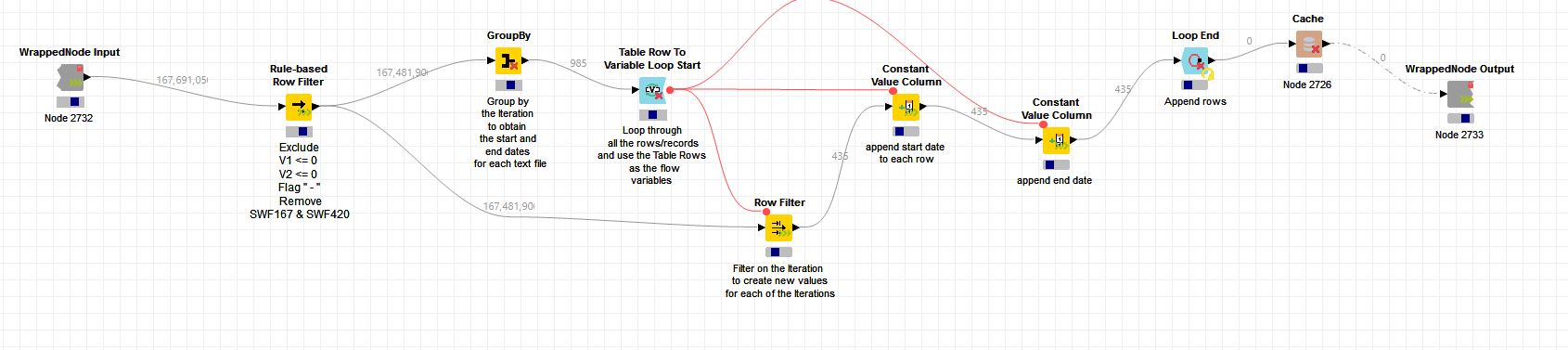
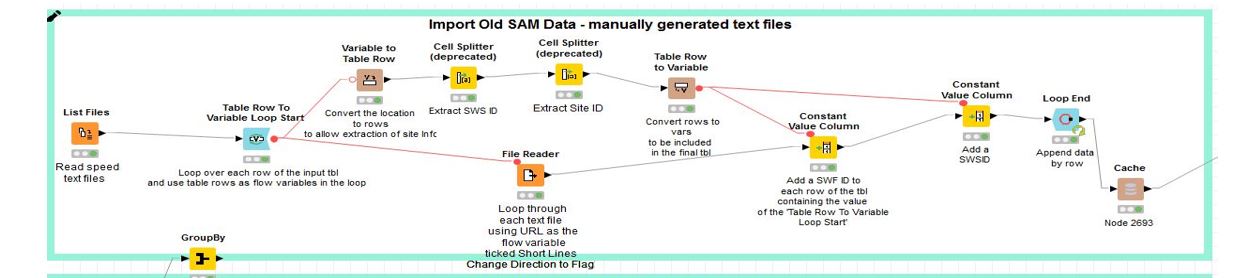
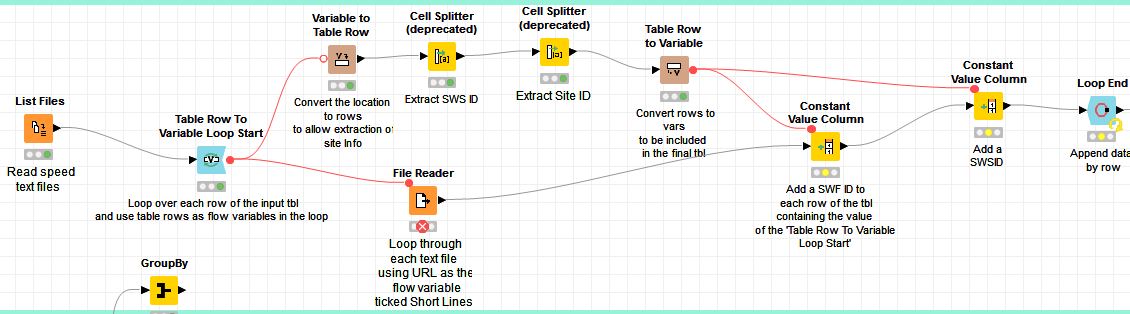
The workflow actually needs to process over 900 text files and loop through over 167 millions of records combined from the text files. Here is the workflow before the streamed execution:
A few remarks since it is difficult to judge from the screenshots:
if you have to process that many files and lines it could make sense to do it in chunks and have some method in place to log the current status and be able to restart at a certain point. Eg. write results to disk after each 50 out of 900 processed files or something. Because if you do not have a very powerful infrastructure, compartmentalization might be a thing for you
also this saving of steps in-between might function as some sort of progress-bar. You write the current status into a separate CSV file and maybe even some time statistics. Sometimes it makes such tasks easier if you could have an idea how long it might take (or you could give someone who is waiting for results an estimation)
see that the power you have is used in an optimal way (like Iris said) avoid unnecessary steps and keep the steps manageable for the power you have. Streaming might help you will have to see about the size of the chunks
see if all the nodes can just run in memory that might speed up things
see if you can assign more RAM and maybe a higher number of threads working in parallel
