well in fact there is a way …
You can use the HIVE function of an external table from the local Big Data environment and point it to a folder that contains all the CSV files you want to aggregate. And then you can refer to this external table and convert that to a regular table. All the CSV files will have to have the same structure and you will have to specify the structure.
Please not I have used “|” as a separator in the 3 sample files.
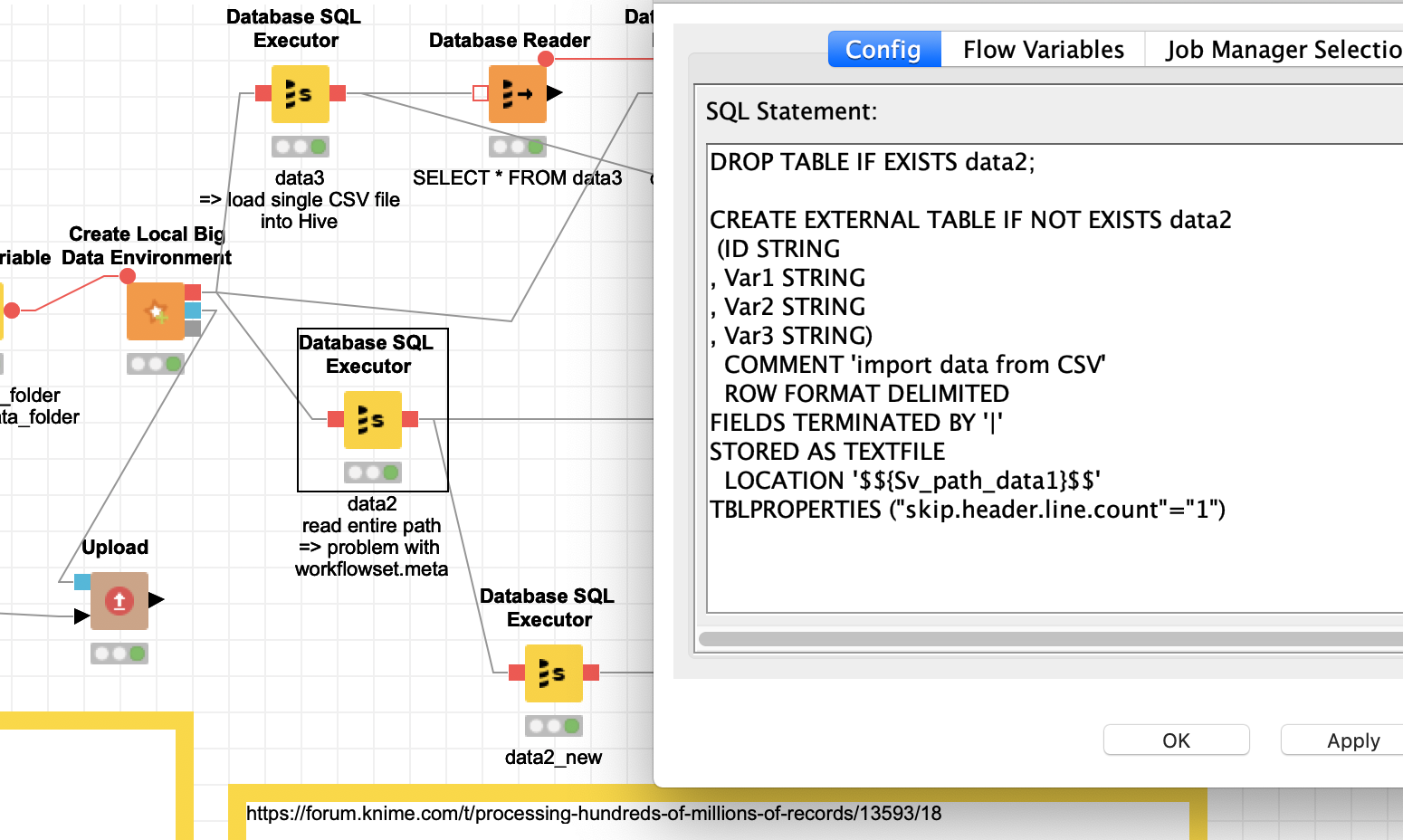
OK and here come the quirks:
- the HIVE version KNIME is using does not respect the settings to skip the initial row (
TBLPROPERTIES ('skip.header.line.count'='1', 'skip.footer.line.count'='4')) and also not the setting for the footers - if you use a folder that is within the KNIME workspace it will contain a workflowset.meta file that will also be read and imported
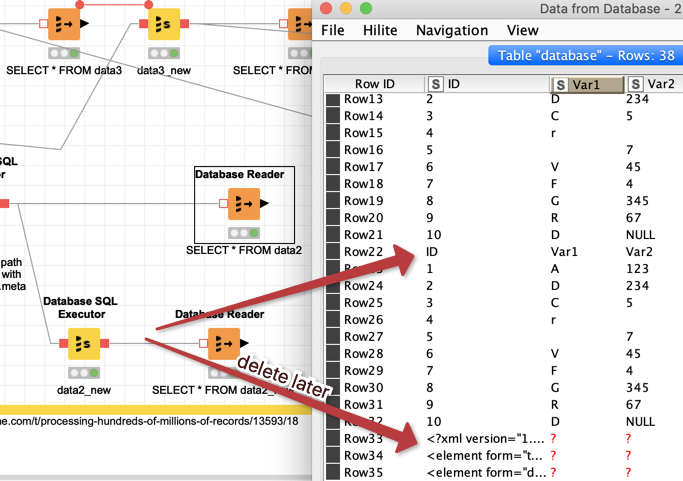
So if you can live with having all the data initially as strings (you can convert them later) and you have to remove the lines that contain the headers and the XML-info from the workflowset.meta you can import all the CSV files from one folder in one step (ab)using the Local Big data environment. Not sure if there also is a maximum (might depend on the power of your machine).
The upside is the external table will update each time you add new files - but please be aware that often you would have Hive work together with Impala’s COMPUTE INCREMENTAL STATS which is not available in the the local Big Data environment of KNIME.
kn_example_bigdata_hive_csv_loader.knar (688.8 KB)