Dear all,
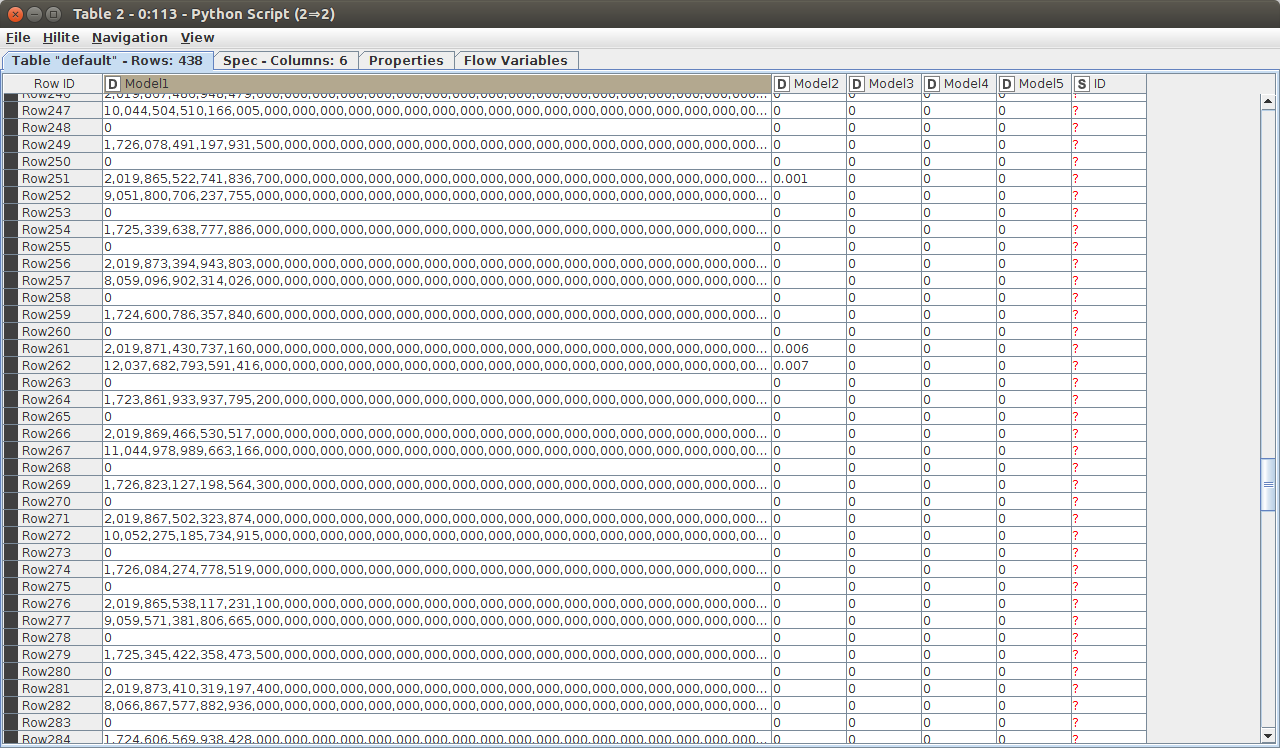
today I tried to evaluate a keras model in Knime within a python node. So far it worked, but when I send the predictions to an output table I get a lot of weard numbers showing in the knime table, which are clearly not there in the table if I print it to the Python output (or write it as a csv):
Here a screenshot
In the xls file are the actual numbers as outputted by pandas to_csv predictions.xlsx (24.8 KB)
The column types are float32, in case that helps.
It would be great to get a hint what is going wrong here. Unfortunately I can’t really reproduce it in a different (shareable) setting but ill try further.
This looks like a number overflow/loss of precision during conversion of Python floats into Java floats. What serialization library did you use to transfer the data to KNIME? You can find that under File > Preferences > KNIME > Python > Serialization library.
A shareable setting (i.e., an example workflow that reproduces the problem) would greatly help if that’s possible.
thanks for the quick feedback.
