@DiaAzul . . . thnx for your great hints.
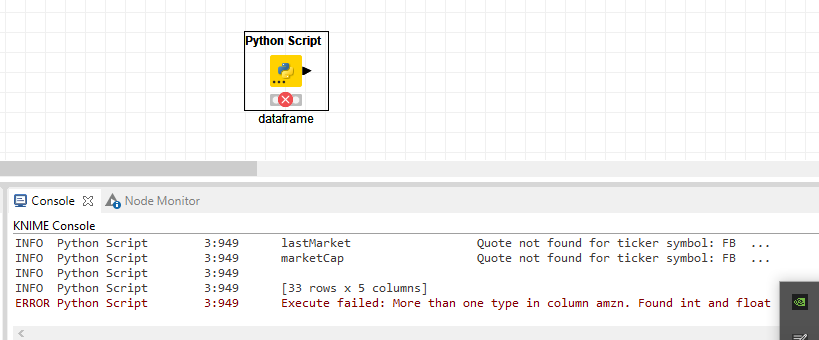
It works fine. But there’s one “little” thing . . . it presumes that there’s at least one wrong ticker (like “fb”).
If all the tickers are OK the code productes an empty dataframe .
I tried to fix that with try/except but that gives an error (e.g. NONE type). My best solution is as below but than I have to split the “Row ID” for the symbol and date.
Splitting in KNIME is not such a big problem . . . but I think it is better / more elegant to solve in Python.
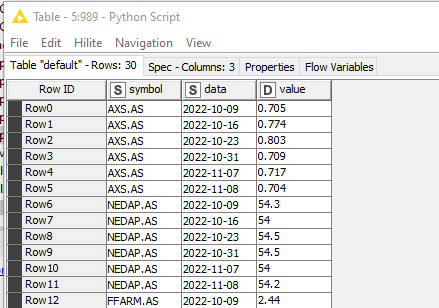
I hesitate you to ask you after your great hint but have you any suggestion how to solve it in Python (like screenshot)
Many thnx in advance
= = = =
#Copy input to output
#output_table_1 = input_table_1.copy()
import pandas as pd
from yahooquery import Ticker
funds = [‘aapl’, ‘amzn’, ‘nflx’, ‘goog’]
#funds = [‘fb’, ‘aapl’, ‘amzn’, ‘nflx’, ‘goog’]
ticker_def = Ticker(funds, asynchronous=True)
ticker_responses = ticker_def.history(period=‘1mo’, interval=‘1wk’)
##print(ticker_responses)
prices_from_response = list()
for symbol in funds:
ticker_data = ticker_responses.get(symbol)
if isinstance(ticker_data, pd.DataFrame):
ticker_close = ticker_data[“close”]
for date, value in ticker_close.iteritems():
record = {
“symbol”: symbol,
“data”: str(date),
“value”: value
}
prices_from_response.append(record)
output = pd.DataFrame(prices_from_response)
if output.empty == True:
** print(‘DataFrame is empty’)**
** output = ticker_responses[[“close”]]**
else:
** print(‘DataFrame is not empty’)**
output_table_1 = pd.DataFrame(output)