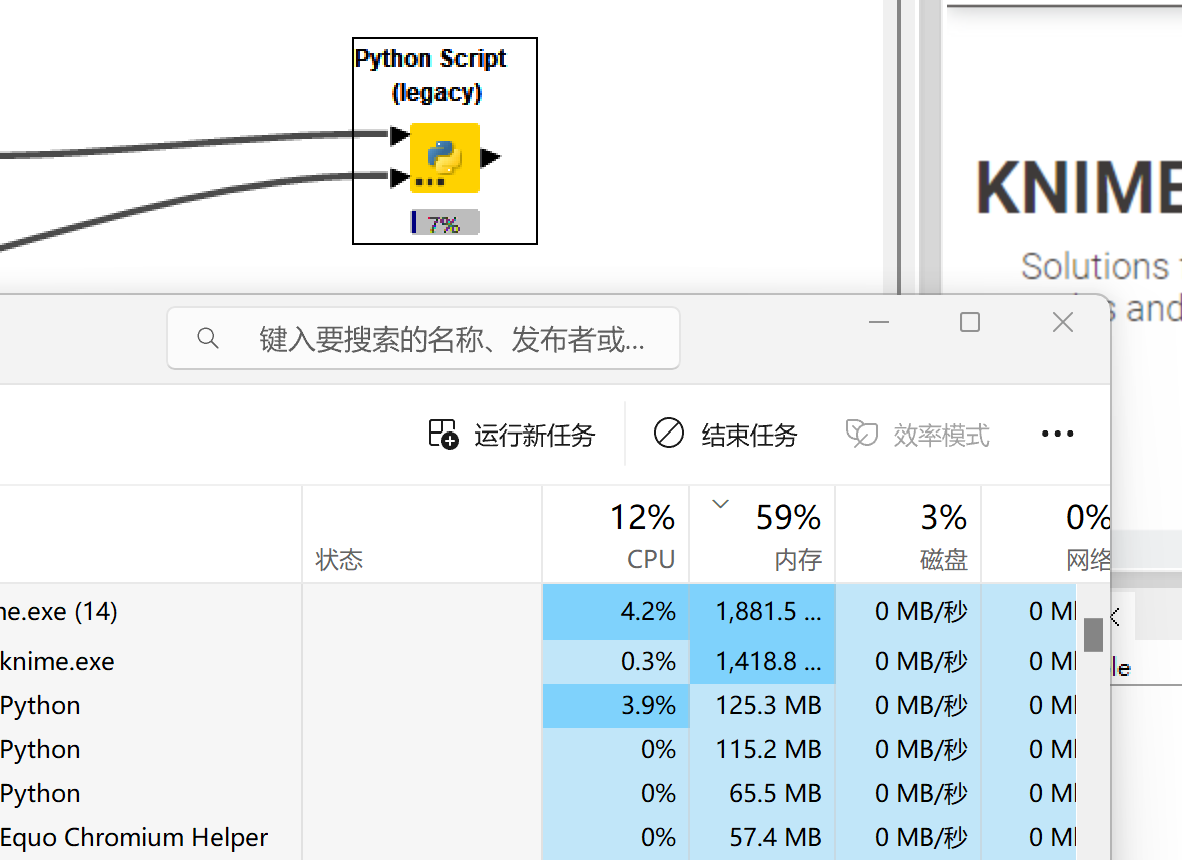
Hello, I developed a Python extension at Knime, but there is a problem: with the same logic, Python nodes execute less efficiently than Python scripts, which in turn execute less efficiently than native Python IDEs. As shown in the figure, custom python nodes cannot consume memory and CPU.
