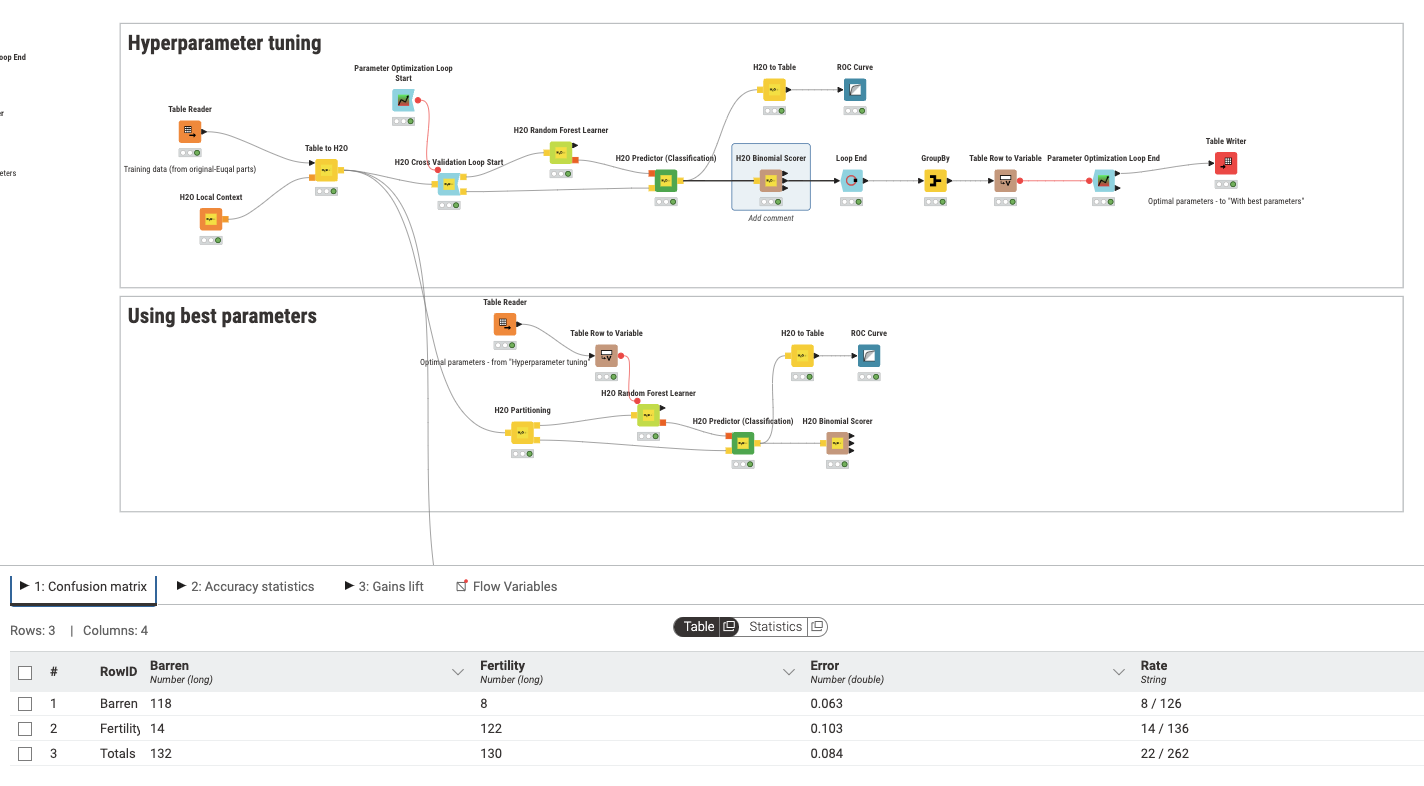
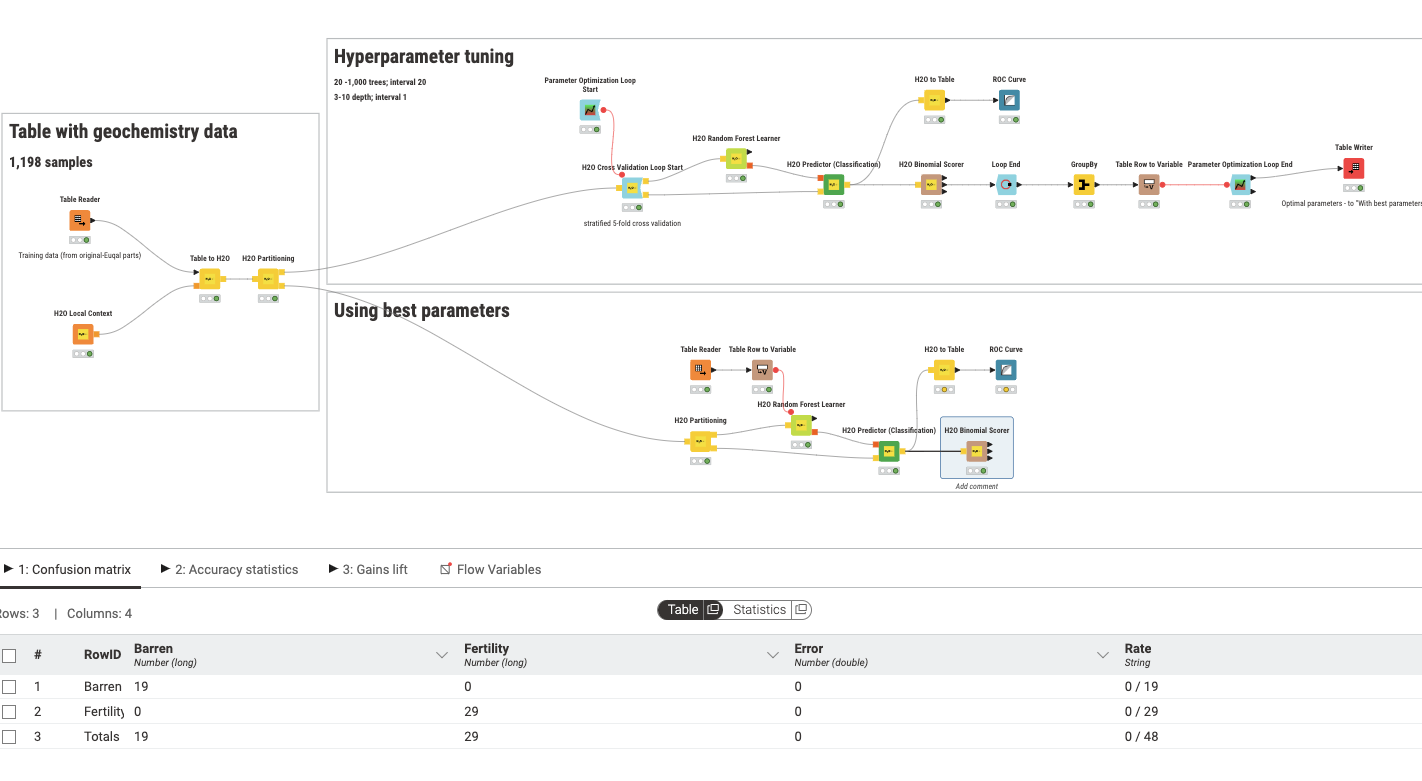
I have question related to the confusion matrix based on selecting the best parameter. The first image is the entire workflow to date which shows a phase by which I conduct a grid search on hyper parameters with the goal of using the best return for the final model. As shown below, the best hyper parameter combination gave me the following confusion matrix together with a 92% accuracy and other stellar classification-based statistics
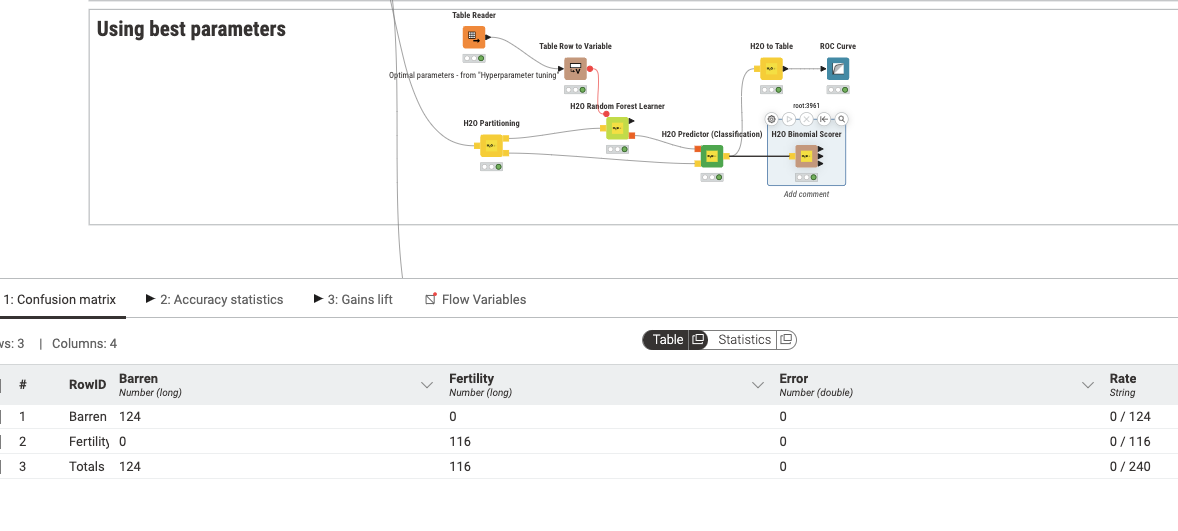
However, when I go to use the chosen parameters established on the “Using best parameters” phase to the “Using best parameters” phase, I get the following confusion matrix together with a suspect 100% accuracy, rather than something that resembles the statistics established in the first step. I am optimizing to maximize accuracy.
Im wondering what might be the case and how I can fix this issue.
Thank you again everyone for helping me learn the ropes related to data science and machine learning. I look forward to continue this process. You all have been great thus far!
