I’m trying to better understand analyzing reviews using KNIME and text processing. I found this blog under ML101, and have found it quite helpful:
How to Evaluate CX with Stars and Reviews | KNIME
However, there are certain decisions in the blog that aren’t self evident to me.
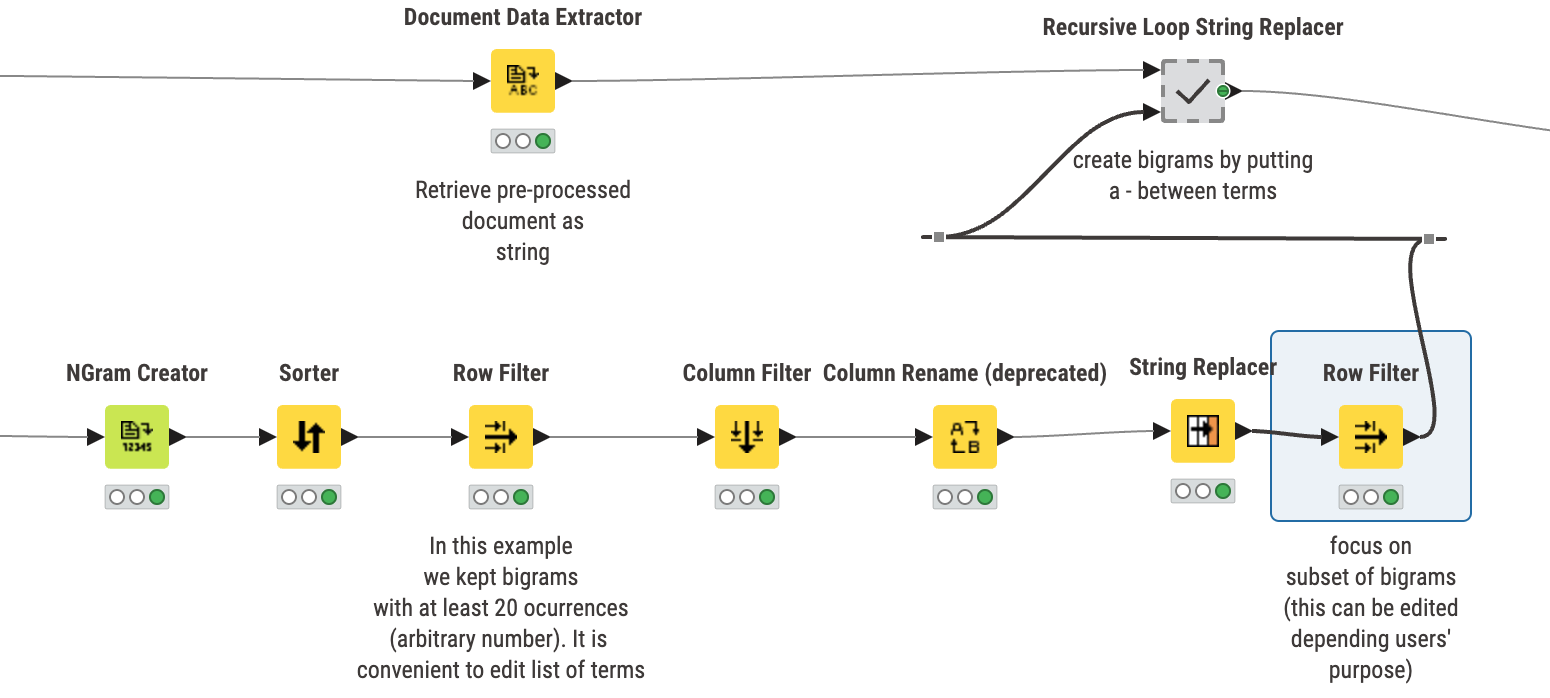
- I understand that using n-grams provide more information. I expanded all of the components to look into each one - and I converted the bi-gram into a tri-gram, which was extremely helpful in seeing how many reviews were associated with customer service.
- I also see that these n-grams are being used downstream to filter to the top 20 (arbitrary number per their notes), and that text in the reviews are replaced with the hyphenated bi-gram - but where is this being used? Does the topic modeler see these bi-grams as a single entity for topic discovery, vs. looking for singular words?
I think I know this answer, but just wanted to confirm that the point of extracting the bi or tri gram is that the topic modeler sees those words together to provide a more meaningful topic representation (ie, combining “terrible-customer-service” vs. “excellent-customer-service” would yield better topic identification vs. single terms of “terrible” “excellent” “customer” “service”).
- In one of the nodes, the filter is to remove the following in reg-ex:
(staff friend|friend helpful|staff helpful|clean comfortable|park garage). I’m not understanding why these are being removed? Also, they are removing words related to Philadelphia, philly, etc. I assume because we are comparing only two hotels in same area, so those don’t provide useful information, but why remove the friendly or helpful staff?).
I have reviews that call out specific reps positively, it would make sense to leave them in becuase if i have a crew of customer service, i would want to see how many reviews refer to friendly, or even specific names? we could then replicate their style to others?
Anyway, there isn’t a place to comment on the blog, just wanting some clarification on why these terms would be filtered out.
thank you!