if you might encounter changing formats it could be good to just import things as strings first (and convert numbers maybe later)
to access a large chunk of files (of the same structure) simultaneously also sounds like a job for a Big Data environment (Hive, Impala external table). If you really must you can think about setting up such an environment in an AWS cluster or something
if your graphical KNIME interface gets stuck you might think about running KNIME in batch mode (and combine it with the logging and ability to restart the process cf. above)
I could not find a node called Column Expression node. Could you please specify exactly which node I should use to replace the 2 Constant Value Column nodes used in the loop?
I installed the node and got it working to replace the Constant Value Column nodes.
Another question is about you suggested to use Chunk loop to process the files. Did you mean using Chunk Loop Start before the loop to break up the files into chunks?
In my experience the recommended Column Expression node is very slow and not useful for large amounts of rows.
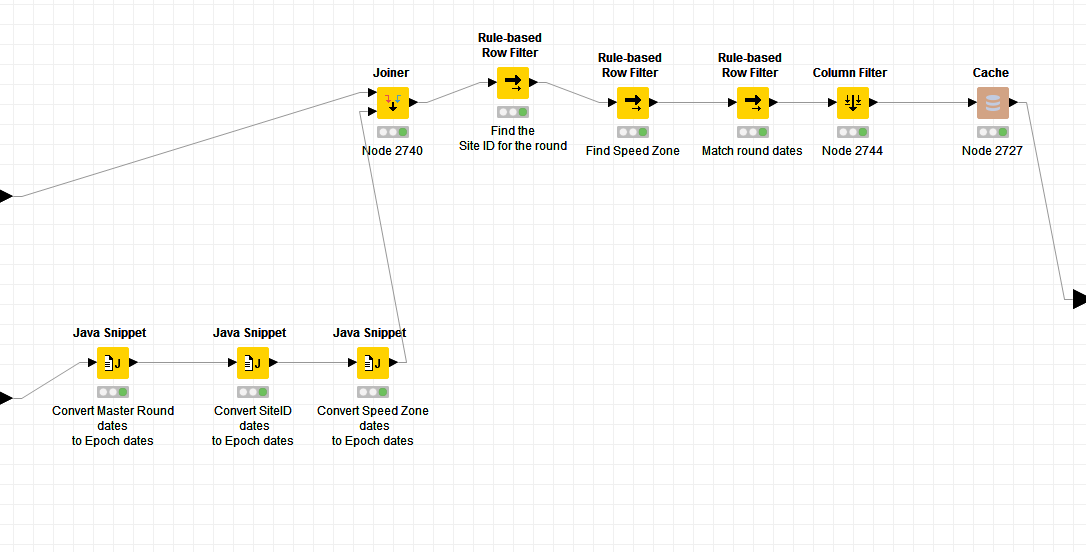
In your Sample workflow, the “Round Dates Match” metanode is the slow part. I could easily greatly increase speed:
Move Java snippets outside of the loop
Rule-based Row Filters
“Matches” does a regular expression match but you are only looking for equality. Use = instead.
