I use a python script in the 4.7.1 version, which uses pandas data frames and uses the df.drop_duplicates() function. That line gave me the following error:
NotImplementedError: KnimePandasExtensionArray cannot be created from factorized yet.
The same script was working very nice with the 4.6.4 AP version, when it was still in the labs. What is the workaround here?
that is an interesting question. Could you provide the KNIME log around that error please?
Additionally, do the nodes in the different KNIME Analytics Platforms use the same Python environment? Can you send the python version and the pandas version of that?
E.g. in the script nodes via import pandas print(pandas.__version__)
The reason the error was generated, because one of the columns contained sets. That is of course not working in pandas, as sets are unhashable, but the interesting thing was that the error message was misleading.
The python error message is usually:
error: TypeError: unhashable type: ‘set’
while the KNIME error was:
NotImplementedError: KnimePandasExtensionArray cannot be created from factorized yet.
As of now I sorted out my bug, it works fine without the set column, but it would be useful to get back the original error message.
thanks! I tried to reproduce, but cannot. The following workflow works fine with the bundled environment KNIME Python Integration 4.7.0.v202211291452
and KNIME Analytics Platform 4.7.0.v202211300839
(pandas: 1.5.1)
it also worked fine with 4.7.1:
KNIME Python Integration 4.7.1.v202301311311
KNIME Analytics Platform 4.7.1.v202301311353 Pandas_duplicates_error.knwf (8.6 KB)
Could you adjust the workflow to reproduce the error? Or if it throws the error, can you tell me the versions of the Python Integration and the Analytics Platform (Help → About KNINE Analytics Platform → Installation Details)?
Which conda environment did you use? The bundled one which comes with the installation? If not, could you send its contents via conda activate <your_environment> conda export > conda_env.txt
?
This is the log file in debug mode starting from importing the workflow you shared and trying to run it 2 times: NotImplementedError_21032023_log.txt (34.7 KB)
print(pandas.version):
Pandas version: 1.4.1
print(sys.version)
Sys version: 3.9.11 (main, Mar 28 2022, 04:40:48) [MSC v.1916 64 bit (AMD64)]
Other versions:
I used the default bundled py3_knime environment. Although it appears under other environments of mine as well. Let me know if I should send you the environment extract as well.
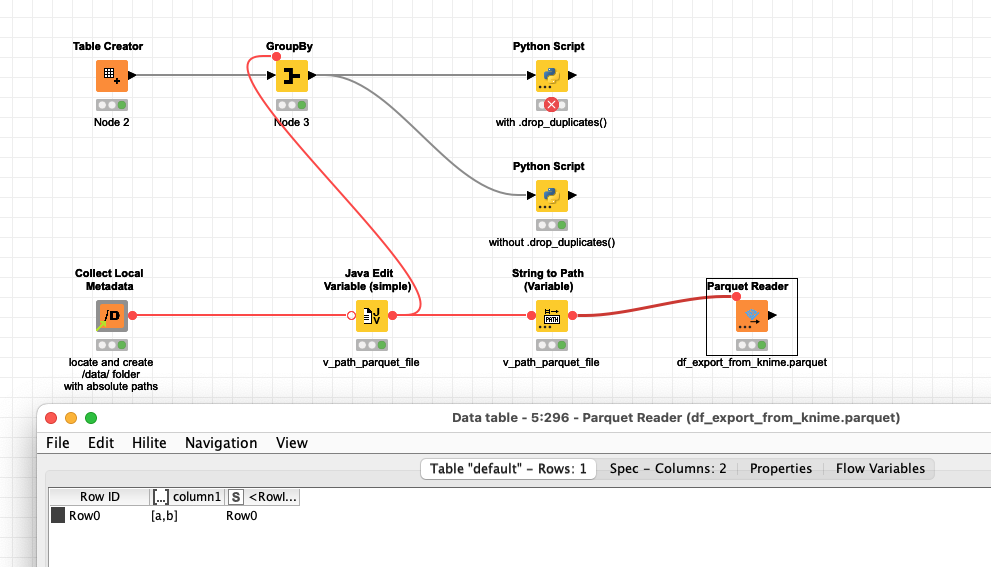
@steffen_KNIME there indeed is something strange with the dataset after using the “.drop_duplicates()”. I can export the resulting data to parquet and re-import it into KNIME but cannot get it back to KNIME. It might be worth exploring.
KNIME Python Integration 4.7.1.v202301311311
pandas - 1.5.2
sys - 3.9.15 | packaged by conda-forge | (main, Nov 22 2022, 08:55:37) [Clang 14.0.6 ]
Confirmed, ticket is AP-20311 and we will come back once it is resolved.
However, after I tried mlaubers example workflow with the latest nightly and the regular 4.7.1 release (both have an issue with Pandas.drop_duplicates(), I tried it with 4.6. and Pandas 1.4.3 and it also does not work. Does that example work for you, @Agi?
I used the Conda environment, not the bundled option. In my py3_knime environment, the pandas version was 1.4.1. When I switch to the bundled, the pandas version changes to 1.5.2, and the drop_duplicates() function runs without error. So it is in agreement with your test, that initially with the 1.5.1 pandas version, you did not reproduce the error, but it appears with pandas 1.4.x.
I tried the workflow of @mlauber71 , has the same behavior concerning the duplicate drops, so dropping duplicates only works with pandas 1.5.x versions. Concerning the parquet file saving, I also see the same as mlauber, it fails even with pandas1 5.2.
I have the same problem. The root cause is not due to the Pandas version, but is due to the function from_factorised not having an implementation in the KNIME Python Script Extension code. The issue is specific to the PyArrow backend. I’ve raised a request to implement this function in the Feedback and Ideas section of the forum.