I have this information from a database, which is too messy.
These data are information of people and their families.
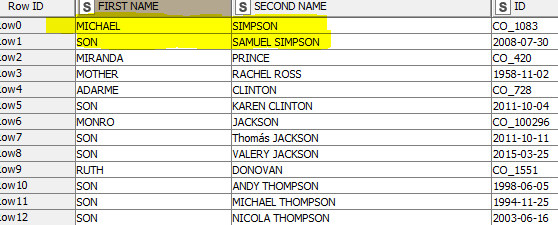
The problem is that the information looks like this:
For example, in yellow
Featured, Michael Simpson has a son (Samuel Simpson), this son appears below his father Michael. In this case it will only be an only child, but as you can see in the image, there are more cases with more than one associated family member.
I need to group this information, so that I can analyze the number of family members per person, and discriminate between family members, whether it is a son or a mother …
Can someone help me with this? I don’t know how I can do it.
you can try following. First in new column assign each family unique ID. To do this you can use Rule Engine node with following expression:
NOT $FIRST NAME$ IN ("Son","Monther") => $$ROWINDEX$$
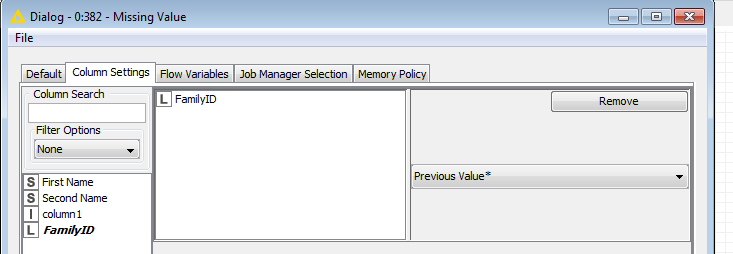
followed by Missing Value node with Previous Value configuration on new column.
Further on you can use Rule Engine node again to have relation in new column. Using following expressions you will get missing values where there are no relation:
Above you can see the employee, and below you can see his relatives,
That is, in the First Name column, there are both the employee’s names and the type of family member, likewise, in the second name column, there is both the employee’s name and the relatives’ names.
I need to manage to organize the base, so that it looks like this:
first Rule Engine will give you missing value (denoted in KNIME with red question mark) where there is relationship (Son or Mother in your case). With Missing Value node you can replace those missing values with option Previous Value (“replaces missing values with the last encountered non-missing value in the column it is configured for”). Here is configuration of Missing Value node under assumption that Rule Engine created column FamilyID: