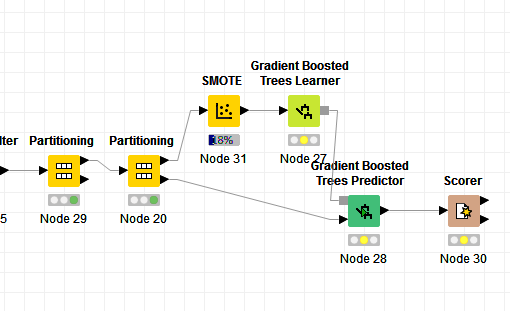
I am pretty new to knime and I am trying to figure out if what I am doing is sensible.
I have a binary-classification problem with data imbalance, and I want to resample the category with the smallest amount of data in it.
For this I am using SMOTE - The point is:
I want to split the data into three: train, validation, test
from the train-validation:
resample train sample using smote
leave validation sample as it is
Perform the training (gradient boost) over train sample
score over validation sample
In order to achieve this, I do the following:
Is this right?
Any advise or references are welcome.
Thanks in advance!
If the partition is a random sample I think it is ok to use SMOTE on the training and check the validation on a non-SMOTE data set (since your real data will also come as non-balanced).
I would recommend for the evaluation of a model also to check things linke Area Under the curve since the scorer might just set the cutoff at 0.5 and your business case might be better served by a different split of Target/Non-Target prediction. In the end it is not really a prediction but you sort your data according to a probability of matching your Target (if you have a true/false Target).
A general advise would be to really think about what you want to achieve with you model and what would it mean if the model ‘predicts’ a target. Since this is no magic crystal ball but a way to detect (clever?) rules within the framework you present to the model.
And always keep a certain level of scepticism - a lot of things can (and will) go wrong …
I am using SMOTE because of the imbalance, but actually it doesn’t seem to perform as well as the regular upsampling I tried with sklearn (python). I checked among the knime nodes and I saw some resampling node, but it only downsamples.
Is there any node for upsampling that is not SMOTE, but a regular upsampling?
I am using the ROC curve, but it is not in the diagram. At least I am trying to do so, but I still need to get used to how to configure it. I am coming from other frameworks (sklearn, TMVA, tensorflow…) and I still need to learn how to mimic the things I know there here.
Just so that the topic can be found later, I’ll say this:
afaik, downsampling brings the best results. You can also cross validate with down-sampled 0 class, keeping the same 1 class.
It really depends on the context of your experiment, whether it is suitable to introduce synthetic data or not.