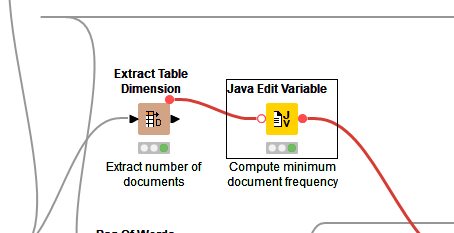
The extract table dimension just gives you the number of rows and columns in a particular table. The Java edit variable uses this info to run a script on it to do a simple calculation that is essentially:
numRows / 100
This value is passed as a flow variable to filter out any terms that have less than the value in the variable and are considered insignificant. All those 2 do is calculate the cutoff point for terms based on occurrence
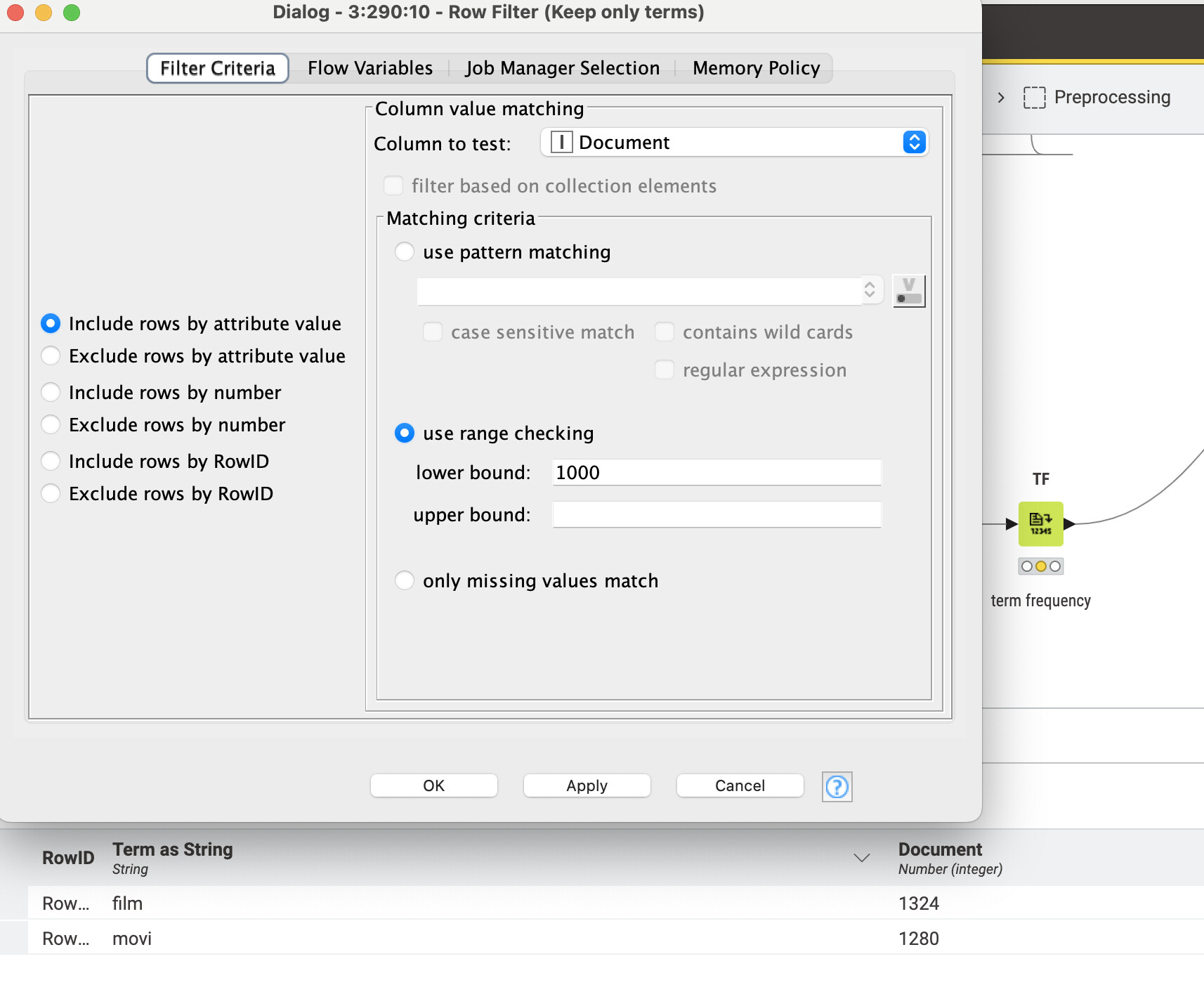
If you look at the ‘Row Filter’ node that uses the flow variable passed from those 2, it uses it in the ‘lower bound’ field in range checking. Although there is a 20 there, if for example you put 1000, the output will be the same as it is defaulting the lower bound to the value being passed by the flow variable (which is 20). It may look confusing, but the node is not actually using the number in the lower bound unless you disconnect the flow variable that overwrites the value.
If we disconnect that flow variable and keep the lower bound of 1000, we only get 2 rows that appear in the document more than 1000 times (versus the original 1499 rows):