I use a python node for some visualisations within a loop (many iterations like 70.000) . Even if the amount of data is quite small (less than 200 rows, 4 columns) the node stucks always a second at 30%.
Can it be that in every call the libraries are reloaded? Is this the root cause for the slow execution? Is there a way to preload all needed Python libraries at the beginning/start of a Workflow or Knime itself
from io import BytesIO
import seaborn as sns
import matplotlib.pyplot as plt
# Some numerical stuff
df = input_table
df["x"]= df.reset_index().index - 10
df["hue"] = df["hue"].astype(str)
# plotting
f, ax= plt.subplots(2,1, figsize=(8,6),sharex=True)
sns.scatterplot(data = df, x="x", y="y", hue= "hue", palette ="tab10", ax= ax[0])
ax[0].axvline(x = 0, color = 'k',lw=1, label = 'Meas Start', linestyle=":")
sns.lineplot(data = df, x="x", y="y_line" , palette ="tab10", ax= ax[1], label="Temperature")
plt.axvline(x = 0, color = 'k',lw=1, label = 'Meas Start', linestyle=":")
plt.legend()
# write it into the buffer
buffer = BytesIO()
plt.savefig(buffer, format=a'png')
# The output is the content of the buffer
output_image = buffer.getvalue()
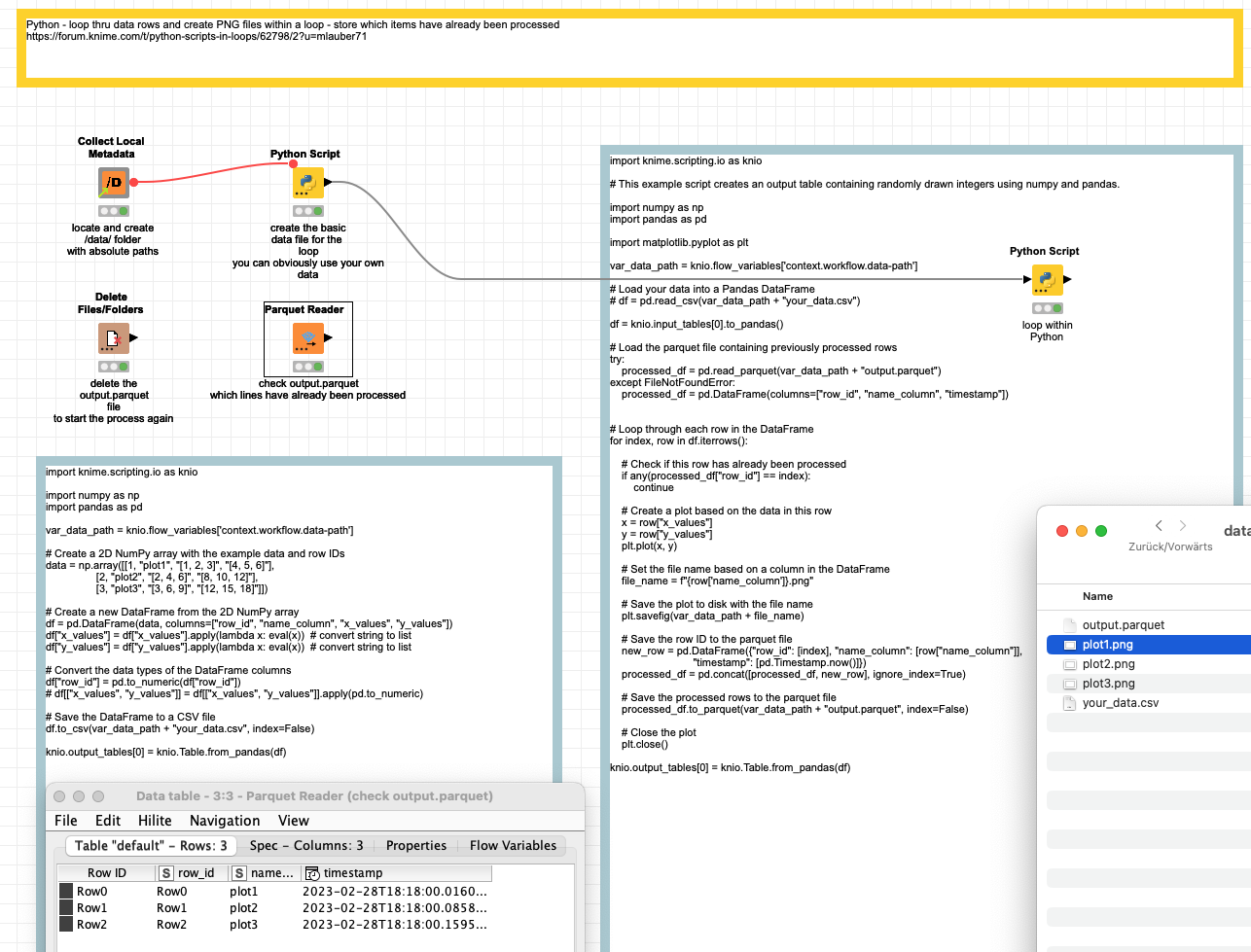
Other than that you might want to think about doing the loop within Python then the setup would only occur once. You would then export the PNG files directly from within Python:
Also: with such a large number of items it might make sense to store the ones you already have processed in a table so you can restart the process if something should happen.
import knime.scripting.io as knio
# This example script creates an output table containing randomly drawn integers using numpy and pandas.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
var_data_path = knio.flow_variables['context.workflow.data-path']
# Load your data into a Pandas DataFrame
# df = pd.read_csv(var_data_path + "your_data.csv")
df = knio.input_tables[0].to_pandas()
# Load the parquet file containing previously processed rows
try:
processed_df = pd.read_parquet(var_data_path + "output.parquet")
except FileNotFoundError:
processed_df = pd.DataFrame(columns=["row_id", "name_column", "timestamp"])
# Loop through each row in the DataFrame
for index, row in df.iterrows():
# Check if this row has already been processed
if any(processed_df["row_id"] == index):
continue
# Create a plot based on the data in this row
x = row["x_values"]
y = row["y_values"]
plt.plot(x, y)
# Set the file name based on a column in the DataFrame
file_name = f"{row['name_column']}.png"
# Save the plot to disk with the file name
plt.savefig(var_data_path + file_name)
# Save the row ID to the parquet file
new_row = pd.DataFrame({"row_id": [index], "name_column": [row["name_column"]],
"timestamp": [pd.Timestamp.now()]})
processed_df = pd.concat([processed_df, new_row], ignore_index=True)
# Save the processed rows to the parquet file
processed_df.to_parquet(var_data_path + "output.parquet", index=False)
# Close the plot
plt.close()
knio.output_tables[0] = knio.Table.from_pandas(df)