selector in this respect. I am absolutely new in this area and had used the following description and XPath. But that didn’t work very well . In a previous version of the workflow I had also tried with XPath to get rid of the cookie, but that didn’t work either (that’s where the wrong label came from on the one node).
And the query .price .single was also very helpful, in the same way I could now get the shipping information (.price . shipping)
getting the selector right can definitely be fiddly, but you’ll eventually establish some routine
A few tips:
You can automatically generate a selector by double clicking on a line in the preview area.
Even more convenient: Use the “Select” button beside the input field, go to the browser window and move your mouse cursor over the page and click at the element which you want to extract:
In current versions of the Selenium Nodes, CSS selector is generated, whereas in older versions it was an XPath, which is mentioned in @armingrudd’s blog post which you linked above. Both basically work, however we think that CSS is more intuitive (it doesn’t require to specify complicated namespace constructs)
The generated CSS expressions are always very “restrictive” – this means, that they only match the actual element which you clicked at. Often you’ll want them to be more generic (in your case to extract all the .apotheke items and not just one – at this point you’ll need to look at the selector and the DOM structure and modify the query accordingly. It hard/impossible to give a general advice here, this is trial and error (you’ll want to try to remove “wrapping” classes or nth-child attributes form the query to make it more “general”)

 .
. . In a previous version of the workflow I had also tried with XPath to get rid of the cookie, but that didn’t work either (that’s where the wrong label came from on the one node).
. In a previous version of the workflow I had also tried with XPath to get rid of the cookie, but that didn’t work either (that’s where the wrong label came from on the one node).
