Hi, I have a question about the ‘Memory Policy’ options used by each node as below.
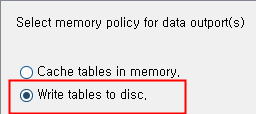
When executing a node, the default value of the memory policy option is ‘Cache tables in memory’.
However, if this option is used, it is difficult to process large amounts of tasks in a limited personal PC memory using nodes.
For this reason, the memory policy option is set to ‘Write tables to disc’ and the node is executed using the resources remaining on the hard disk.
At this time, my questions are as follows.
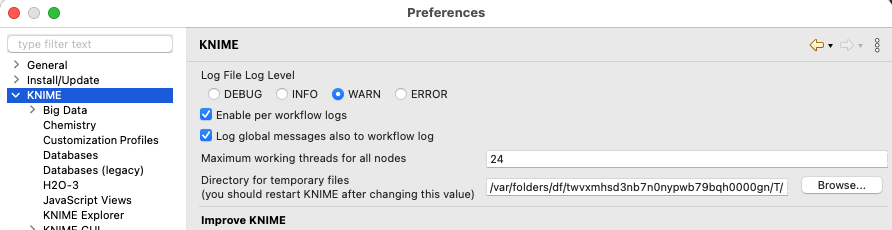
Based on the Windows environment, which path on the hard disk creates a temporary file when the node is executed?
If you know anyone, please answer politely.
PS. The node operation I am trying to execute is as follows.
After creating 25 million rows data (with 1500 columns) using the ‘Data Generator’ node, I’ll try to store the results in HDFS using the ‘Parquet Writer’ node.
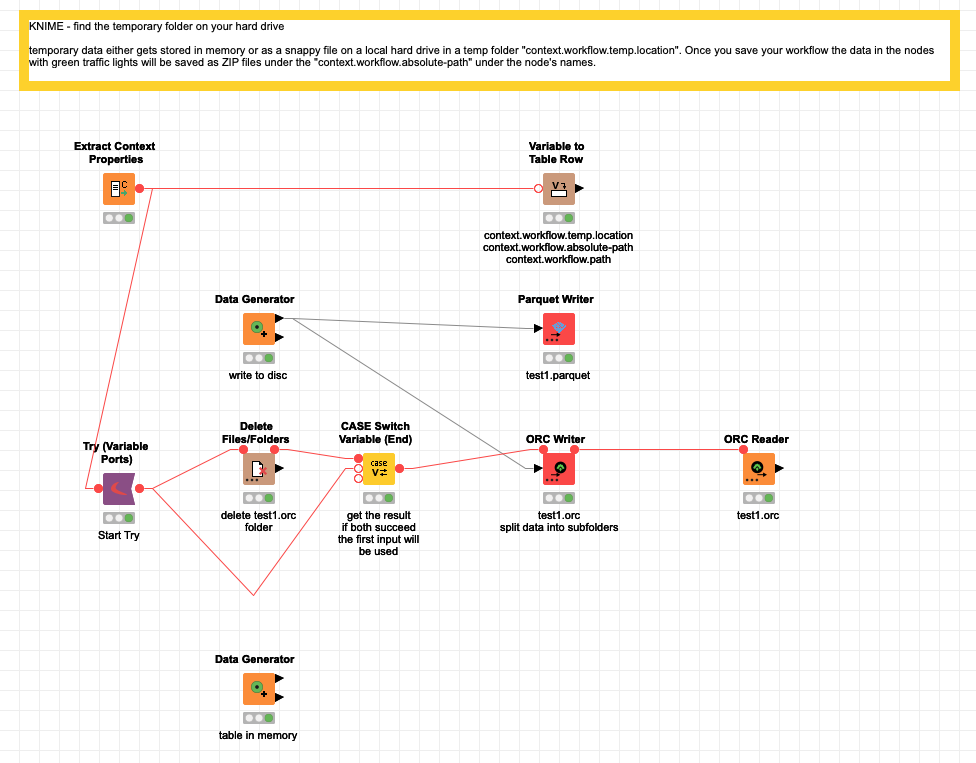
The data will be stored in a temporary location you could see by using the Extract Context Properties node under the value “context.workflow.temp.location”.
