Hello,
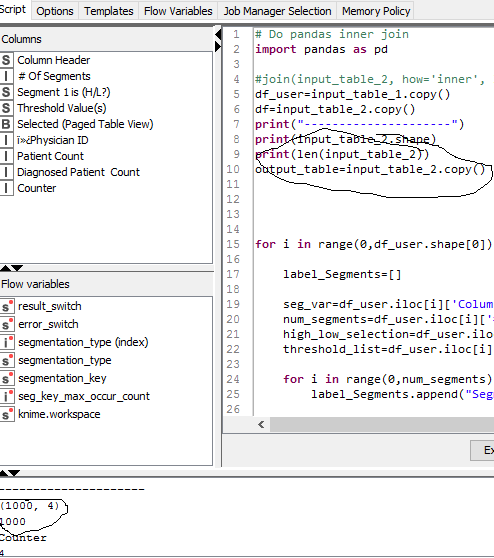
So basically I am trying to feed in 2 tables to Python node (2=>1) , internally I am trying to do some processing which requires my entire table to be fed, I am using some aggregated values on certain columns required dynamically, hence the need for entire data frame.
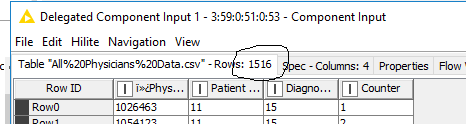
Out of the 2 tables that I feed one table ( table on which my processing algorithm will work)
has 1516 rows.
However when I try to print it’s size inside Python Node ( am getting 1000).
Now this is disturbing my entire logic internally.
I tried changing the chunk size via configurations but did not help me. I am surely required to read the entire data frame for this and many other further use cases. How can I do this?
Secondly I tried running my piece of logic on Jupyter Notebook it ran successfully as expected, however when I am trying to run it via Knime Node I am getting the error “Fill Values must be in Categories”.
Help Appreciated!
Regarding your first problem: only when in the script editor/configuration dialog of the node, not all of the rows of the input tables are loaded into Python. This is done for performance/interactivity reasons and can be changed via the Row limit (dialog) option on the Options tab of the configuration dialog.
When actually executing the node, all of the input will be considered regardless of that option.