Now that I have thought this further. . .is it posisble that the reason regarding the 100% accuracy is that the algorithm simply memorized things the second time?
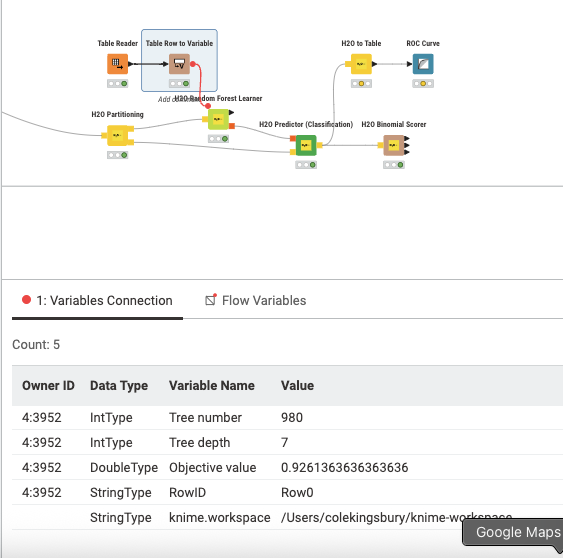
Unfortunately After I did some tweaking, I still have the issue of the holdout test set returning 100% accuracy even after I reconfigured the partitioning. I still don’t know why the data that got partitioned into the bottom “test” workflow returns a 100% accuracy.
If you are unsure you can use a hyperparameter set with very low accuracy. Just to test it.
On the other hand, your test dataset has just a small size. Maybe that’s the cause for that suspicous high accuracy.
Hi @Cole_Kingsbury , any chance (if possible) to share us sample data and flow? At first, couple of things come to my mind:
Data Leakage: Test data might have been exposed to the model during training, which would result in overly optimistic performance (e.g., 100% accuracy).
Incorrect Split: If the data is time-series, random splitting could allow the model to “see” future data, leading to inaccurate results. For time-series, the data should be split chronologically.
Random Split: If the split is random, especially with imbalanced data, the training and test sets may contain similar examples, whick makes model to perform unusually well.
If you need further assistance or clarification, feel free to reach out. Best of luck with the troubleshooting, and I’m sure you’ll have it sorted out soon.
I believe I solved my problem. . . . I found another data set consisting of 4,200 instances which are well balanced between the two classes and configured my workflow in such a way that normalization happens after the partition and also configured the flow variables corresponding to the best parameters as determined by parametric tuning in the training/validation set to the testing set. The end result is that the accuracy of the training/validation set hovered between 92 and 93% with the test accuracy consistently about 2 points lower along with precision, recall and ROC(AUC) being greater than 0.9.
Thank you again for your assistance and patience during this time period. Much appreciated!