As you can see I am using 2 Snowball Stemmer Nodes: The first one for German words and the second one for English words.
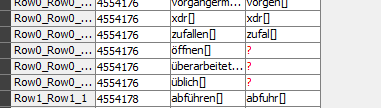
My first problem is that one of the stemmers probably deletes words that start with german umlaute (ä,ü,ö). As you can see here:
The left column in this picture contains the Bag of Words of my documents before the stemming, the right column contains the bag words after stemming. As you can see something like “öffnen” is missing.
My second problem is that the stemmer deletes words from documentsmy documents:
Before the stemming my Bag of Words contains 5122 rows.
After the stemming my BoW contains 4832 rows:
I need to match my BoW Lists, becaus eafter the preprocessing of my data I want to use a LDA.
I want to tell the LDA that he has to macth the stemmed words I am feeding with unstemmed words.
I tried to recreate the issue with umlauts but was unsuccessful - in my example Übermorgen was processed to Übermorg with the German stemmer, and basically left alone with the English stemmer.
Could you possibly upload your workflow with some sample data so that we might investigate further?
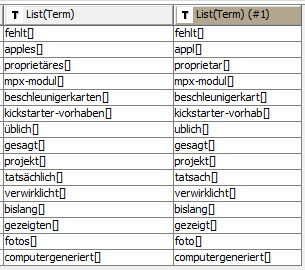
After running your workflow with the sentence provided, I’m still unable to reproduce the problem. The outputs of both Bags of Words have 15 terms, and the joined table shows that the word with the leading umlaut, üblich, is not being dropped:
Is there possibly some issue with the join logic on your full dataset that would cause missing values to be returned? Or perhaps this is a character encoding problem (UTF-8?) on your local machine? Can you tell me what version of KNIME you are using, and on what OS?
I also tried to load the Data from file I uploaded.
When I do this I dont get the error and get the same result as yours.
It seems to be a problem with the Database I using.
I am loading my data from SQL Server via the regular database connector and database reader (I am not using the SQL Server Reader).
Are there any known errors when using Knime with SQL Server?
Not that I know of. It seems like perhaps this might have something to do with encoding when transferring data from the database to KNIME, but I’m speculating a bit.
Are you using the legacy Database nodes to connect to your data, or the newer DB nodes?
Let me ask internally to see if I can get any additional ideas about what might be going on.
(EDIT: So far, the devs have been unable to replicate using the Microsoft SQL Server connector node)