The Serialization indeed is the problem: I used the “standard” one (Flatbuffers Column Serialization) and when I switched to the experimental CSV it seems to work fine (The Apache arrow Serialization does not work at all).
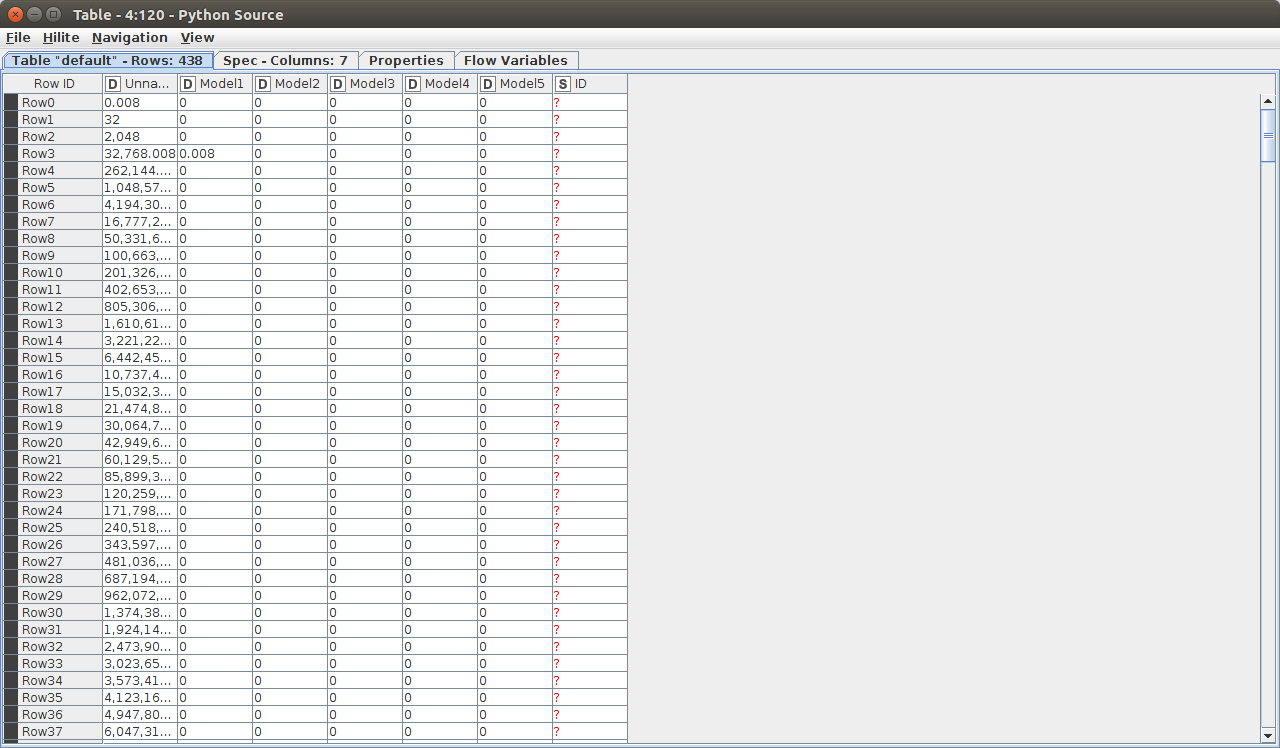
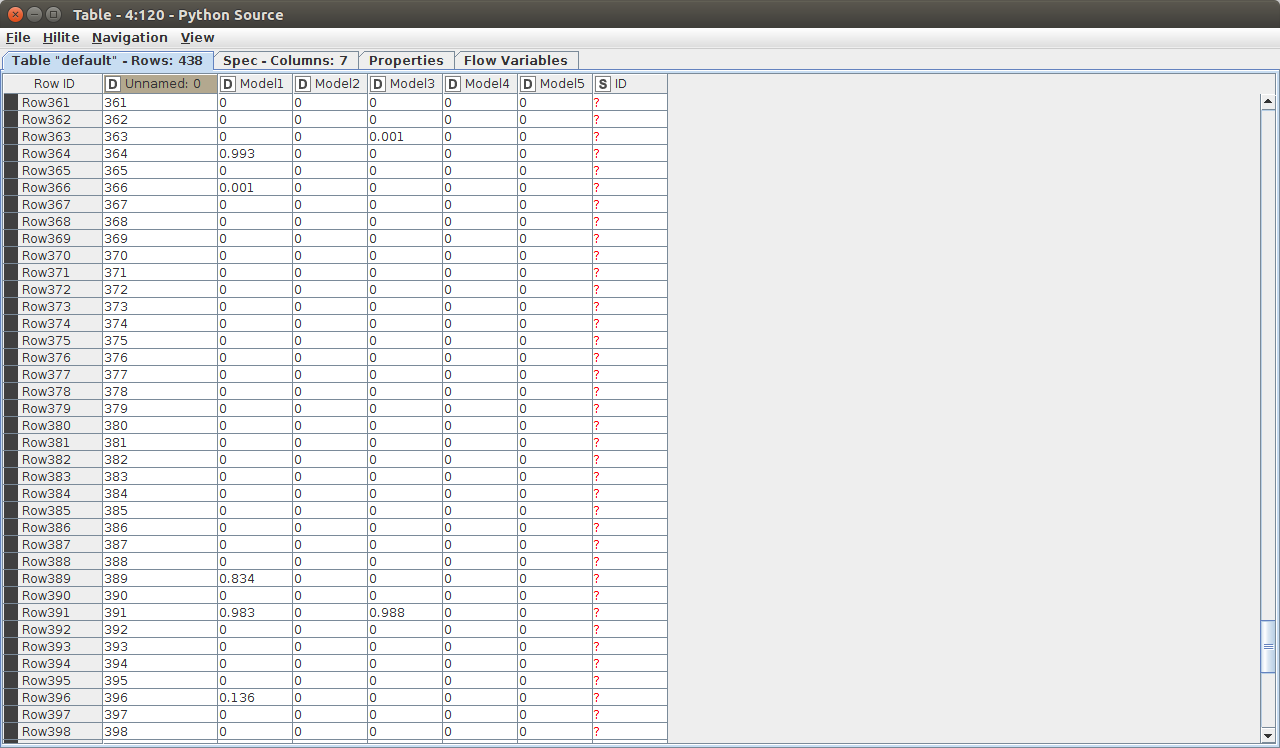
I found a way to reproduce it:
It is reproducible if I read the csv with pandas read_csv into the Python source node, and write it to a KNIME table.
I have attached the ‘Workflow’ and the csv (as csv upload is not permitted I attached it as a *.txt file)
Is there anything I should be aware of if I use the CSV serialization as it is labelled experimental? Then I would just keep it as is until the other serializations work as expected.
I’m glad that helped. I’d recommend Apache Arrow over CSV. To make Arrow work, you’d need to install pyarrow, version 0.7.0, in your Python environment. The package is available via the conda-forge channel. A command to install it would look like this: conda install -n py35_knime -c conda-forge pyarrow=0.7.0
where py35_knime is the name of your conda environment.
Thanks for providing a workflow to reproduce the problem, we’ll work on fixing it as soon as possible.
Edit: This will be fixed in a future version of KNIME.
I installed pyarrow via pip (version 0.10.0) before you mentioned conda) and it gave me this error (Thats why I said in the beginning it does not work at all):
ERROR PythonKernel pyarrow.lib.ArrowIOError: Invalid flatbuffers message.
ERROR Python Source 4:120 Execute failed: java.lang.Exception: Failed to receive message from Python or forward received message
removing it and doing it via conda as you suggested gives:
ERROR PythonKernel AttributeError: module ‘pyarrow’ has no attribute ‘OSFile’
ERROR Python Source 4:120 Execute failed: java.lang.Exception: Failed to receive message from Python or forward received message.
Any Idea? (Python 3.6.5, conda 4.3.30 on Ubuntu 16.04 LTS)