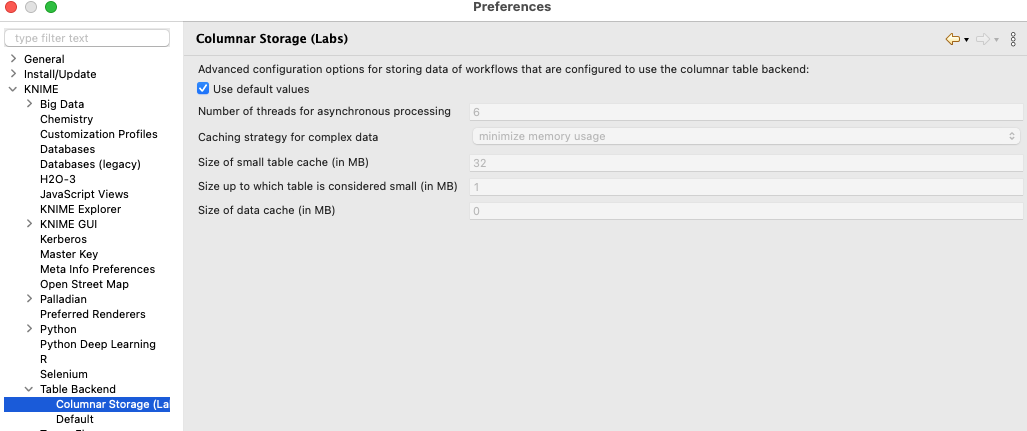
Also if you must you could tweak the internal storage of the data, as well as use the (new and still experimental) columnar storage in Apache Parquet. But You should be careful to do that.
A small workflow to test the settings yourself and play with parquet and ORC files. ORC offers you a broad variety how to store the files and still use them as a ‘single’ file if you need to.
And since we are at it ORC and Parquet files can be used together with big data environment. You might upload the single ORC tables in chunks to the HDFS and then tell Hive (or impala) to use an EXTERNAL TABLE to bring them back together.
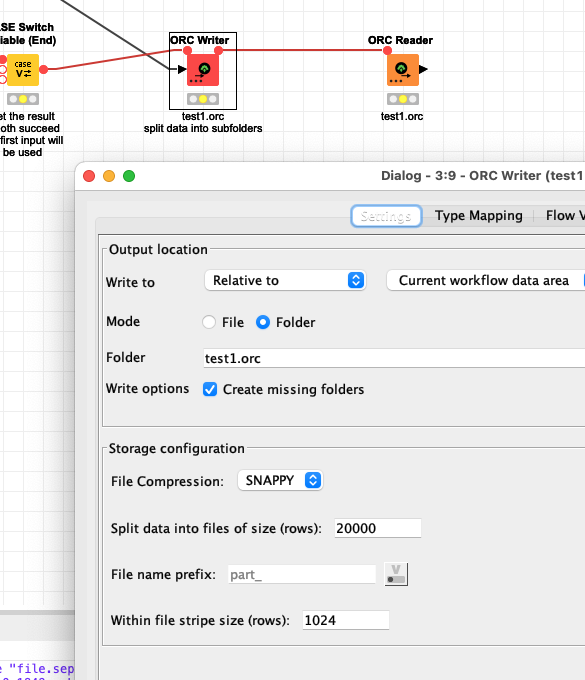
 ORC and Parquet files can be used together with big data environment. You might upload the single ORC tables in chunks to the HDFS and then tell Hive (or impala) to use an EXTERNAL TABLE to bring them back together.
ORC and Parquet files can be used together with big data environment. You might upload the single ORC tables in chunks to the HDFS and then tell Hive (or impala) to use an EXTERNAL TABLE to bring them back together.