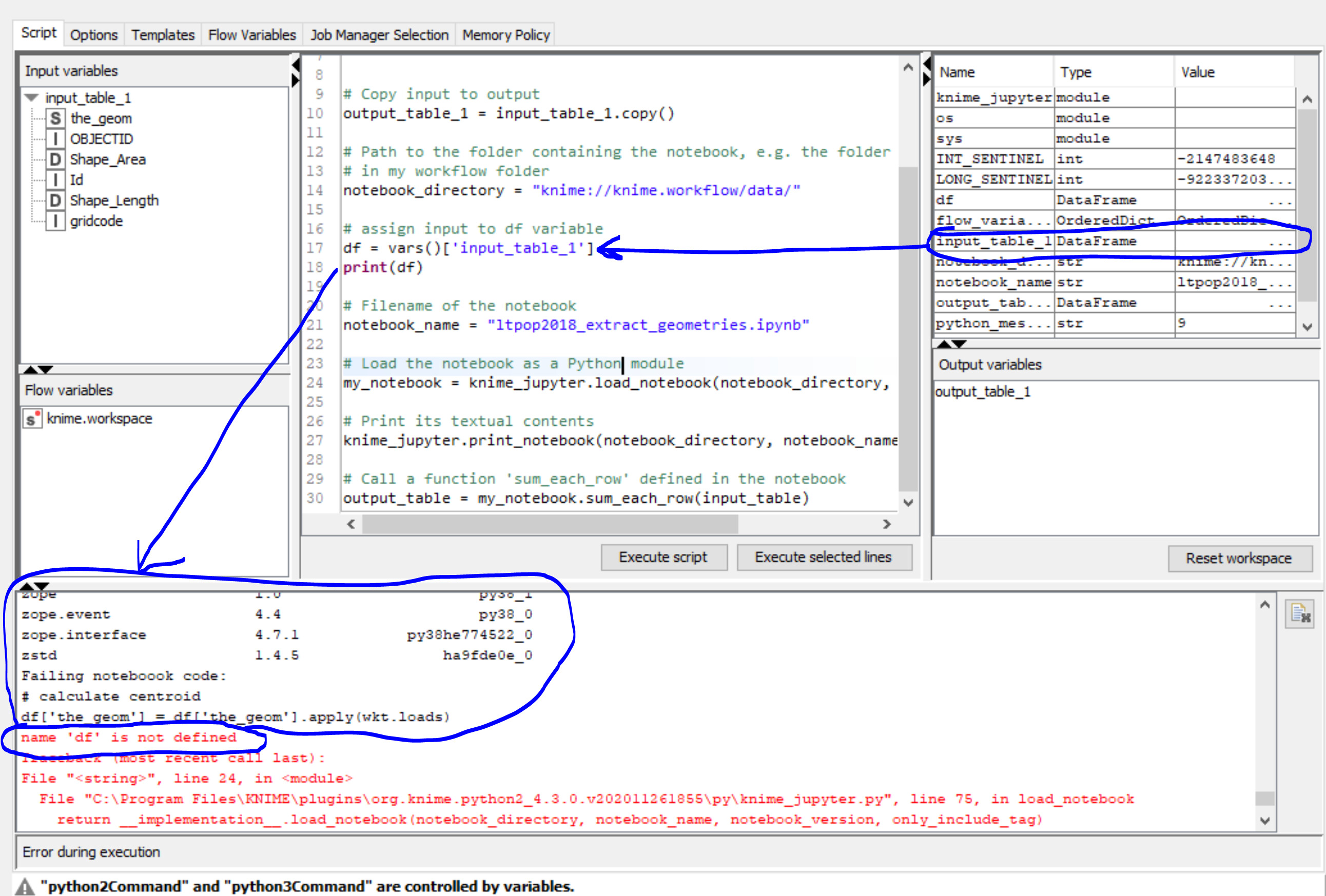
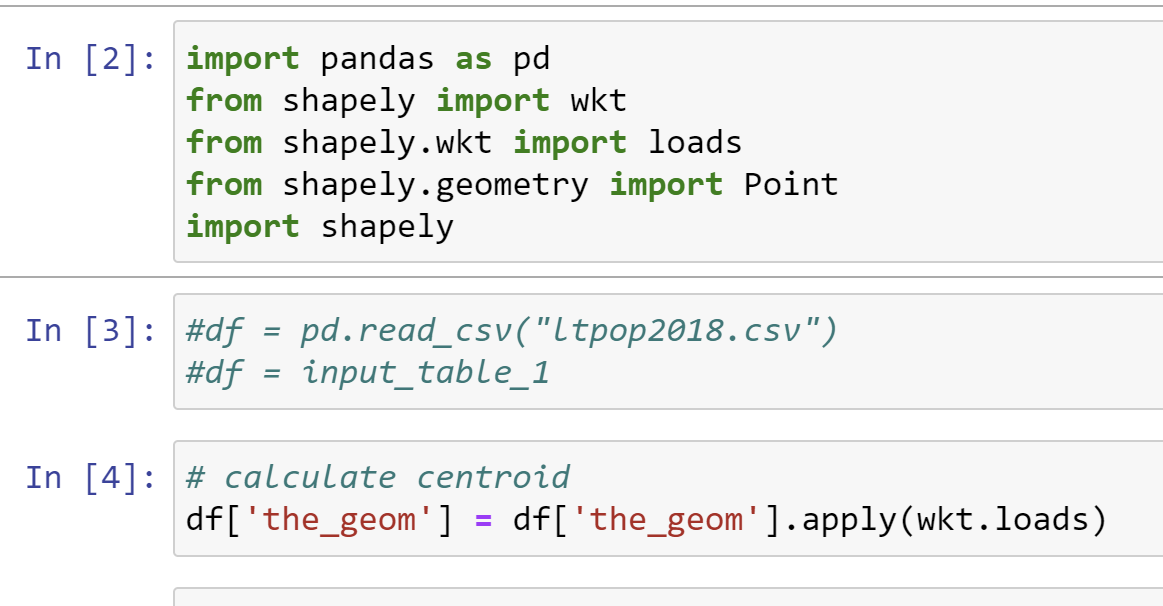
I am trying to include the Jupyter notebook I developed into my KNIME workflow. My problem is that I can not pass the data from the CVS Reader into the notebook.
I am afraid this will not work the way you would like it to, given how our Jupyter integration is currently designed. knime_jupyter.load_notebook loads the Jupyter notebook into the node’s “main” Python script as a separate Python module (comparable to what Python’s import statement does). In Python, the namespaces/scopes of the variables of two different modules are isolated from one another, that is, code inside the notebook cannot simply reference variables declared in the node’s main Python script. So some mechanism will be necessary to explicitly pass the required variables from the main script to the notebook. Right now, this is only possible by means of function calls (like the one in line 30 in your screenshot, where ìnput_table is explicitly being passed to my_notebook.sum_each_row). So the only solution that comes to mind would be to remodel your notebook such that all cells that require external input become functions:
What I am looking for is an ability to pass the data (input table) into my notebook, so the notebook could pick it up and process without the need to import the dataset again within the notebook.
I am not clear on how do I pass the input table from the node to the notebook and how to pass the output dataframe to the node so it could write it to the node.
If vars={‘df’: df} could serve that purpose, then yes.
One way (maybe not the most elegant one) could be to store the data in a parquet file and read it back into the jupyter notebook and later back to KNIME. Or you could store your data in a local database like SQLite.