Hi,
I have a very basic question about how to make a prediction on the testing dataset. Currently, I have two CSV files which are the training dataset and the testing dataset. I have built the decision tree predictor and import the training dataset into it. But I have no idea how to predict data on the testing dataset? Where should I import the testing dataset in Knime?
I will appreciate it if you guys could help me! 

The answer to your question is simple but my question back at you is for what this exercise is? Is it to learn? Or for school? OK. But if it’s for work/something more serious I would advise to learn the basic “ML flow” or “ML pipeline” first. (What is cross-validation? What is train-test split? How do I evaluate a model? What exactly belongs to the model? -> the full pipline does including normalization, etc)
First, you must never normalize on the full data set like in your example but only on the training set because else you have data leakage.
Having said that and to actually answer your question you just add a second file reader to read in the test data, use the Normalizer (Apply) Node to normalize test data (Note: Normalizing is not needed for Tree-based algorithms) and then connect that to the Predictor node.
5 Likes
Thanks for your reply and actually it just for my interest. I found the Knime by accident and I think this application is quite useful and convenient. But it’s hard to find the lessons about Knime that are taught in my native language. And I saw most workflows are showed like below which is only one file reader, so I am quite confused about how to predict data on the testing data.

What’s more, when I connect the Normalizer (Apply) with the Decision Tree Predictor, the previous line between the partitioning and Decision Tree Predictor appeared. Could you please where I did wrong? Thanks! 
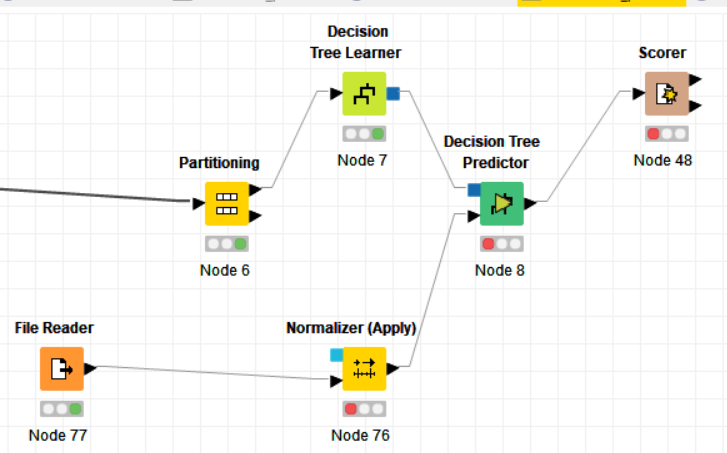
Why do you have a partiioning node?
You want to partition at the beginning use nodes like Normalizer etc on the training set and connect the normalizer to the normalizer apply to apply the same transformations on your test or new dataset you want to predict on
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.