Replace Column Expressions back to constant value
With these changes this metanode with loop already runs a lot faster.
As a general comment you also don’t need to attach the flow variables to each node separately. Flow variables are passed from node to node automatically.
BUT: Loops are very slow in KNIME and are best avoided
Hence I added a version of the metanode without a loop. Without loop execution is more or less immediately with the sample data.
There are some very good tips&tricks already, it makes of course sense to identify the slow part as done by beginner, but some general remarks:
Java snippet and also Java Edit Variable are completely broken in loops. Do not ever use them - just use the (simple) version of both and it makes a difference between days and minutes in execution time.
Joining on big tables is a pain in KNIME if you can reduce the size of the tables before hand without losing information do it. Don`t just hide columns (column filter), cache them so they are forced to lose the information.
Don`t keep redundant information - often the way KNIME text processing is implemented you are keeping two versions of the document - that is another sink hole for performance. Check that you only keep text (either within the document ) or string in a column not both if it is not absolutely necessary - for some strange reason the number of columns, especially if they contain a lot of text have a huge influence to joining speed even if those columns are not touched during joining.
But honestly, getting rid of all java snippets should already make a world of difference here.
Would you be able to suggest a better way of processing over 900 text files, extracting the required information from the text file name and joining all of them together?
well in fact there is a way …
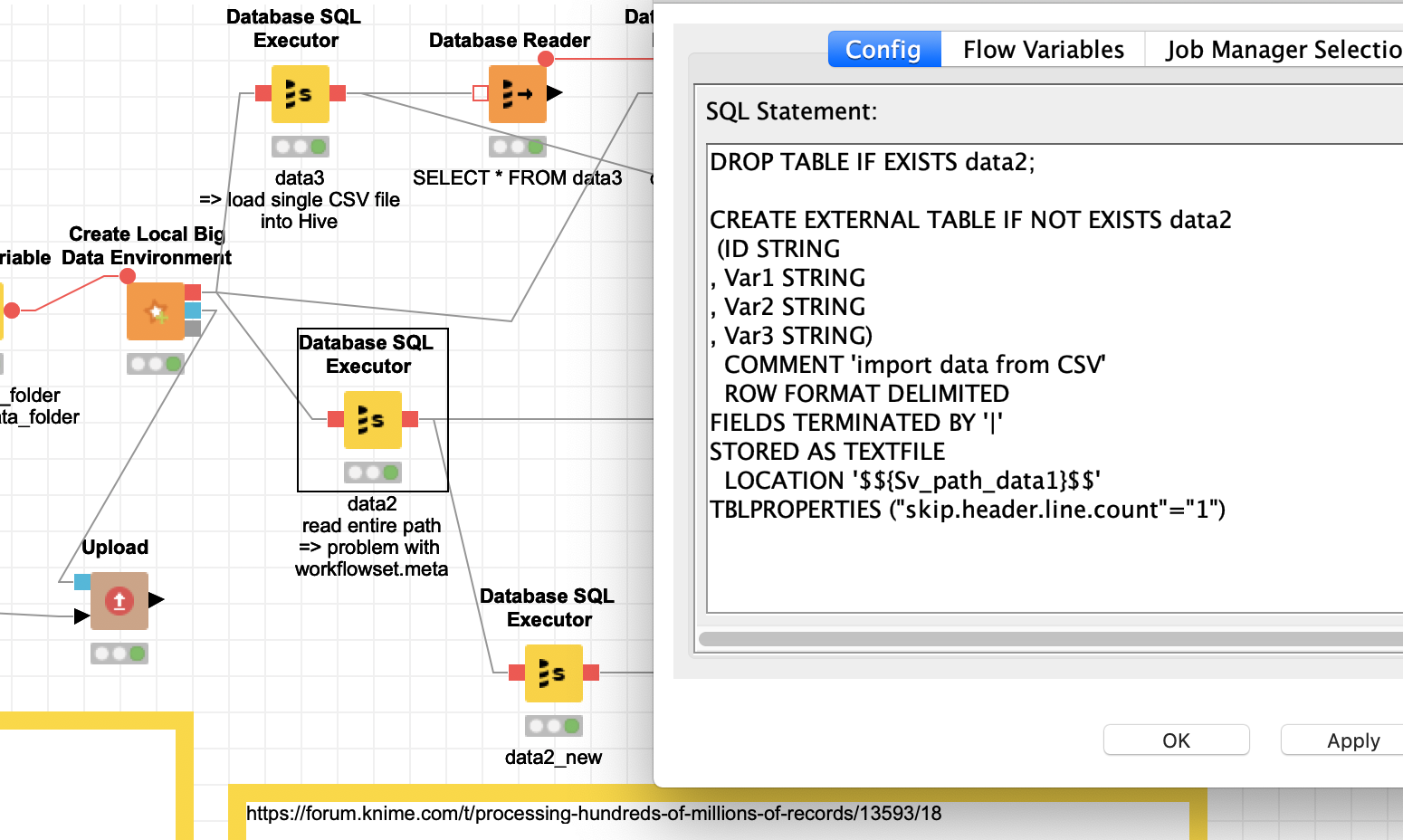
You can use the HIVE function of an external table from the local Big Data environment and point it to a folder that contains all the CSV files you want to aggregate. And then you can refer to this external table and convert that to a regular table. All the CSV files will have to have the same structure and you will have to specify the structure.
Please not I have used “|” as a separator in the 3 sample files.
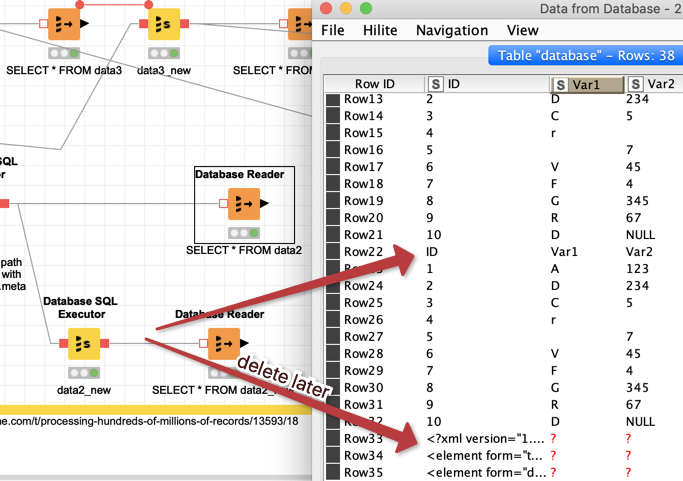
the HIVE version KNIME is using does not respect the settings to skip the initial row (TBLPROPERTIES ('skip.header.line.count'='1', 'skip.footer.line.count'='4')) and also not the setting for the footers
if you use a folder that is within the KNIME workspace it will contain a workflowset.meta file that will also be read and imported
So if you can live with having all the data initially as strings (you can convert them later) and you have to remove the lines that contain the headers and the XML-info from the workflowset.meta you can import all the CSV files from one folder in one step (ab)using the Local Big data environment. Not sure if there also is a maximum (might depend on the power of your machine).
The upside is the external table will update each time you add new files - but please be aware that often you would have Hive work together with Impala’s COMPUTE INCREMENTAL STATS which is not available in the the local Big Data environment of KNIME.