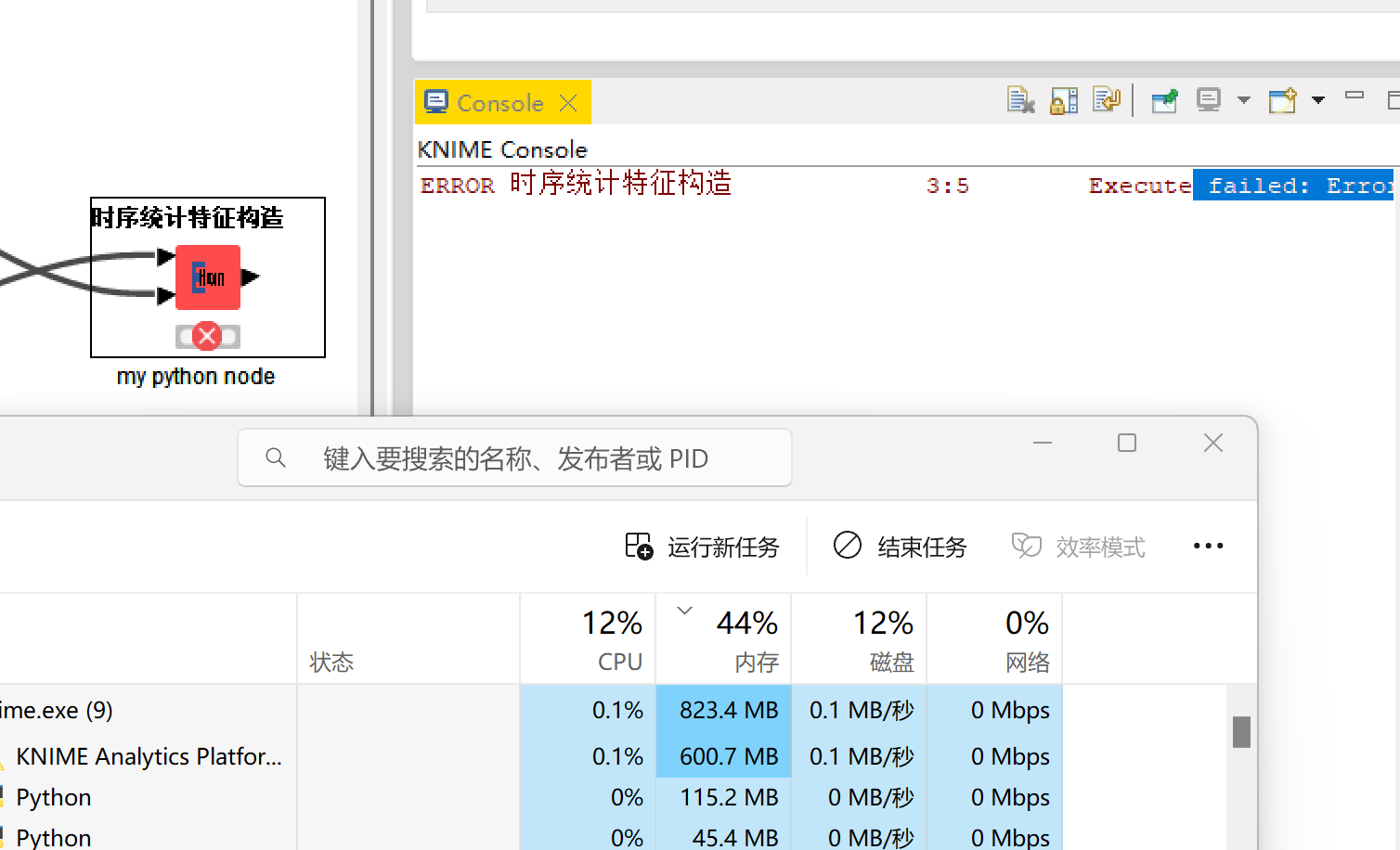
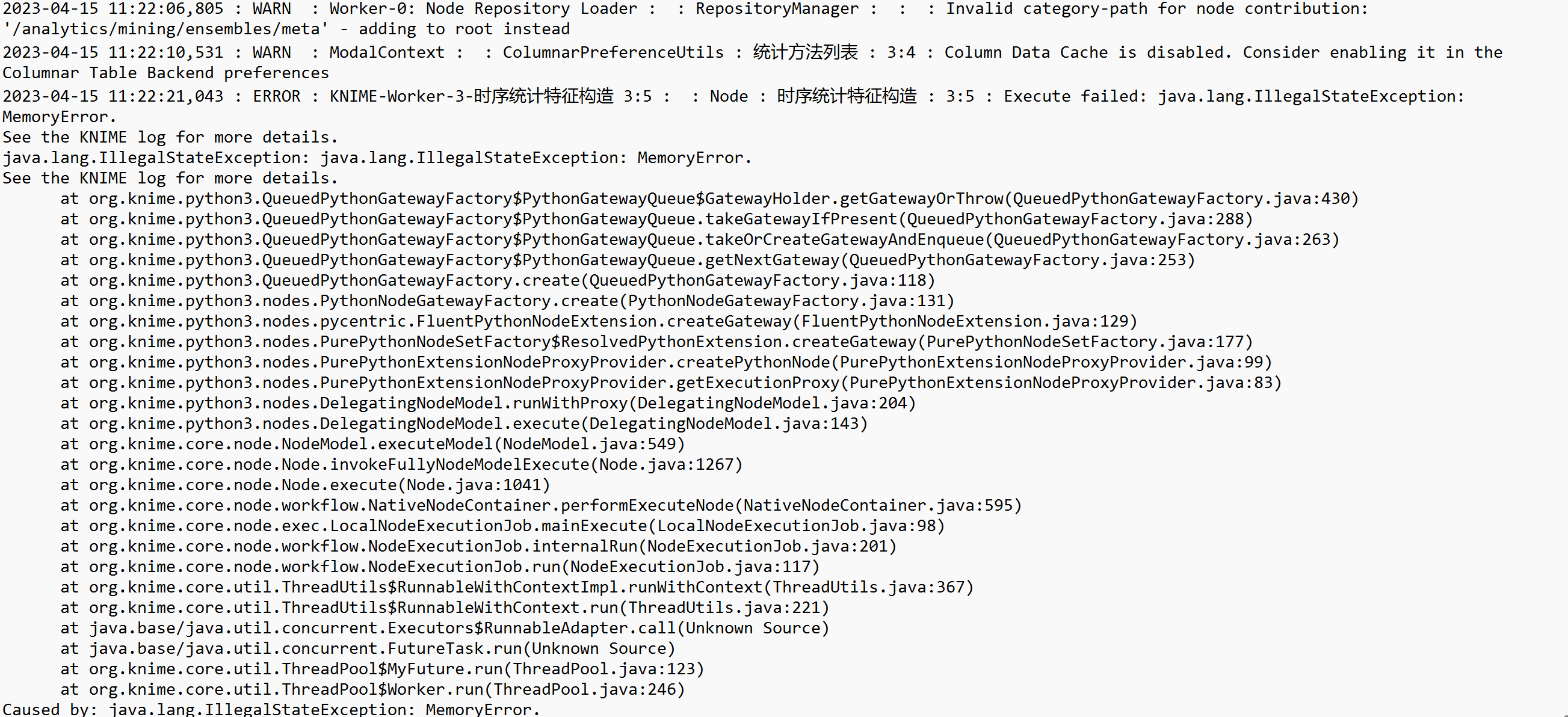
Another example, python node execution will report memory errors, but the amount of data is not large, the logic is not complicated, and the execution in the IDE is fast.
How to solve it?
Hi @yui0000,
The way we transfer data between the JVM (in which KNIME AP is running) and a Python process has changed between the “Python Script (legacy)” node and the newer “Python Script” node (same backend as used by the pure Python nodes). The new backend is supposed to speed up the data transfer. Therefore, I am surprised that it is slower for you. It would be nice if you could provide an example script and data for which the newer node is slower than the legacy node. This would help us to analyze what is happening here.
Also, there are a few culprits that need to be taken into account:
- The pure Python nodes get the best performance if the workflow uses the columnar table backend.
- The “debug” mode for Python nodes slow down the startup of the Python process significantly. Therefore, it should be turned off for comparing performance,
1 Like
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.