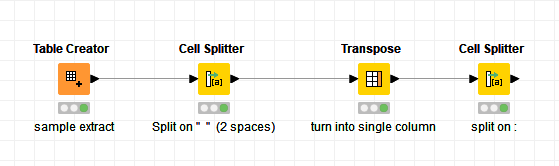
Hi @dseller , I’m afraid I haven’t got an answer for you at the moment, but I do have loads of questions… 
When you say you want to “pull numbers out”, do you mean all the numbers, and just the numbers?
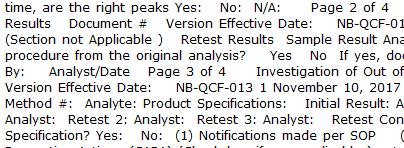
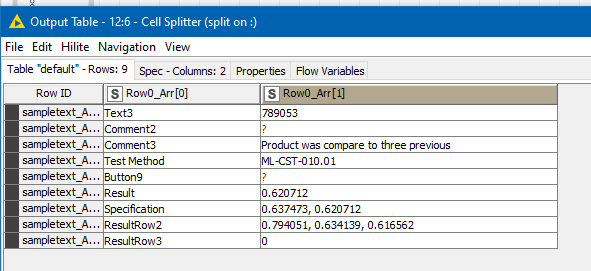
So if, as in your example it said ResultRow2, would you want to “2” pulled out?
What about where it says “Page 3 of 4”… would you want the 3 and the 4 in this case?
And something like “NB-QCF-03”? You said that the numbers are “integers, doubles and dates”. I’m guessing therefore that the “03” in this example should be excluded as it is part of something else?
And what date format are you looking for? I would think identifying that interpreting “1 November 10, 2017” from your example would be an interesting challenge? At what point do the contained integers become part of the date, and not considered to be numerics in their own right?
The more I write and think about this, the more I think that your comment “I’m sure this is relatively easy” was possibly optimistic 
Assuming the data can be extracted, how would you want the numbers presented? A column for each number? A row for each number? A comma delimited string?
Often with a problem such as this, it is the actual definition of the specifics of the problem which take the time to define. I’m sorry to say that at the moment, this “feels” too general. There may be an element of Regex involved in the solution, but I think right now, from what you have said, that the solution is going to be anything but straight forward.
That’s not to say that somebody here cannot assist with finding a solution, but I think we’ll need a better understanding of the actual requirement, (which I know you’ve tried to explain for us) as there are a number of complexities that present themselves here.