Hi Burkhard,
You are right as to the idea behind the benchmark nodes - they are designed to measure execution times and optionally memory usage during workflow execution. A little more detail…
- The nodes are KNIME loop start/end nodes, so they need to obey the usual loop rules - i.e. matching start/end pairs (this is why your second example fails - more on that later)
- By default, they only run the loop body once - you can change this to get a better sense of average performance - in particular Java often has a ‘warm-up’ time on the first use of something - this may or may not show up in the timing execution on multiple depending on exactly how the JVM (Java Virtual Machine) decided to go about things
- The Benchmark Start nodes (1port, 2 port, 3 port and Flow Variable versions) simply pass the input table straight through - they just act as a marker, saying “Start timing now”. This is also where you can do some setting up of options such as number of iterations, and whether you eventually report the individual node timings within the loop - this option might be useful for you if you want to pin down where in your workflow the slowest parts are
- The Benchmark End nodes in all versions (again 1 port, 2 port, 3 port and Flow variable) pass through the tables from the inputs, but also add as the first two outputs a flow variable port - this has the summary information - number of executions, average, min and max execution times etc as flow variables, and a data table containing the timing information
- You can mix and match and of the start/end nodes, so a 3 port start, for example could pair with a flow variable end.
Now to the specifics of your example 2…
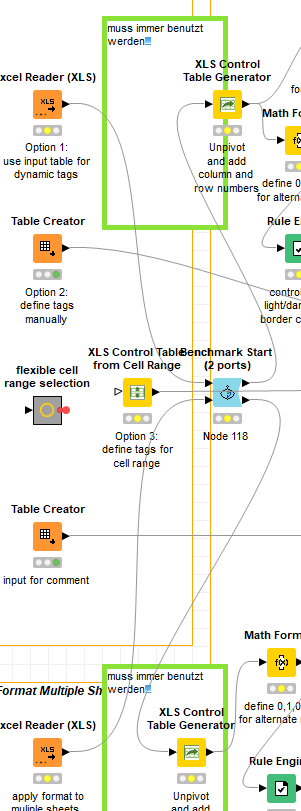
You have 4 benchmark starts and 2 ends (and a lot of stuff in between - that’s fine!)
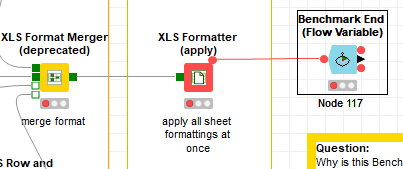
I think the Ends are easy to solve - as far as I can tell, you want to end the timing after the ‘XLS Formatter (apply)’ node - in which case, you are probably best to use a ‘Benchmark End (Flow Variable)’ node, attached to the hidden variable output port, as shown here:
As for the ‘Starts’, that’s a bit more complicated… (because we dont have a 4-port start - more on that at the end…)
I’m guessing you are trying not to include the time for the 2 excel readers to do their stuff?
Yes… I want to exclude the Excel readers…
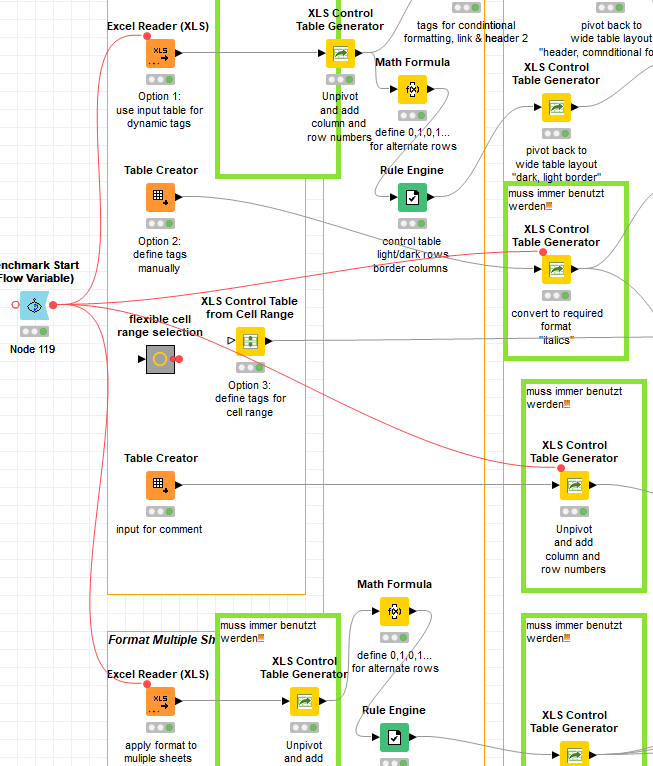
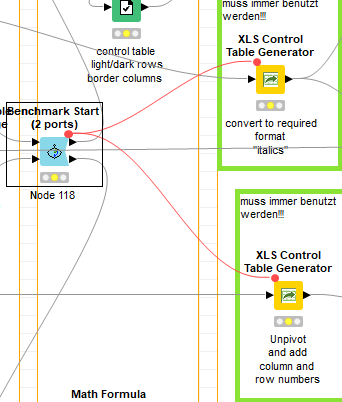
OK, use a Benchmark Start (2 Port) node, with the 2 excel readers feeding into it, replacing the 2 benchmark start nodes ‘Node 103’ and ‘Node 115’, and remove the other 2 benchmark starts immediately downstream of the Table Creator nodes:
The caveat here is that the two ‘XLS Control Table Generator’ nodes will not be included in the timing - if you want that too, then use the hidden flow variables to connect them too the output side of the Benchmark Start:
Modified version of 2nd example (141.4 KB)
No… I don’t mind including the Excel readers…
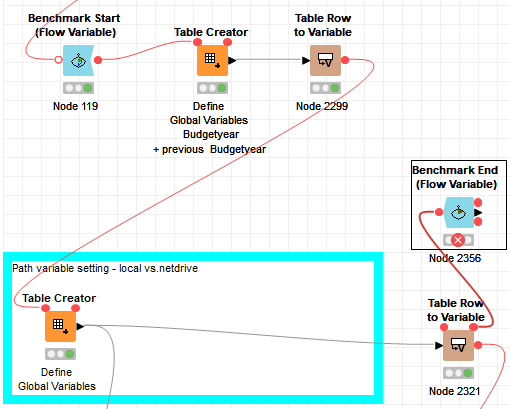
This is actually a bit lot easier…
The Benchmark Start (Flow Variable) node doesnt need an input, so you can put it before all the nodes to time and connect via their optional input ports:
Modified version of 2nd example (142.7 KB)
Hopefully that makes some sense…?
Finally, I mentioned the lack of a 4-port node… I’ve been doing some work reworking some of our other flow control nodes to take advantage of the new configurable ports feature. I plan to update the benchmark nodes similarly to the ‘Multiport Loop End’ node we released recently, so a single node for each of start and end will be able to be configured with multiple ports of different types…
Yours,
Steve