I’m a new Knime user (V 3.7.1) coming from a Python programming background. I have installed Python 3.5 using Anaconda on Windows 10. I am munging data using Python Script (1=>1). I have tested my script in Spyder by using an export of the data from the previous node and it works. I have replicated and executed the script within the Python Script node and it runs fine. I added a print statement at the end of my script to check, and my code generates the output I am looking for. My problem comes when I close the node and then try to execute it - it remains at 30% and eventually fails. Can anyone explain to why this is happening and how I can resolve it. Its incredibly frustrating
I’m sorry you’re having troubles with the Python Integration. Could you report the error message that is shown? Furthermore, we have a guide about the recommended python setup for the KNIME Python Integration. You could have a look at that, maybe you are missing some required packages (or maybe the versions are different).
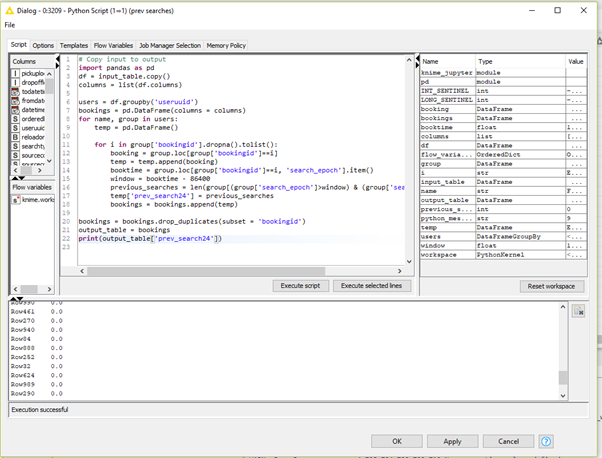
The error I get is “ERROR Python Script (1⇒1) 0:3209 Execute failed: reduction operation ‘argmin’ not allowed for this dtype”. It takes approximately 1 hour for the script to fail. I checked my python environment and have ensured that the installed libraries are the same versions as listed in the installation guide. All libraries installed through Anaconda. I’ve actually uninstalled and reinstalled Anaconda and created the environment exactly as per your guide. The python snippet executes within the node (see screenshot) .
I am using a temporary dataframe in the code but not using it as an output table. It was suggested that this could be causing an issue, so I used Python Script 1=>2, but I have exactly the same issue. Below is a screenshot from the log:
Could it bee that this has been implemented recently in Pandas 0.24 and KNIME currently does not support that version? That might explain why it does work in ‘pure’ Python but not KNIME. Still a little bit strange.
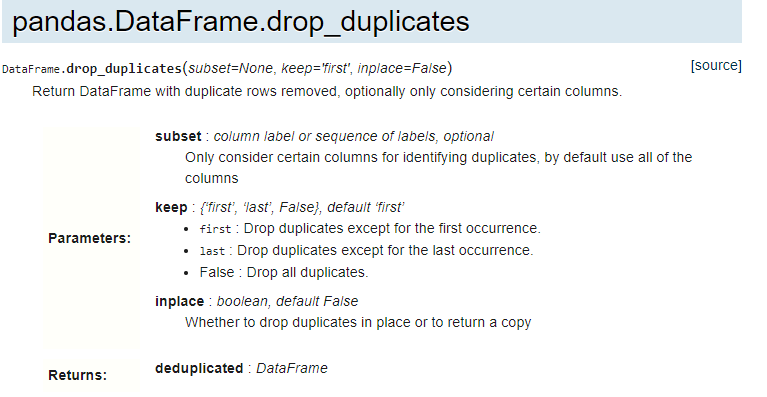
I think this could be the case since you have Pandas 0.23 which KNIME supports but the subset option was introduced in Pandas 0.24 so Python throws an error.
