I am making some performance measurements for some nodes that I connected.
They are the new python script nodes(Labs) using the Columnar Backend.
I compare 2 cases.
First case, I pass data as Knime tables, from script to script, with multiple ports, to pass multiple 2D arrays.
Second case, I save the arrays in binary form, as npy files, to the disc.
When saved, I create flow variables with the file name, so I can read the data from the next node.
It seems that in almost all cases, when it comes to speed, saving the data to the disc and then loading them from the next script, is preferable. How is that this is happening?
My expectations were, if the Data fit in RAM, transferring Knime tables should have been faster than saving data to disc and the loading them again.
My benchmarking was done for tables with 3 different sizes.
In all cases, saving to the disc, is faster than passing Knime tables from script to script.
It also seems that for bigger tables, it is even more faster to save them to the disc than passing them as Knime tables.
Note
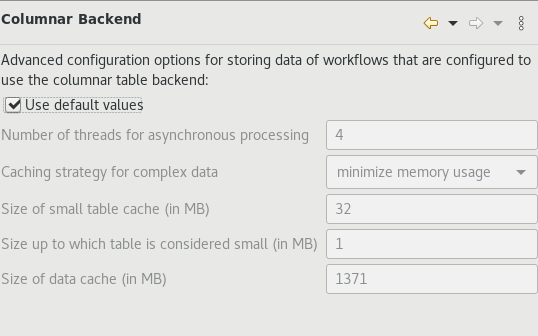
I have Columnar Backend active, with the default options as in screenshot. Using -Xmx8g, 8GB of RAM
thanks for comparing the performance of the Python script (Labs) node and sharing your findings!
The way I understand your expectations of using KNIME tables to pass data around, you are hoping that the table would stay in RAM all the time. While this is true inside of KNIME, when you use a Python Script (Labs) node the data needs to be passed from KNIME to the Python process. Currently, this also happens by storing the data to disk and reading it in Python. We are using pyarrow instead of plain npy files for cross-language read/write support (Java & Python here), additional type support, batch wise access to the tabular data, etc.
Additionally, KNIME performs some consistency checks on the data, such as making sure there are no duplicate row keys. And it computes the domains of the columns (e.g. min and max for numerical data).
As the data transfer between KNIME nodes, and especially Python nodes, is more involved than just saving and loading it, the performance comparison is not completely fair.
If you did not care about any of the benefits you get from using KNIME the normal way (looking at intermediate results in KNIME, having full type support, having consistency checks etc), then you could also use the streaming executor in KNIME (Streaming data in KNIME | KNIME). However we have not yet optimized the streaming executor to fully make use of the possibilities that the columnar backend provides.
Thank you for your answer is very helpful and explains the results.
In my case I don’t always need to have a peak into the tables, sometimes I just need to execute some nodes.
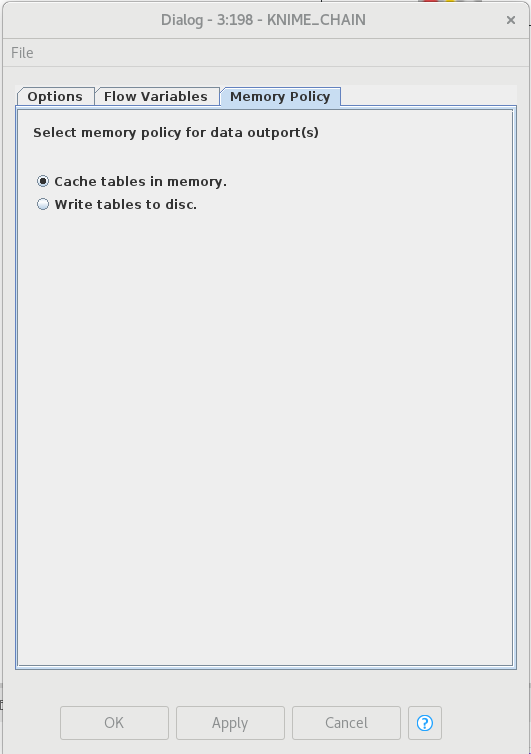
Now I have another question. When a node is configured there’s this option in the Memory Policy tab
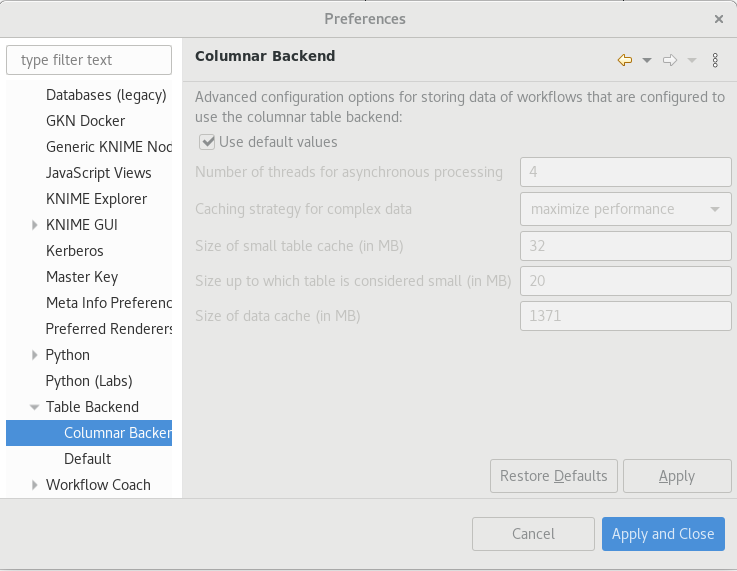
Since both of the cases the data is saved to the disk, what is the option Cache tables in memory indicating? What if I change the configuration in the Preferences < KNIME < Table Backend < Columnar Backend.
Changing the default values may increase performance, depending how big my tables are? But in all cases, as I understand, data are written to the disk.
I will try that streaming executor, if I can write python for it, thanks for the notice!