In my dataset there is a column called “SmokesPerDay”. I am looking to extract a number from this column, as there are many entries with additional text qualifications.
I am asking two questions:
How do I identify an entry which starts with " like this one?
“changes on the day”
I tried using the following expression - $08b.SmokesPerDay$ MATCHES "["]{1,}.*" - but it greys out on error checking. Also tried an escape character - $08b.SmokesPerDay$ LIKE "\"*" - but also no good.
As you can already tell, I am unskilled in Regex (as with many coding issues), but how do I select the entries where the first 2 characters are numbers? (and yes, I realise that if I can do this, my first question is irrelevant, but I’ll include it anyway.)
It could be that what you copied/pasted here is not exactly how they are in reality, but if that was the case, then what you pasted does not satisfy your condition simply because the quotes that you are evaluating are different.
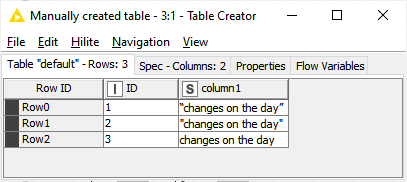
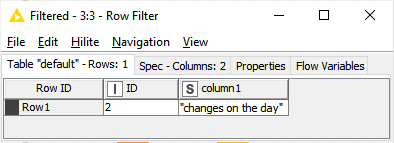
Here’s a sample data I worked with:
And the first row, with ID = 1 is what I copied from you.
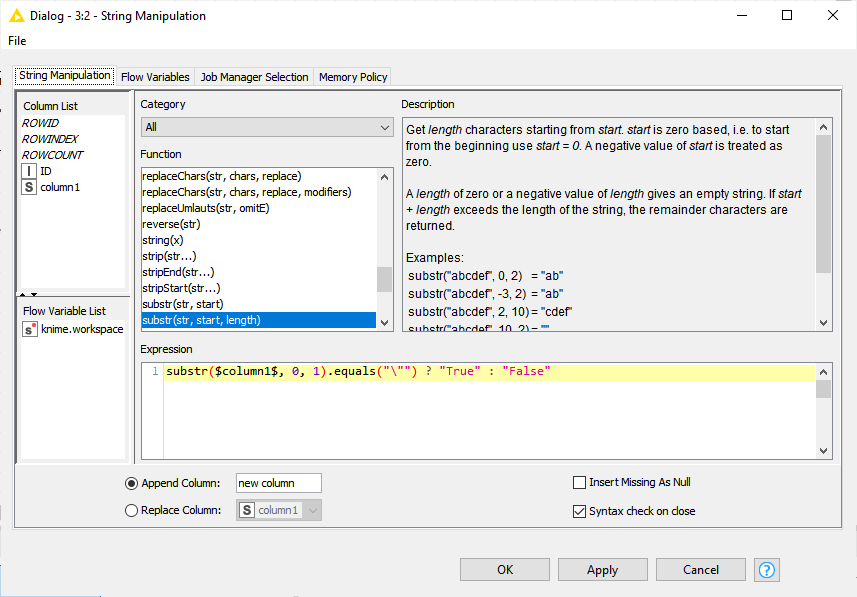
If I do the check via String Manipulation using this expression, I am able to get the expected results:
(This expression is checking if the first character is a quote ", in which case it will return “True”, otherwise will return “False”)
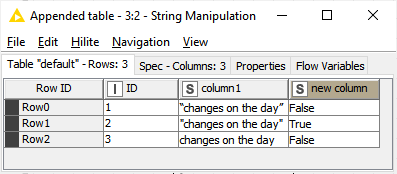
As expected, only the row with ID = 2 will match as it contains the quotes that we are looking for (Row ID = 1 has different quotes, that’s what I copied and pasted from your post)
With the Rule-based Row Filter, somehow, Knime does not seem to like the statement LIKE "\"*". It’s ok to do LIKE "\t*" for example, but it gives an error if we do LIKE "\"*". It looks like we’d have to use regex via the MATCHES statement as a workaround.
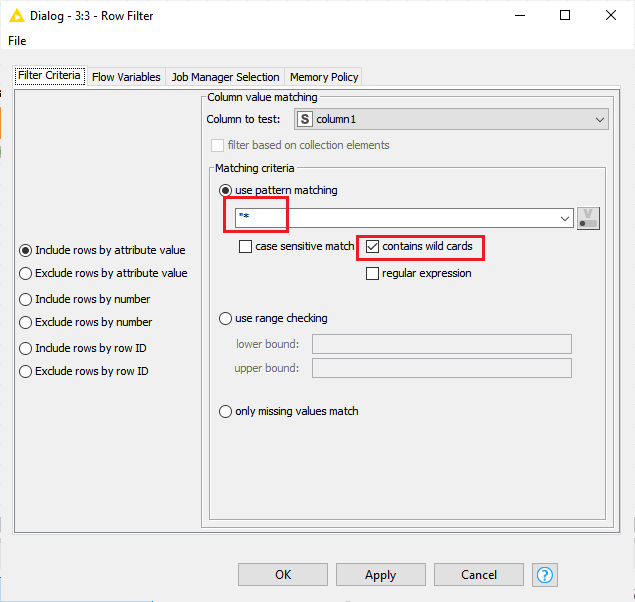
Any reason why you need to use the Rule-based Row Filter instead of the Row Filter node?
As for your 2nd question, you can do this via the Rule-based Row Filter indeed with this expression: $column1$ MATCHES "[0-9][0-9].*" => TRUE