Hi
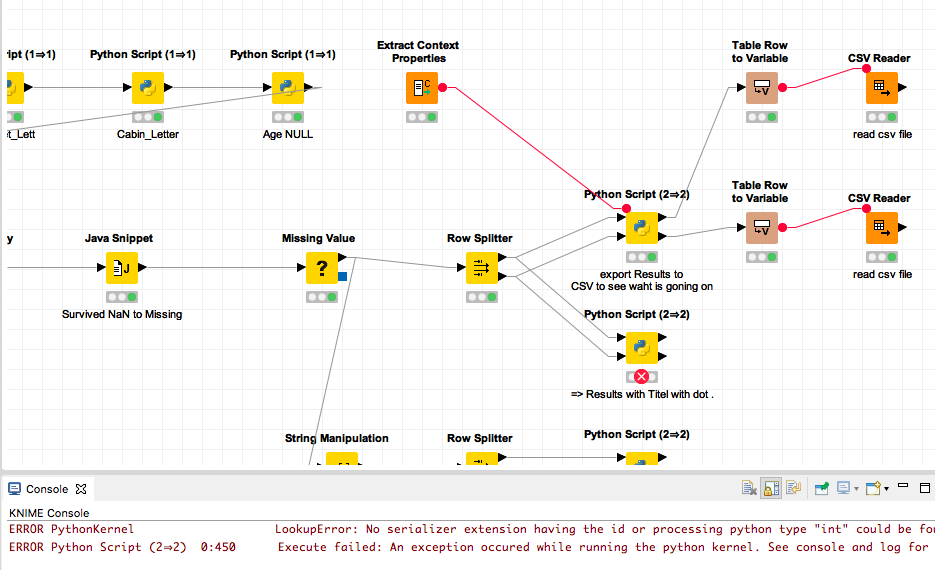
I have a python node (2=>2) failing with this error:
LookupError: No serializer extension having the id or processing python type “int” could be found.
It fails only during execution.
The flow is attached.
What could be the reason?
I assume you used the data from this competition. I had no problems running your workflow using that data. Could you please provide some more information about the Python environment you used (Python version, pandas version etc.)? Also which serialization library did you use? You can find that under File > Preferences > KNIME > Python > Serialization Library.
The workflow still runs properly when using a conda environment that matches your description (conda create -n py35_knime python=3.5.5 pandas=0.23.0) and using Flatbuffers as serialization library.
I used KNIME 3.5.3. Which version are you using?
Also, maybe creating a fresh conda environment (as described in this blog post) could solve the problem.
I attached the workflow with data included. Maybe someone else can help to reproduce the problem.
I can reproduce the error with a current Anaconda/Python environment on a Mac. So I assume the data resulting from the workflow have something that offers a challenge when converting Integers back to KNIME. One solution could indeed be to revert to the suggested environment of python 3.5.5 like @MarcelW suggested.
I tried a few variants but the only thing I could do was exporting the data from Python to disk and importing it back in so one could see what the outcome is.
A note on the content. I do not get the split and the Survievd=3 as test data right now. I have not looked deeper into that. I replaced the NaN with Null - so if all this had a special purpose pleas be aware I changed these things in the workflow.
I am running into the same issue, though I’m using a different dataset. I have a python script that successfully loads the data into a pandas dataframe. I get the same “No serializer extension having the id or processing python type “int”…” error (clearly seems to be a type problem between pandas and knime). I have both Python 3.62 and 3.53 installed. Tried both Python environments, Flatbuffers. Tried Pandas 0.23.0 and Pandas 0.23.1 I get the same error. I’m using a Python source node.
Hi all, I am also having the same issue with my own pandas dataframe, tried creating separate py35_knime as suggested, tried choosing all serilalisers, no joy.
Working solution: used python variable node writing csv at the end of python code and then re-importing by a file reader straight after.
Another option suggested by my friend: converting to string in your final dataframe on the output, I have not tested it yet.
Developers, could this be fixed as a matter of priority please. For a market visionary leader - integration with Python not working - not an insignificant bug
I can reassure you that we regard this bug as critical and work on fixing it - we just weren’t able to reproduce it, yet (mutiple machines, various setups). That’s why I’m actually surprised that so many users experience this problem - we clearly must be doing something wrong or miss something while reproducing. I’m sorry for the inconvenience.
I wonder if the problems could somehow be connected. Since the R version 3.5 users experience problems with getting back results from R (at least on the mac). This feels similar. Within the Python or R everything works fine and then there is a problem getting it back to KNIME with some strange error messages about numeric formats. Or could it be that there is a Java thing?
Do you all happen to use macOS? That would greatly narrow down the search.
Technically, the R and Python integrations handle the data transfer back to KNIME/Java quite differently. I’d be puzzled if there was a connection but you never know… .
At least the error described in this thread appears on the Python side so I don’t think it’s a Java thing.
to all: Sorry for the trouble. We’re on it. Could you provide more details regarding your operating system, KNIME version etc? This would really help us narrowing down the problem!
Per your question, I’m using Windows 7, 64-bit with the latest version of Knime Analytics Platform. I just ran the latest updates this past week. I have been able to use the Python source node in a few of my workflows without issue. In this one workflow, I’m using the Python source node to pull in data from RedCap. The dataset has about 410,000 records and 127 fields. I’m chunking the export from the RedCap API into the dataframe from within the Python code. When I pull up the code in Visual Studio, I can load the dataframe fine and export it to a csv file. In Knime, I’m simply trying to load it into the output_table (not export it csv). Memory policy is to disk. But it fails with the serialization error noted in the original post.Tonight I started to export incremental number of records from RedCap. With 100,000 records, node executed successfully. Tomorrow, I’ll continue to increase the load and see if I can isolate the error. I’m back on US side of ocean. It won’t be until your evening before I get to it.
I think I figured out the issue. I had a couple of records in my “by_id” column that were not obvious but being interpreted as a string although every other record was an integer. I added the cast of the column as a string in my dataframe. It is clear that the mixed column type is playing a role in the serialization required to move the dataframe into Knime. Once I defined “by_id” as a string column, the node executed properly. I have other columns that contain data that you would think would run into the same issue, the data is all integers or missing values. But pandas clearly passed over the int dtype for these columns.
It seems like we do not support the full range of available numpy.dtypes, yet, but mostly the ones that exactly match the data types available in KNIME (e.g. numpy’s int32 matches KNIME’s Number (Integer), int64 matches Number (Long), etc.). Other, less common data types such as uint16 do not get recognized as “KNIME-native”. That’s why KNIME looks for serializer extensions that are able to handle the type but doesn’t find one. Somewhere on the way, the specific type (e.g. uint16) gets lost, that’s why the error message only states a rather broad “[…] python type “int””.
To temporarily work around this issue, please make sure to convert all affected columns - i.e. all integer columns that are not of dtypeint32 or int64 - to one of the supported types. E.g., like this: output_table.your_affected_column = output_table.your_affected_column.astype("int32").
This fixed the problem on my local machine. Please let me know if the problem persists after applying the workaround.
We will extend our data type support as fast as possible.
Again, sorry for the inconvenience.
 .
.