Hi Iris
Thank you for your advice.
The workflow actually needs to process over 900 text files and loop through over 167 millions of records combined from the text files. Here is the workflow before the streamed execution:
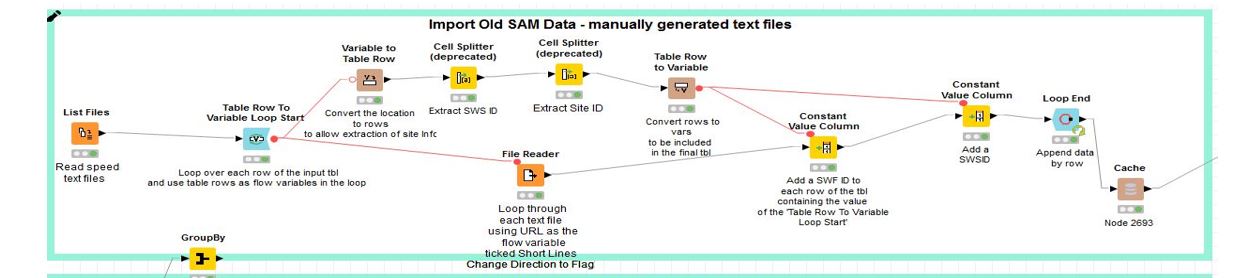
Should I still replace the loop in the streamed workflow with a joiner node?
Many thanks
Jennifer