@pigret113 welcome to the KNIME forum.
The data will be stored in a temporary location you could see by using the Extract Context Properties node under the value “context.workflow.temp.location”.
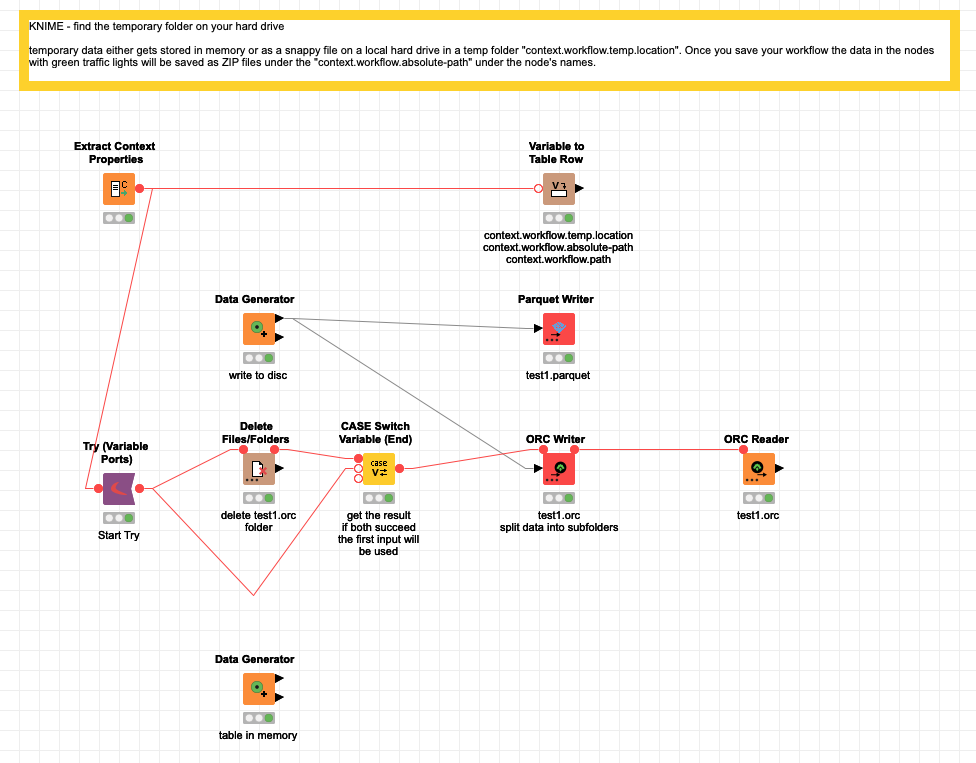
You could actually change that temporary location of you wish to do so:
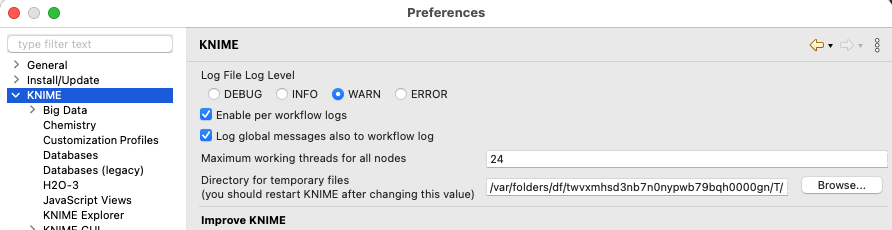
Also if you must you could tweak the internal storage of the data, as well as use the (new and still experimental) columnar storage in Apache Parquet. But You should be careful to do that.
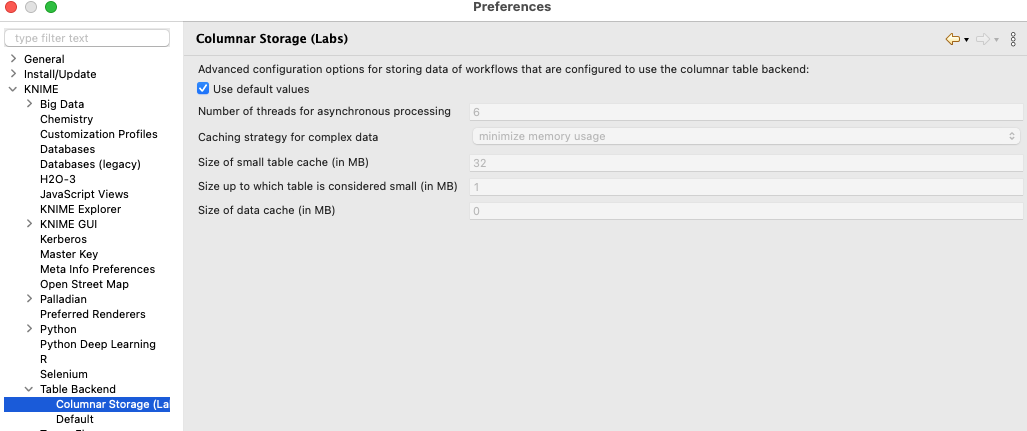
A small workflow to test the settings yourself and play with parquet and ORC files. ORC offers you a broad variety how to store the files and still use them as a ‘single’ file if you need to.
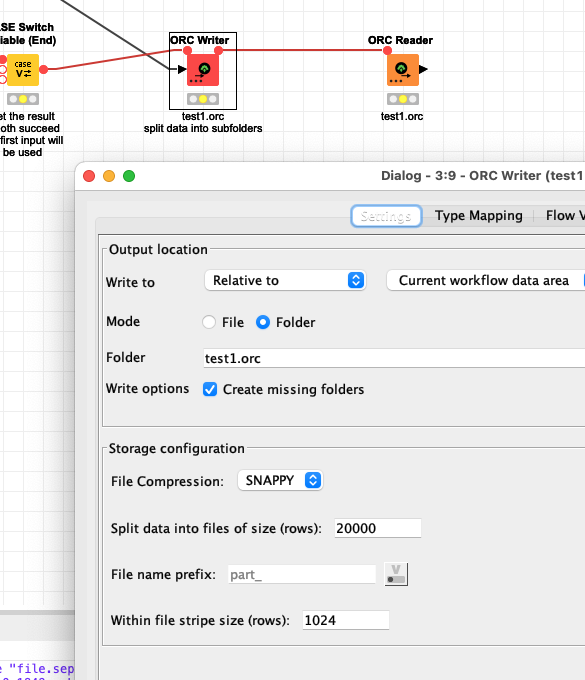
And since we are at it  ORC and Parquet files can be used together with big data environment. You might upload the single ORC tables in chunks to the HDFS and then tell Hive (or impala) to use an EXTERNAL TABLE to bring them back together.
ORC and Parquet files can be used together with big data environment. You might upload the single ORC tables in chunks to the HDFS and then tell Hive (or impala) to use an EXTERNAL TABLE to bring them back together.