I stepped back the version of pandas I have installed to 0.23.0, removed the df.drop_duplicates(subset = x) line, and also simplified the loop by not looping through the groupby object but filtering the dataframe instead. I’m still getting the same error. I’ve tested the code using the py36_knime enviromment in Spyder and it runs without any issues:woman_shrugging:
Hi, I’ve prepared an anonymised sample of the data and tested this data again. I reduced the number of columns to just the ones being used in the Python snippet (from 53 cols down to 3), and reduced the number of rows (from 152k to 600). I’ve tested it again and it still thows “ERROR Python Script (1⇒1) 2:3209 Execute failed: reduction operation ‘argmin’ not allowed for this dtype”.
It executes normally in the py36_knime environment in Spyder. I’ve attached the workflow with data and Python codepython_error.knwf (17.4 KB)
The whole thing is very mysterious. I have converted the objects into categories which first does work but then when you try to export it KNIME seemingly wants to deal with missing and as of now Pandas data frame categories do not have the ability to add possible values in a generic way, although it is on the roadmap
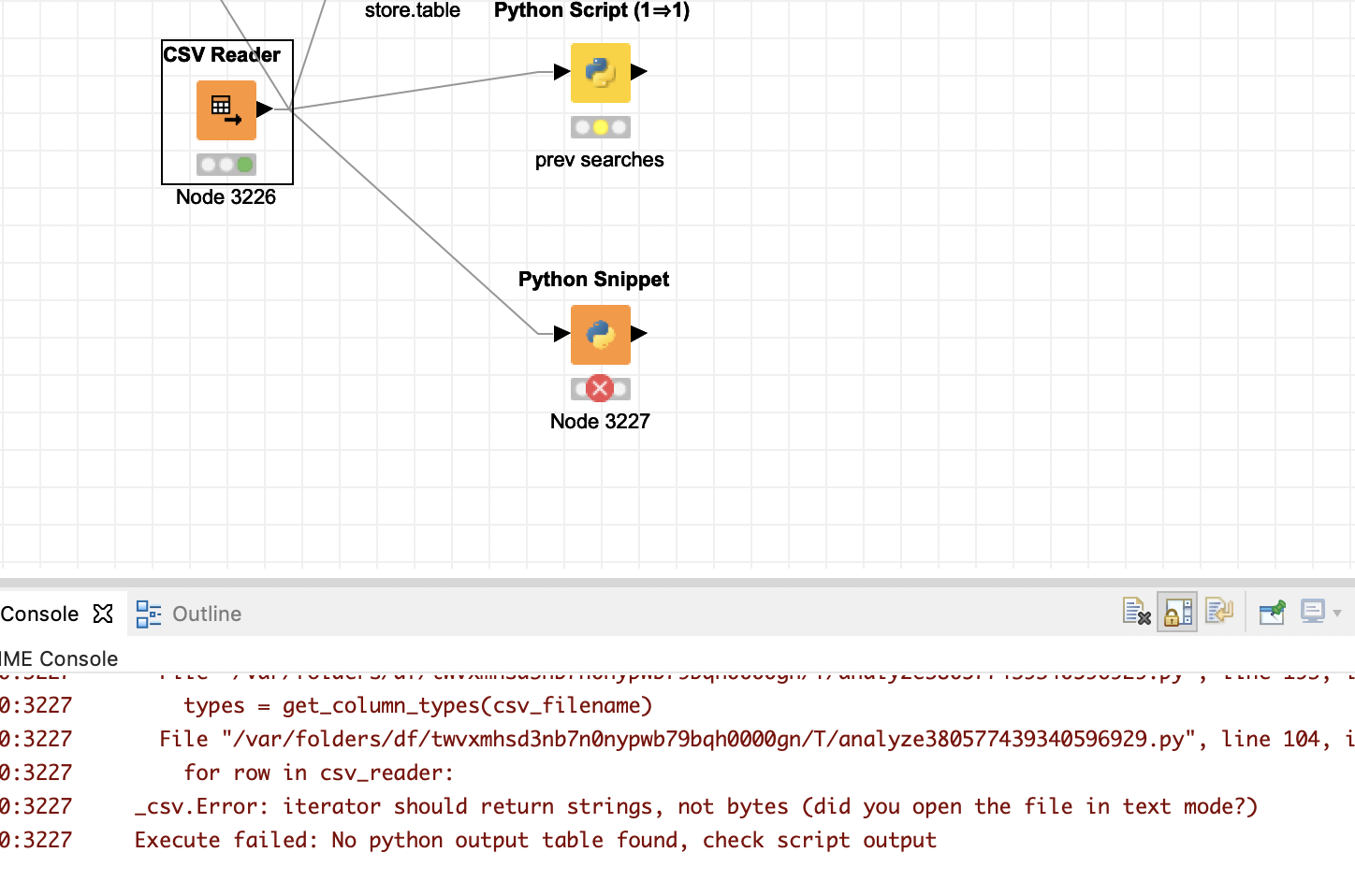
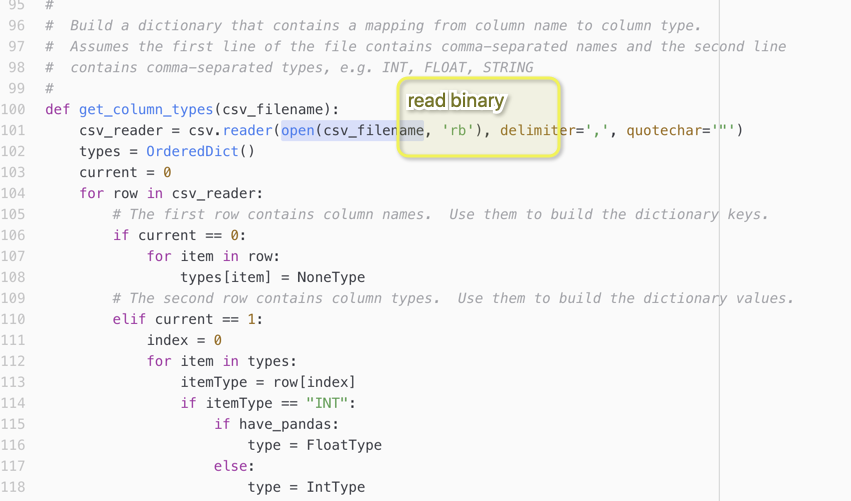
I then tried to use the community python node and there I encounter a strange problem. The node seems to export the KNIME table into CSV and stores the column names in the first row and the type in the second. Then it tries to read the type. But in this case it is interpreting the STRING entry as binary.
Maybe due to the “rb” (read binary) settings. Not sure if this is the best way to transfer data from KNIME to Python. I wonder if something similar happens to the Python node from KNIME itself and whether it is a problem of platform (I use MacOS on this one).
Going forward you could try to use another method of transferring data to Python, I wrote an article about that in an internal company forum, I will see if I can get an extract from that. Not really a satisfying thing. In general I do not like to use CSV to transfer data; I know it is easy and widespread but there are often problems with encodings (UTF-8, Ansi, Ascii, …) and preserving types.
