Hello KNIME Python community and friends ![]() ,
,
We are glad to announce that starting with the KNIME Analytics Platform 4.6 release you can develop KNIME nodes in pure Python!
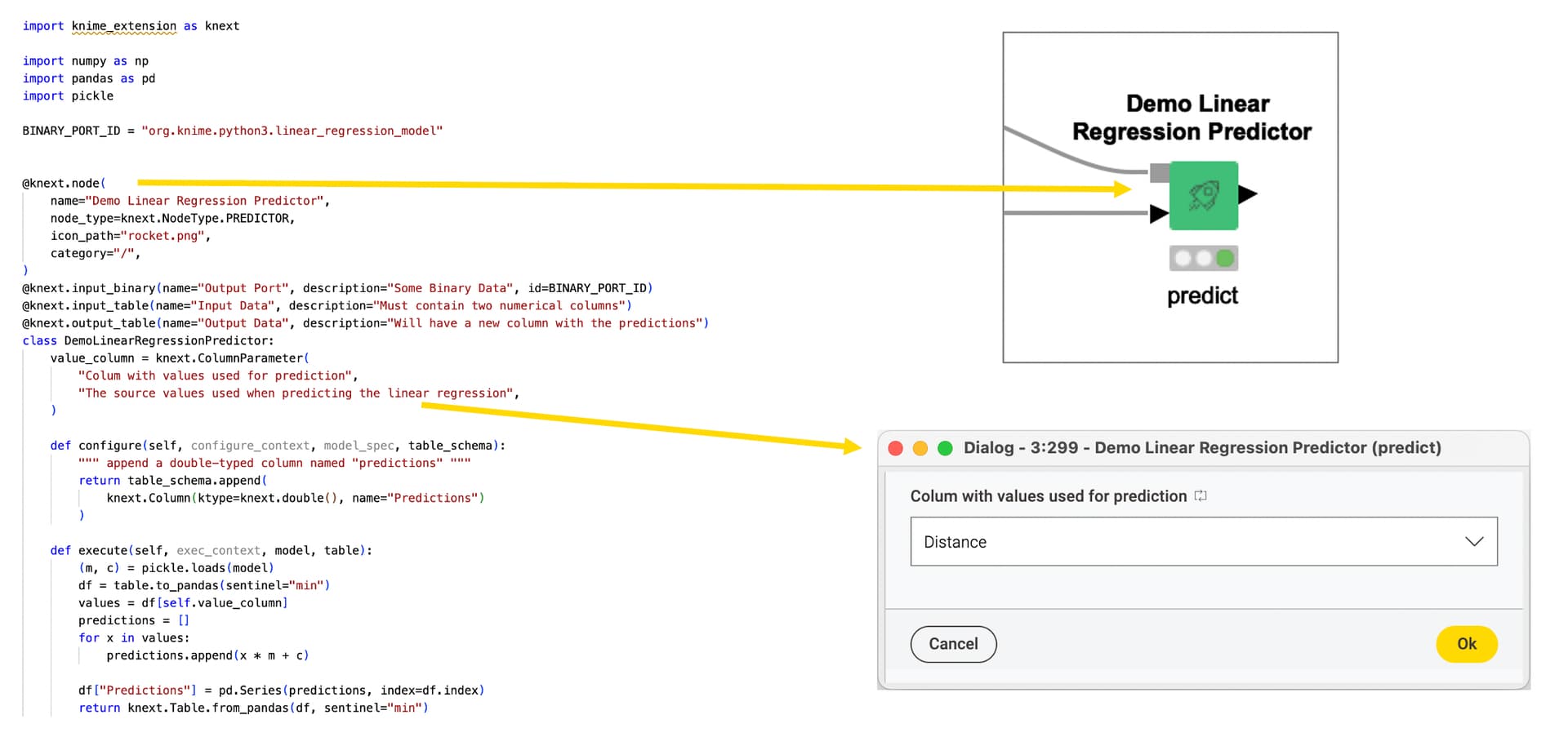
To get started, you just need to configure two small YAML files. Then you can develop KNIME Python node extensions in your favorite text editor or IDE, and even debug your code while your nodes are running in the KNIME Analytics Platform. See the documentation for details and a tutorial.
We are curious to hear your feedback and see what you will do with those new possibilities!
Features included in KNIME AP 4.6
- Defining nodes in Python
- configuring input and output ports (tables and binary ports for now)
- defining node parameters with autogenerated dialogs
- implementing node configuration and execution
- defining views
- accessing flow variables
- reporting progress
- setting warnings
- use Python logging to write to the KNIME console
- Defining node repository categories in Python
- Bundling an extension into an update site that can be shared
- packages the full conda environment, such that the nodes work out of the box when the extension is installed
Features that will be coming soon
- Sharing Python extensions via the Hub
- Defining PortTypes
- Bundling of
pippackages - …
Please let us know what you are missing most.
Documentation
- KNIME Pure-Python Node Development Guide (includes a tutorial)
- KNIME Python Extension Development API Documentation
Disclaimer
KNIME Python Extension Development (Labs) is considered a preview and is currently under development. The API may change in the future. It is not recommended to be used in a production environment.
Feedback
We are looking forward to receiving your feedback. Please reply here with any ideas, comments, or questions. If you run into any problems please follow the Bug Reporting Best Practices.