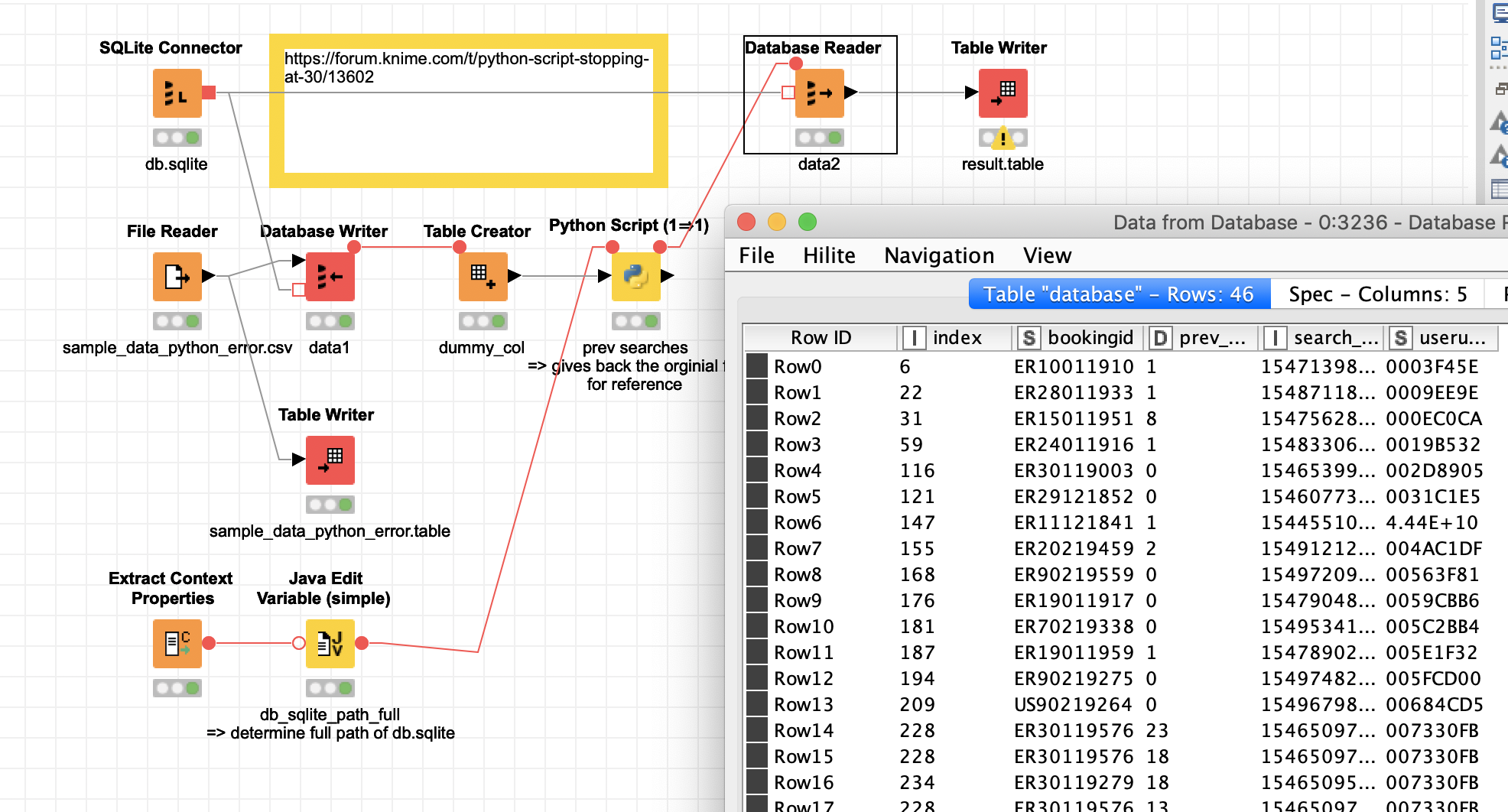
OK here is the thing with data transfer handled by SQLite. It is not very elegant and KNIME should be able to handle in and out data for Python on its own - but as it stands this should work.
to the end of your script resolves the problem (+ also readding the drop_duplicates line), at least on my machine (pandas 0.23.4).
Apparently, KNIME/pandas was not able to properly identify the data type of your “search_epoch” column. This is no problem in pure Python (which is why the script ran properly in Spyder and the Python Script node dialog) but becomes problematic once we try to transfer the data back to KNIME since we need to map it to KNIME’s internal data types, in this case “Number (Integer)”.
I’ll create a bug report for that to either improve the type identification on our side if possible, or at least improve the printed error message.
Thank you, that worked. It does still cause problems on my original larger dataframe from even though I changed any other columns with the same dtype to numeric. In the end, I filtered down to the relevant columns and joined the output back to the original table.
 .
.